-
-
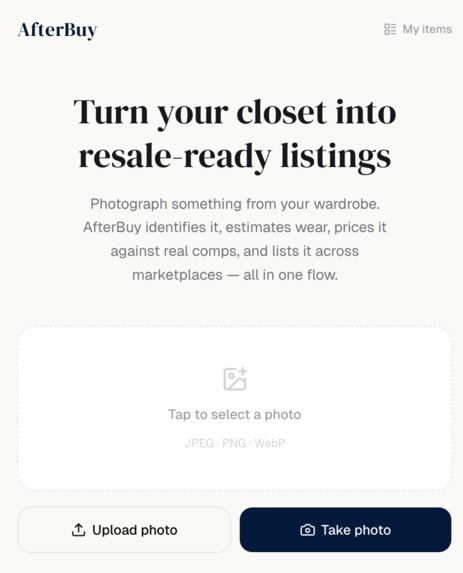
Home Page
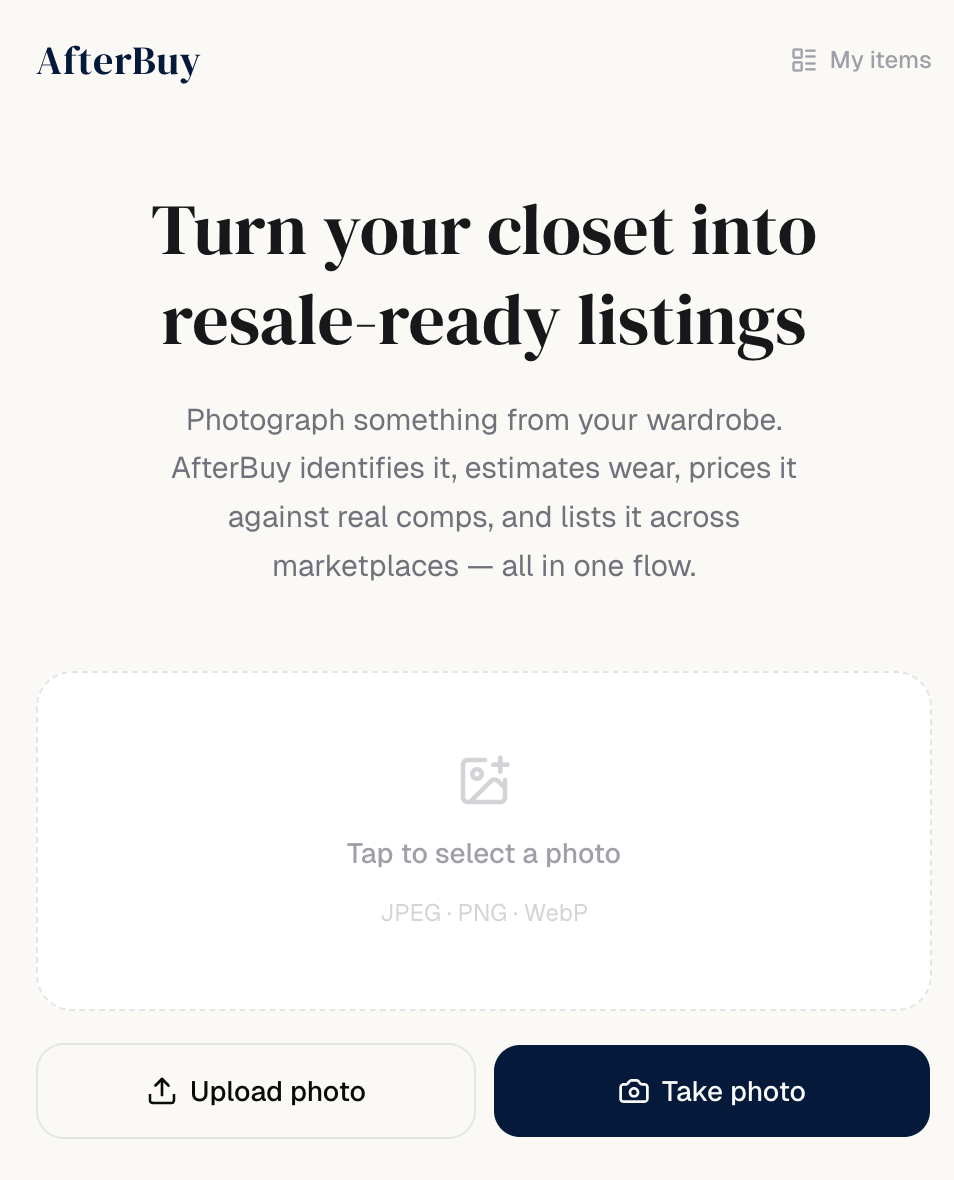
Inspiration
Most AI products optimize the moment before you buy something. Price alerts, recommendation engines, shopping assistants, they all live upstream of checkout.
I kept thinking about what happens after. You own something. Maybe you've worn it a few times, maybe it's been sitting in your closet for a year. At some point you decide you're done with it, but the path from "I should sell this" to "this is listed and ready to go" is surprisingly painful. You have to figure out what the item is called, research what it's selling for, write a listing that doesn't sound terrible, photograph it properly, and then repeat that process for every platform.
AfterBuy is the layer that was missing. Not a marketplace. Not a chatbot. The post-purchase intelligence layer that turns ownership into action.
What it does
AfterBuy is a mobile-first AI wardrobe resale agent. The full flow:
- Upload or photograph a wardrobe item you own
- Item identification — GPT-4o extracts brand, category, type, color, and condition from the image
- Visible wear assessment — the model inspects category-relevant wear zones (cuffs, collar, toe box, corners, etc.) and returns a structured wear report: wear level, confidence score, specific signals per zone, and a conservative pricing adjustment factor
- Market comparables — SerpApi searches Google Shopping for real comparable listings, which are normalized, scored for similarity, and persisted
- Wear-aware valuation — a heuristic engine computes a low/mid/high resale range using similarity-weighted comp prices, a condition multiplier, and a conservative wear adjustment derived from image evidence. The adjustment is scaled by wear confidence and capped to avoid over-penalizing uncertain assessments
- Listing generation — GPT-4o generates a factual, marketplace-ready title, description, and condition note that honestly reflects the visible wear shown in photos. Structured item specifics and a category-aware photo checklist are built deterministically
- Review and edit — the user can revise any field before publishing
- Multi-platform distribution — select from eBay, Poshmark, Depop, Facebook Marketplace and route the listing
- Inventory tracking — a lightweight dashboard tracks every item's resale state
How I built it
Frontend: Next.js, TypeScript, Tailwind CSS v4, and shadcn/ui. Mobile-first throughout. Server components fetch assembled item state. Client components handle upload, editing, and publish interactions.
Backend: FastAPI (Python 3.11), organized into thin route handlers and service modules:
extraction_service— OpenAI GPT-4o vision with structured output via Pydanticparse()valuation_service— IQR outlier removal, similarity-weighted pricing, wear-adjusted heuristiclisting_service— prompt construction with wear context, deterministic item specifics buildermarket_data_service— SerpApi integration with multi-tier search fallbackitem_service— Supabase persistence layer for all core recordspublication_service— clearly labeled multi-market publish flow
Storage and DB: Supabase — Postgres for all structured records (items, comps, valuations, listings, publications), Supabase Storage for uploaded images.
AI: OpenAI GPT-4o for both vision extraction and listing generation. I used client.beta.chat.completions.parse() with Pydantic response models throughout for structured, reliable output.
Market data: SerpApi (Google Shopping) for comparable listing retrieval.
The wear assessment was designed around a key constraint: the model should only describe what is visibly supported by the image. I built a category-aware inspection profile system so the prompt tells GPT-4o exactly which zones to check for a jacket versus a sneaker versus a bag. Each wear signal includes a zone, signal type, severity, and confidence score.
Challenges I ran into
Structured output with nested models. OpenAI's parse() endpoint uses strict JSON schema mode. Getting reliable structured output for nested Pydantic models, especially the WearAssessment containing a list[WearSignal] required careful model design and prompt engineering to ensure the model always returned a valid, conservative wear object even for non-wardrobe items.
Wear conservatism vs. usefulness. Getting the model to be useful on clear images while staying honest on ambiguous ones is hard. Too aggressive and it penalizes clean items. Too conservative and it adds no value. The confidence-scaled penalty formula above was the key design decision that made this feel right.
Supabase schema cache. Adding new columns to a live table requires reloading the PostgREST schema cache before the API can write to them. I hit this mid-build when adding item_specifics_json and photo_checklist_json to the listings table. The graceful fix was to degrade cleanly (return null) rather than crash, then restore the writes after the migration ran.
Listing realism. Generic AI-generated listing copy sounds immediately synthetic. Getting GPT-4o to produce copy that reads like a careful human seller — honest, concise, specific without fabricating — required significant prompt iteration, explicit anti-patterns ("no invented measurements", "no hype language"), and the constraint that condition language must be phrased as visible from provided photos.
Mobile-first on a web stack. Camera capture from a browser requires HTTPS or localhost, which makes phone testing during development awkward. I structured the app so it deploys cleanly to Vercel for real phone testing without needing a local tunnel.
Accomplishments that I am proud of
- A complete, end-to-end golden path that actually works: photo to listing to distribution in one flow, on a phone
- A wear assessment layer that is slightly conservative and image-grounded. It degrades gracefully on bad inputs rather than hallucinating
- The valuation engine is fully transparent and reviewable. Every computation step is independently legible code, not a black box
What I learned
- Structured output design matters more than prompt length. A well-designed Pydantic schema constrains the model's output space more reliably than verbose instructions. The
WearSignalmodel with explicitseverityandconfidencefields produces far more consistent output than asking for free-form wear descriptions. - Comp quality determines valuation quality more than the algorithm. A sophisticated valuation engine on bad comps produces bad valuations. The multi-tier SerpApi search strategy with IQR outlier removal mattered far more than any weighted averaging refinement.
- Golden path first. Every architectural decision that kept the core upload → result flow fast and reliable paid off.
What's next for AfterBuy
- Real marketplace publishing — OAuth flows for eBay, Poshmark, Facebook Marketplace, and Depop seller accounts, turning the current mock publish into real listings
- Wardrobe management — track what you own, when you bought it, and when it crossed into resale territory based on market movement
- Multi-photo wear assessment — right now I analyze a single image. Multiple photos from different angles would dramatically improve wear confidence for complex items
- Revaluation alerts — periodically re-check comp prices for items sitting in inventory and surface when the market has shifted
- Size inference — attempt to estimate sizing from brand + category context to improve listing specifics for apparel
Built With
- fastapi
- next.js
- openai
- postgressql
- python
- serpapi
- shadcn
- supabase
- tailwind
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.