-
-
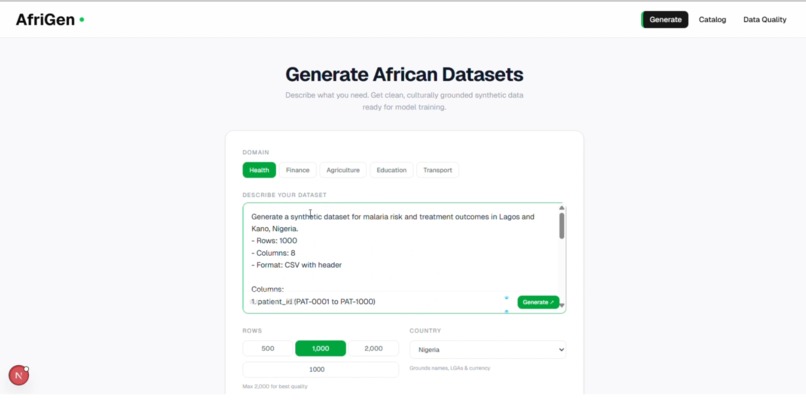
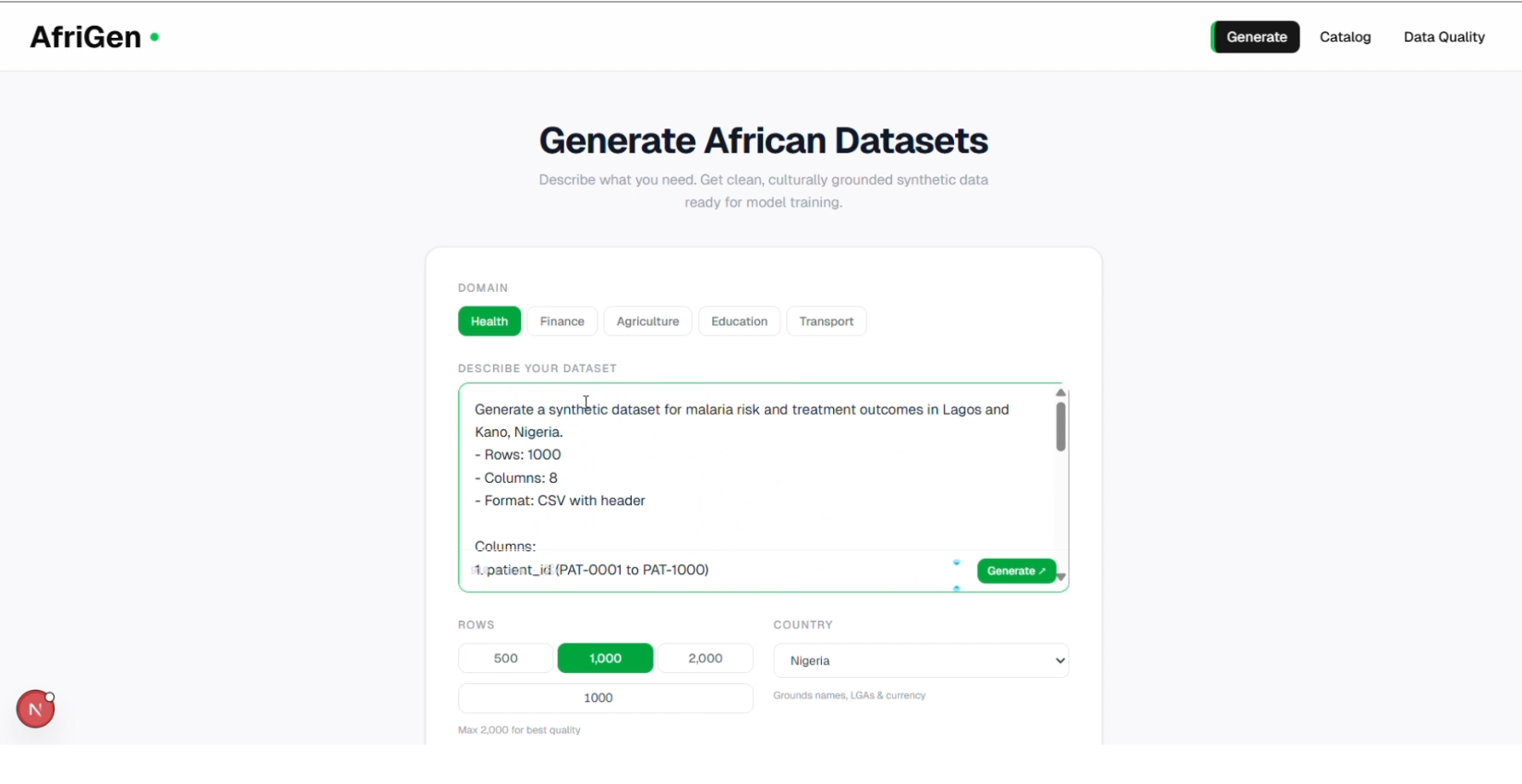
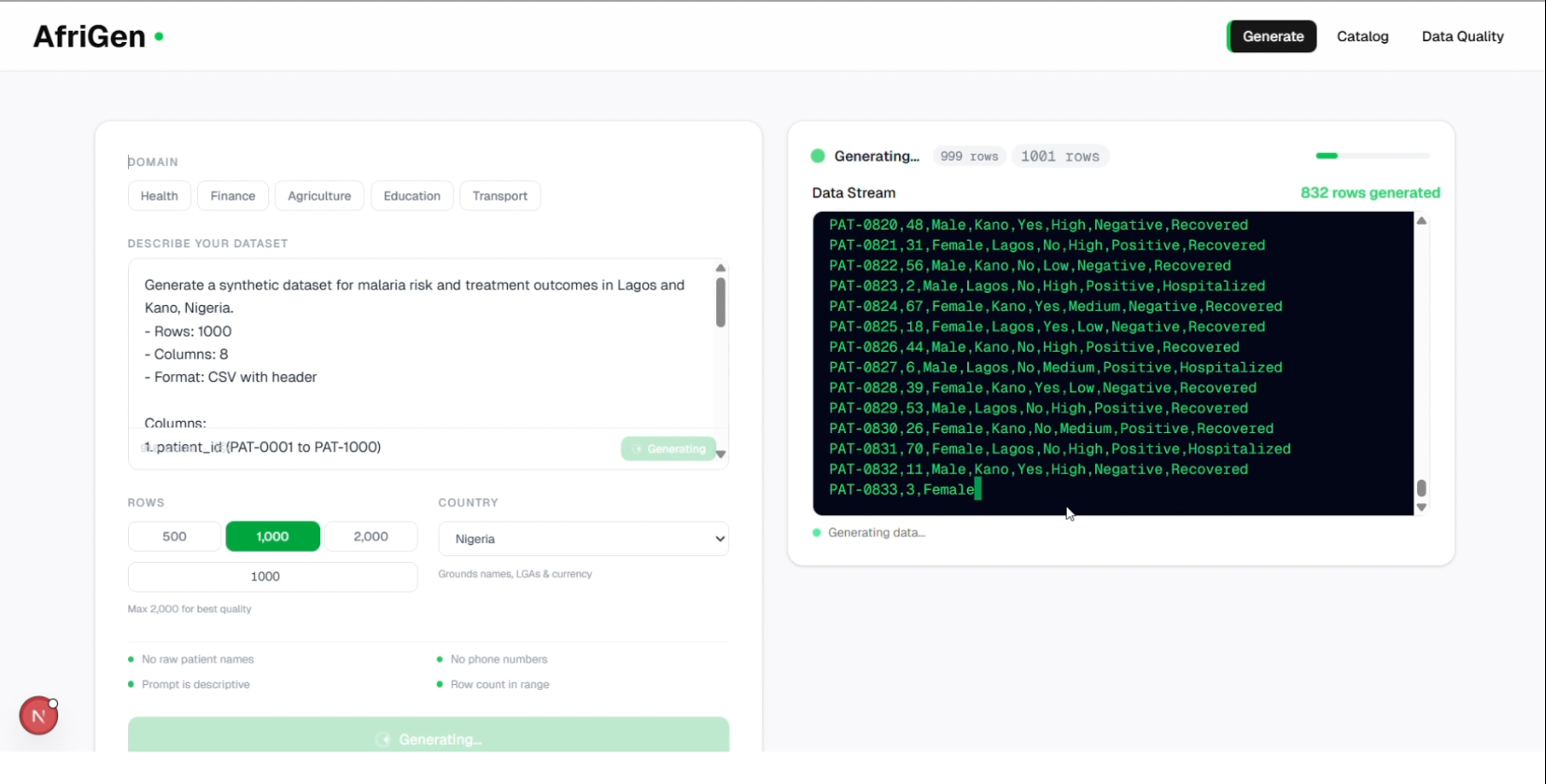
Type in your prompt for the dataset you want to generate
-
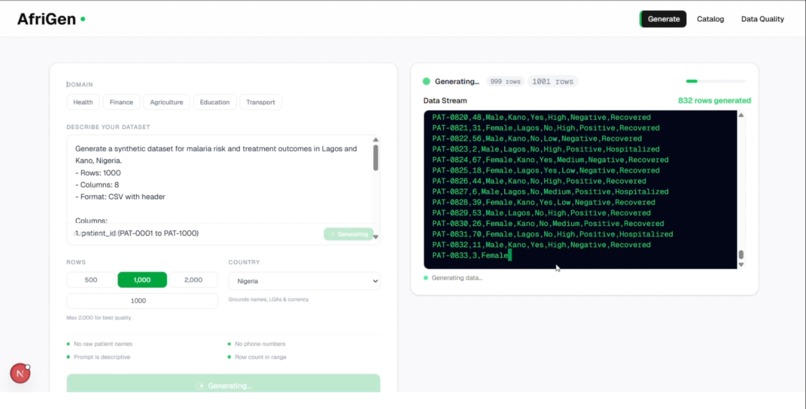
Watch the dataset being generated live
-
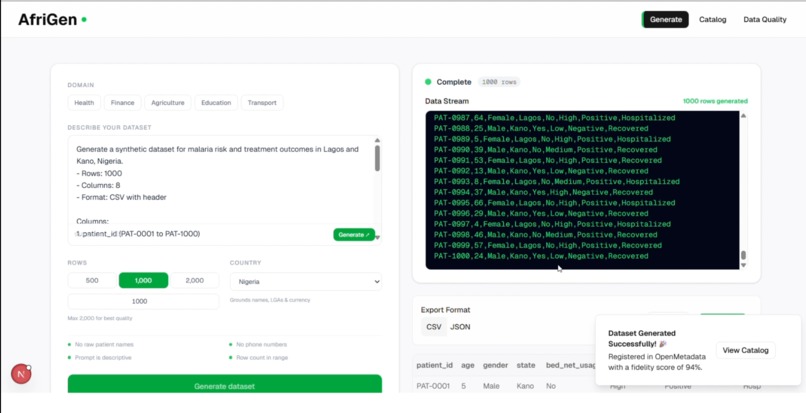
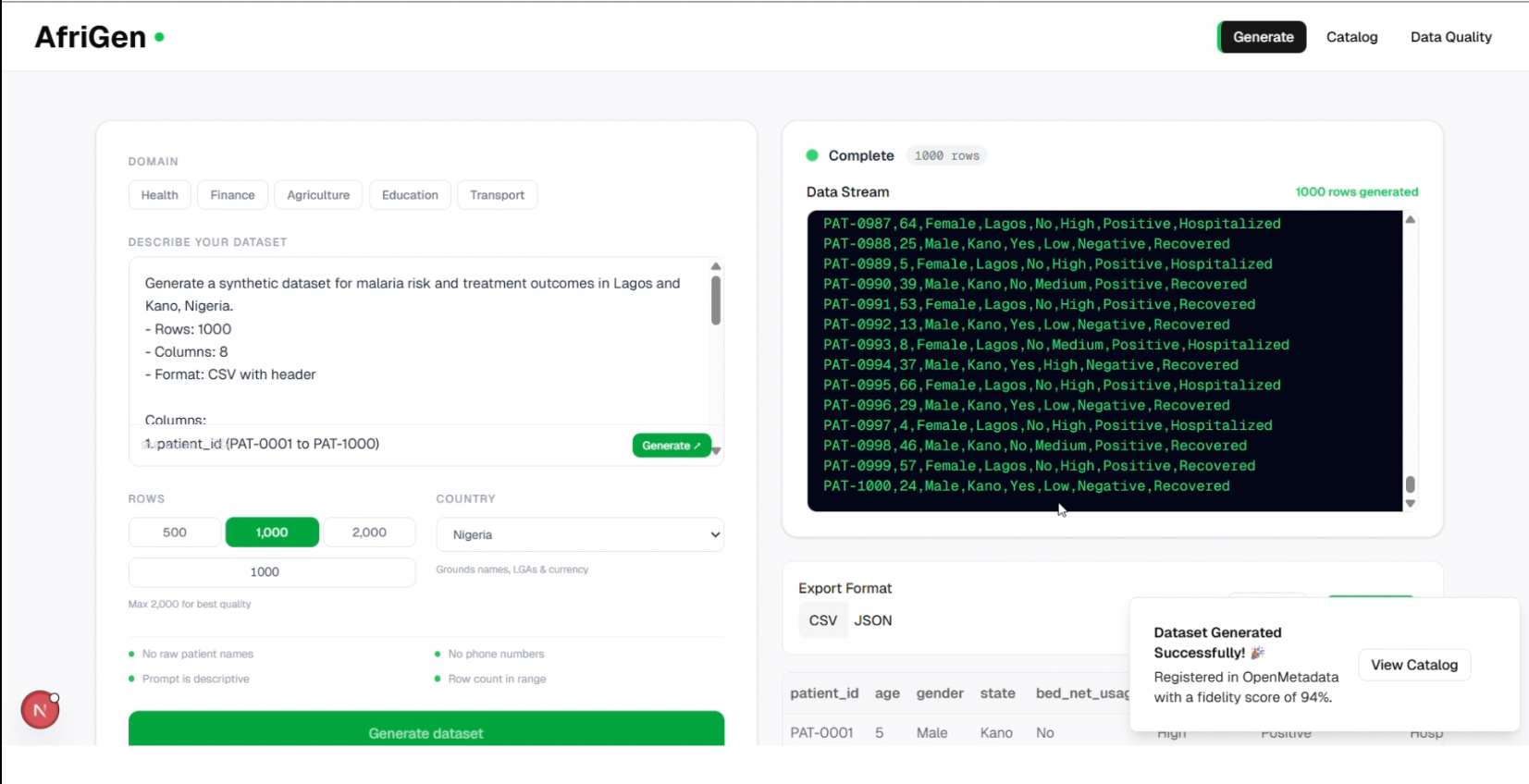
Dataset ready for download with fidelity score
-
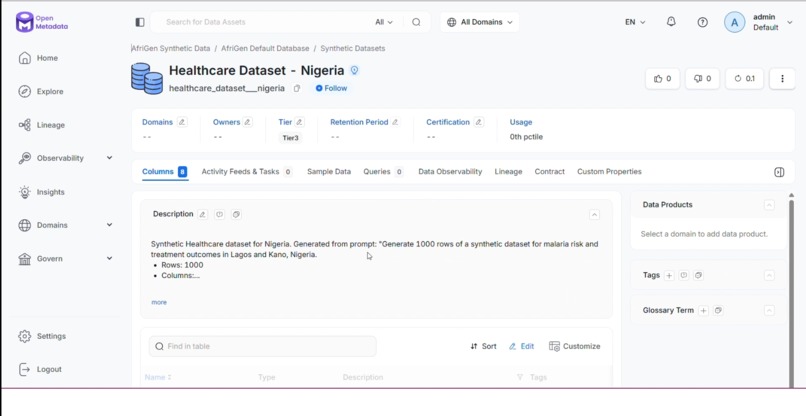
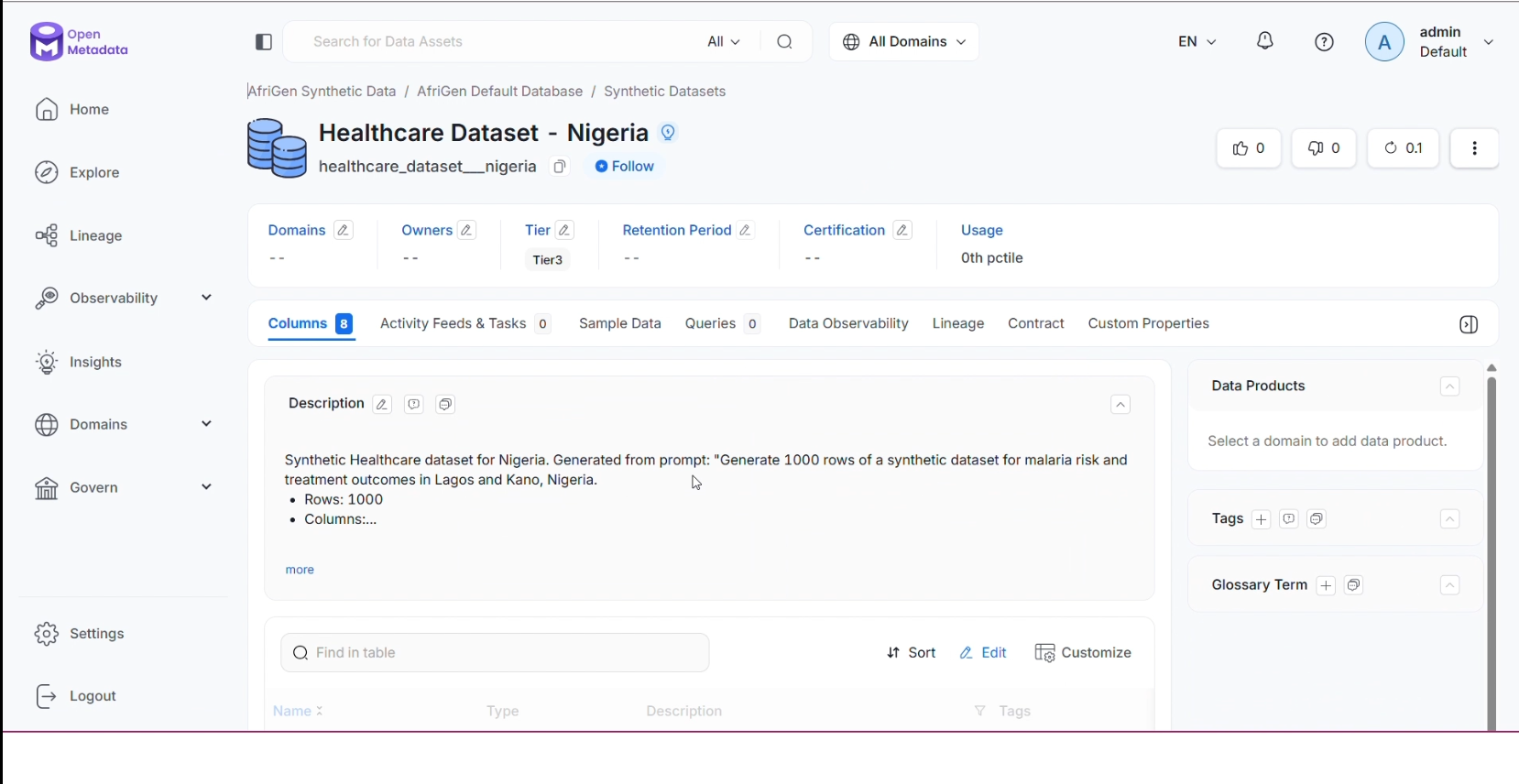
Dataset appear instantly in Openmetadata
-
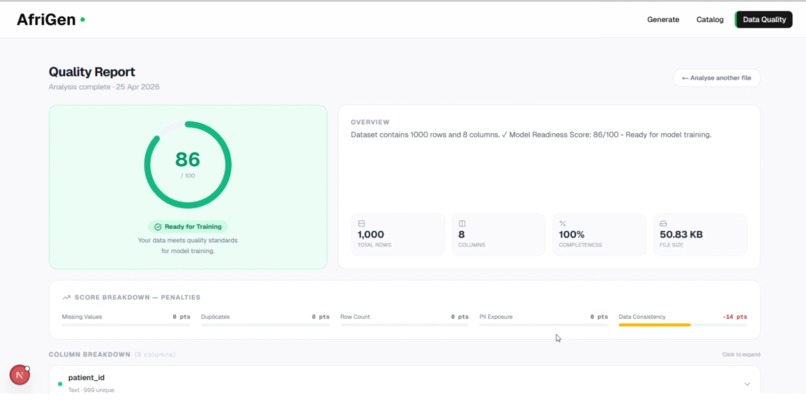
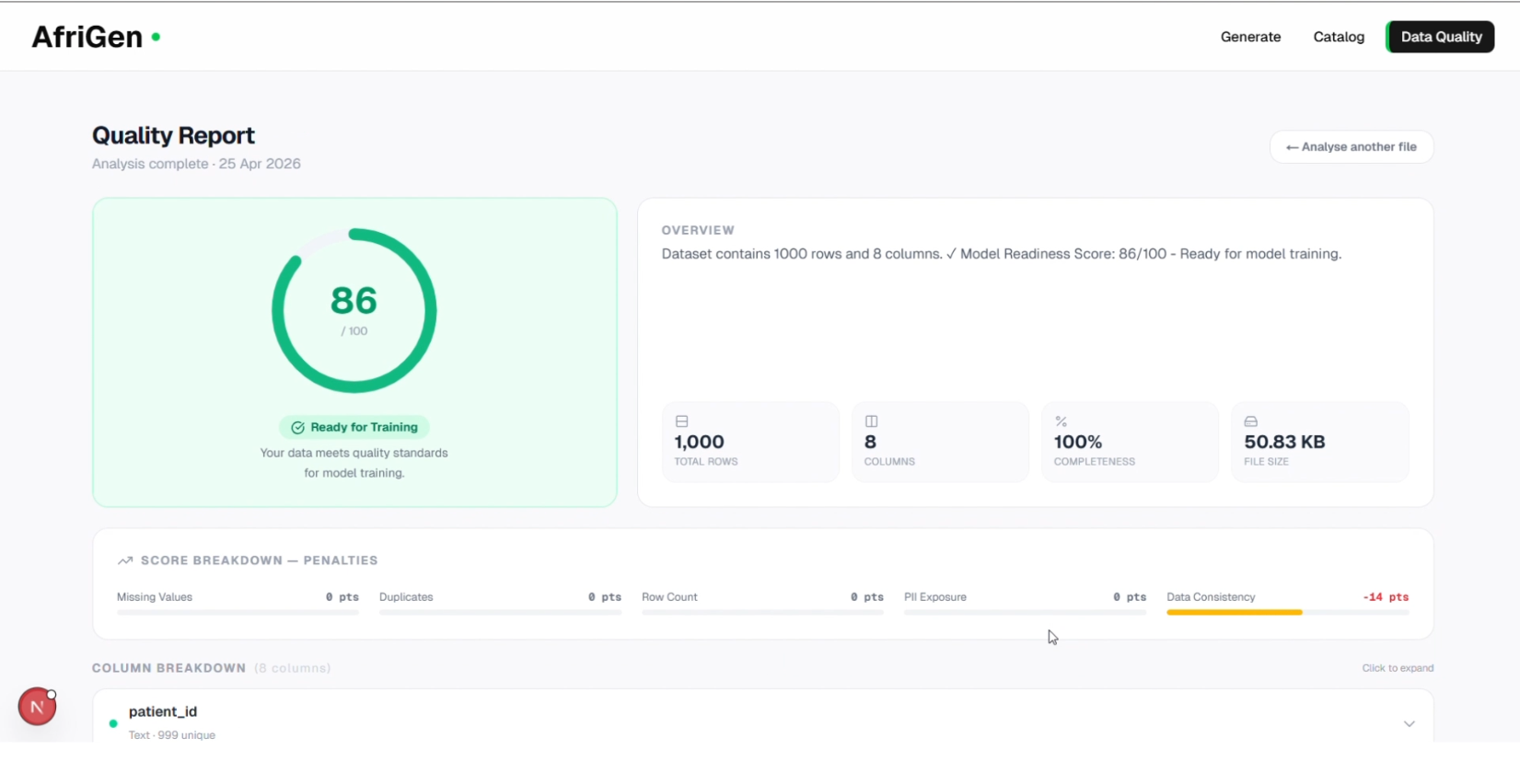
Pre-training validation layer
-
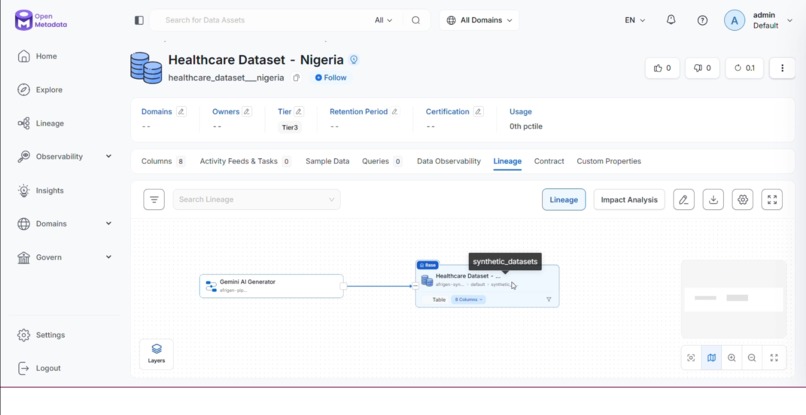
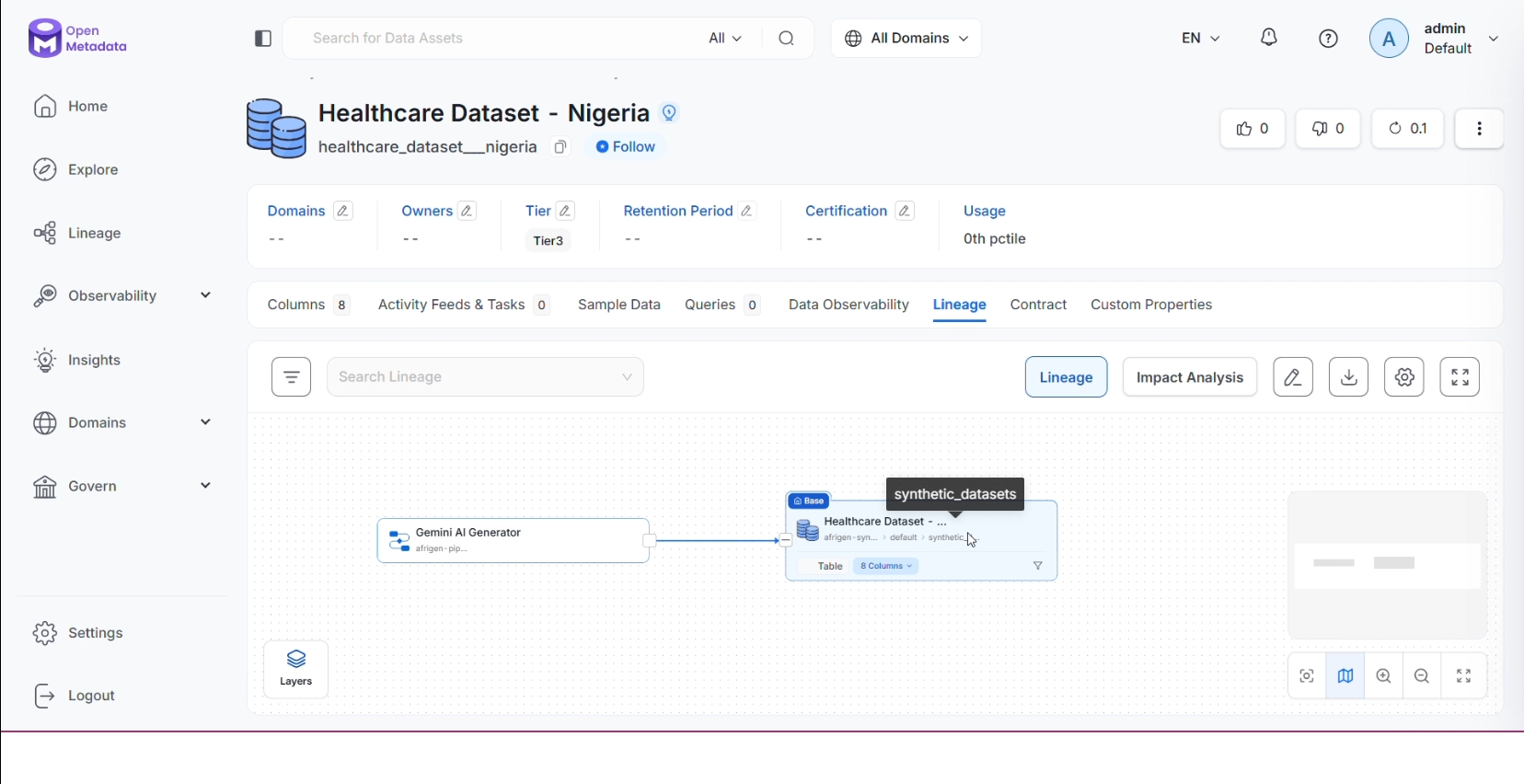
Dataset lineage shown live
-
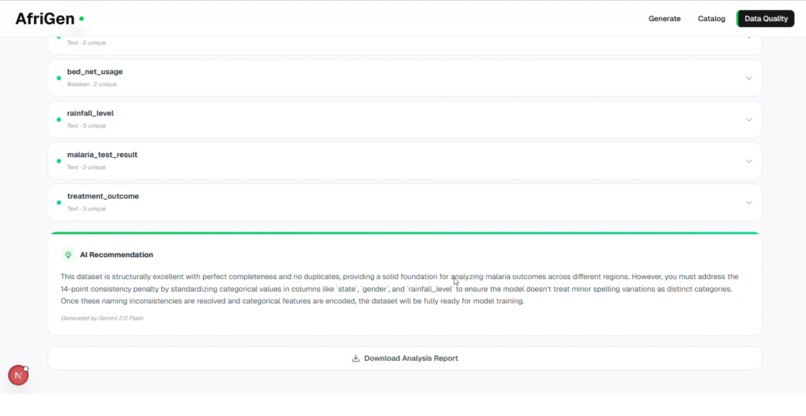
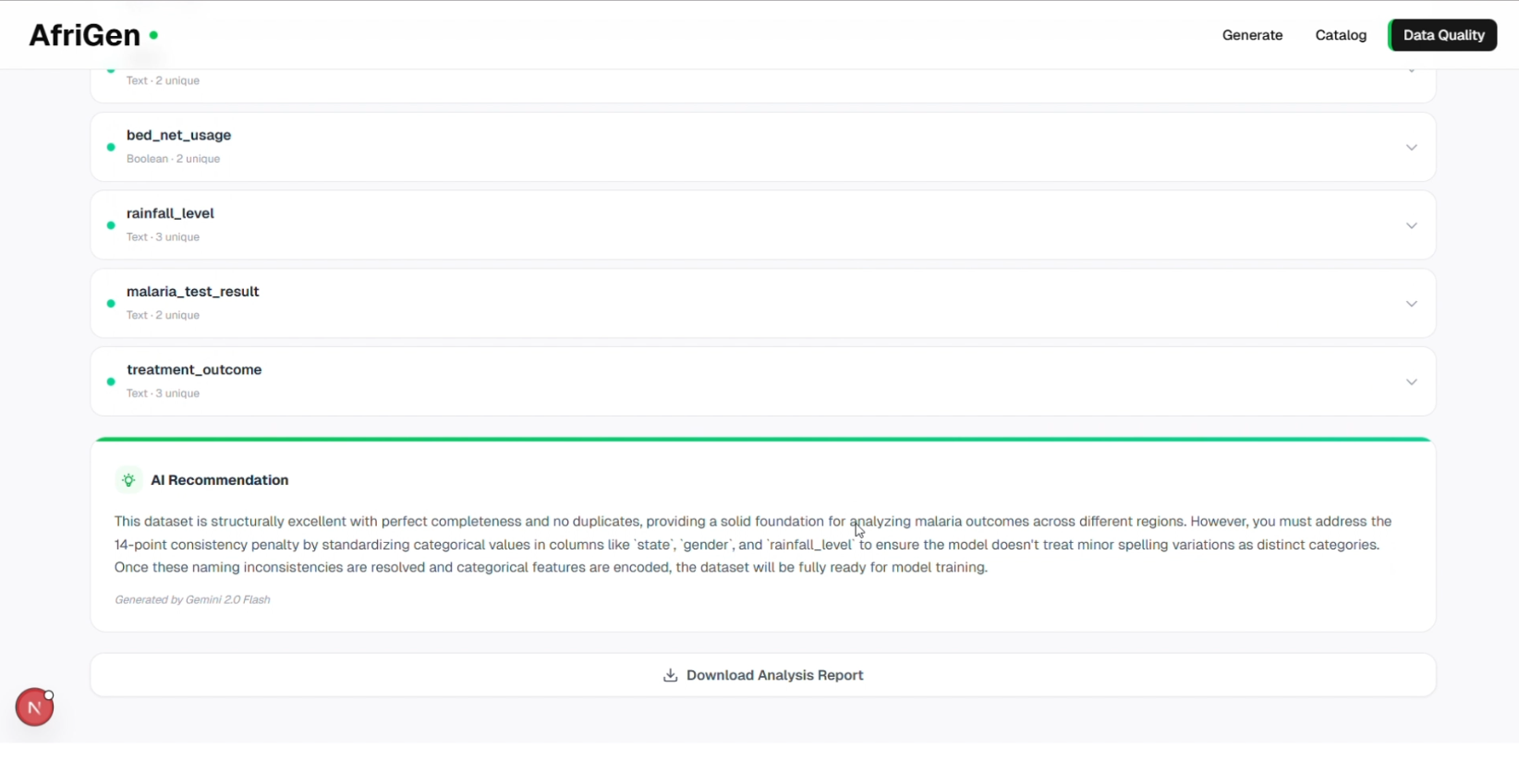
Get AI recommendation about the dataset
Inspiration
I watched an African ML engineer share his model's results online. Impressive architecture. Clean code. But a terrible performance on local data. Not because he wasn't good enough. Because the data he trained on wasn't built for us.
Most AI health models are trained on Western data. When those models get deployed in Africa, they don't work properly. Not because the engineers were bad, but because the data never represented Africa in the first place. The people who suffer are the patients.
That gap is what AfriGen was built to close. By generating high-fidelity synthetic African datasets grounded directly in WHO and World Bank statistics, AfriGen gives ML engineers data that actually reflects the continent they're building for.
This is my contribution to UN SDG 3 — not just better models, but a better data foundation for African healthcare AI.
What it does
AfriGen generates high-fidelity synthetic African datasets using Google Gemini, aligning every output with real-world statistical distributions from the World Health Organization and the World Bank. It doesn't just generate data. It ensures that what is produced reflects actual population patterns and measurable realities.
Each dataset is treated as production-grade data infrastructure from the moment it is created. As data flows through the system, it is automatically registered in OpenMetadata with full schema and end-to-end lineage, making it fully traceable from the generation pipeline to the final table. At the same time, datasets are instantly discoverable through a live, queryable catalog where each one is enriched with a fidelity score.
Before any dataset is made available, AfriGen runs a validation layer that actively inspects its quality, ensuring the data is complete, free from duplication, and safe from sensitive information leakage. It also evaluates whether the dataset is truly suitable for machine learning, assigning a readiness score and generating recommendations to improve it.
To ensure trust, AfriGen introduces quantitative fidelity scoring, measuring how closely the synthetic data matches real-world statistical distributions so users can rely on it with confidence. AfriGen currently focuses on the healthcare domain, addressing the African health data gap by generating realistic medical datasets grounded in WHO Global Health Observatory statistics. This enables machine learning engineers to build models that are not just functional but also accurate and relevant for African communities.
How I built it
I designed AfriGen as a full-stack pipeline using Next.js 14 and TypeScript, combining data generation, validation, and governance into a single system.
To fix this, I designed a pipeline that generates high-fidelity synthetic datasets using Google Gemini, grounded in real statistical distributions pulled directly from the World Health Organization and World Bank APIs. The model doesn't invent data. It generates records calibrated to match real-world numbers. I tested this with a malaria dataset covering Lagos and Kano, Nigeria, using WHO indicators for malaria risk and treatment outcomes as the statistical baseline. The synthetic output achieved a 94% fidelity score, meaning the generated data is statistically near-identical to what a real-world collection would produce.
But generation alone wasn't enough. I treated every dataset like production-grade data infrastructure. From the moment data is created, it is automatically registered in OpenMetadata with full schema and end-to-end lineage, tracing every column back to the WHO indicator it was calibrated against, the Gemini pipeline that generated it, and the validation thresholds it passed.
I also built a pre-training validation layer that runs before any dataset is surfaced. Instead of assuming the data is usable, the system actively inspects it, checking that records are complete, identifying duplication patterns, and scanning for any sensitive information. It then evaluates whether the dataset is actually suitable for model training, assigning a readiness score and generating live recommendations to improve quality before the data is ever used.
The result is synthetic African data that isn't just generated. It's governed, validated, traceable, and ready to train models that actually work for the continent.
The UI is fully accessible. Full functionality (lineage + governance features) requires connecting an OpenMetadata API token. Setup instructions are in the GitHub README.
Challenges I ran into
I'm building from Kwara State, Nigeria. That means every Docker image pulled, every API call made, and every container that failed and retried cost me real money.
Getting OpenMetadata running locally burned through 15GB of mobile data. I watched my data balance disappear in real time. Images pulling, failing, retrying, failing again on a connection that was never designed for this.
Then came the errors. Sandbox permission failures. Docker containers that wouldn't start. API validation issues I'd never seen before. Each one took hours. Sometimes a full night. But I couldn't cut corners. The lineage tracking, the catalog, the governance layer — these aren't features I added to impress judges. They're the reason AfriGen exists. Without them, it's just another data generator.
So I stayed in it. Read every doc. Traced every failure. And eventually it worked. That moment when the lineage tab opened, and I saw the flow—Gemini AI Generator → table, clean and connected—and I just sat there for a second. That one moment made every dropped connection worth it.
Accomplishments that I am proud of
I built a fully functional, end-to-end data infrastructure system covering data generation, validation, governance, and discoverability in a single pipeline.
I implemented real, traceable lineage connecting the Gemini AI generation process directly to the final dataset in OpenMetadata, so every column can be traced back to its source, transformation, and validation path.
I designed a quantitative fidelity scoring system that evaluates synthetic data against real-world WHO statistics, making it possible to measure rather than assume the accuracy of generated datasets. Using WHO indicators for malaria risk and treatment outcomes across Lagos and Kano, Nigeria, the system achieved a 94% fidelity score on a live health dataset.
What I learned
Data governance is not optional. It is the difference between generating data and building a usable data infrastructure. While building AfriGen, I realized that without structure, validation, and traceability, synthetic data quickly becomes unreliable noise. Integrating OpenMetadata changed that entirely, turning raw generated outputs into trusted, discoverable, and lineage-tracked assets that can actually be used in real-world systems.
What's next for AfriGen
Healthcare is just the start. The next phase expands AfriGen into agriculture, fintech, education, and energy, covering 50+ African countries with datasets grounded in WHO and World Bank statistics.
On the infrastructure side, I'm building team workflows, full API access, and custom data contracts so engineers can generate production-ready datasets programmatically and plug them directly into their pipelines.
Long term, I want to take AfriGen beyond the browser—partnering with African universities and NGOs to validate data quality where real-world data actually lives.
Built With
- docker
- framer
- google-gemini-ai
- next.js
- openmetadata
- render
- tailwind-css
- typescript
- who-api
- world-bank-api



Log in or sign up for Devpost to join the conversation.