-
-
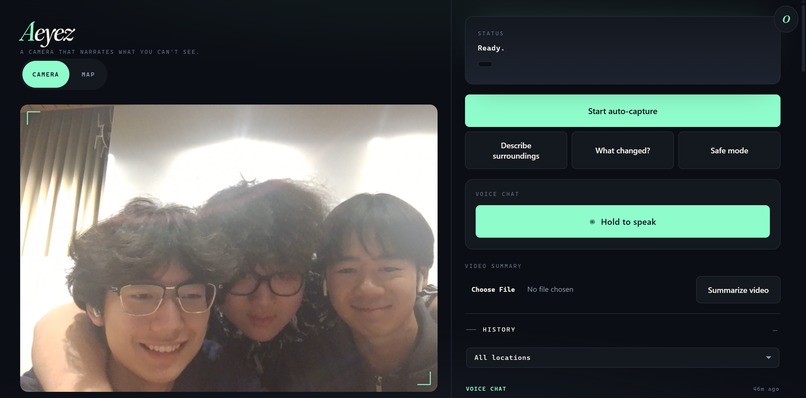
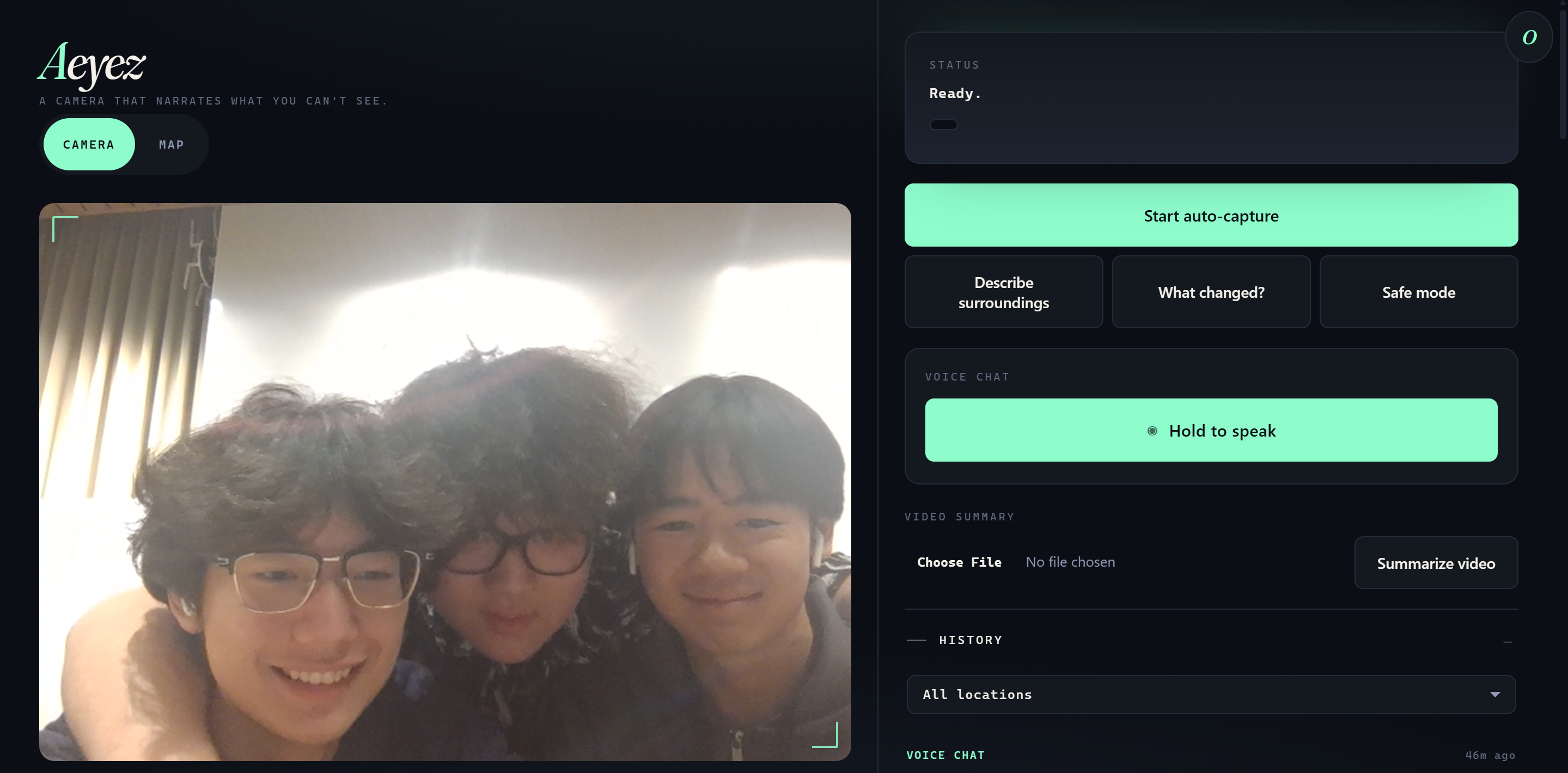
Live Camera Capture — Group Photo in Action
-
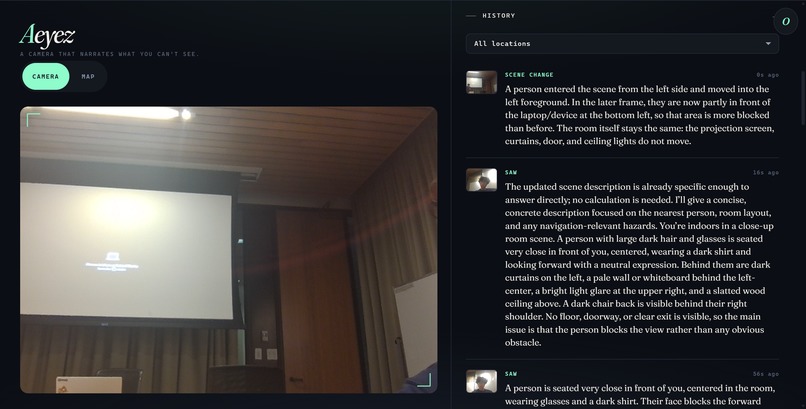
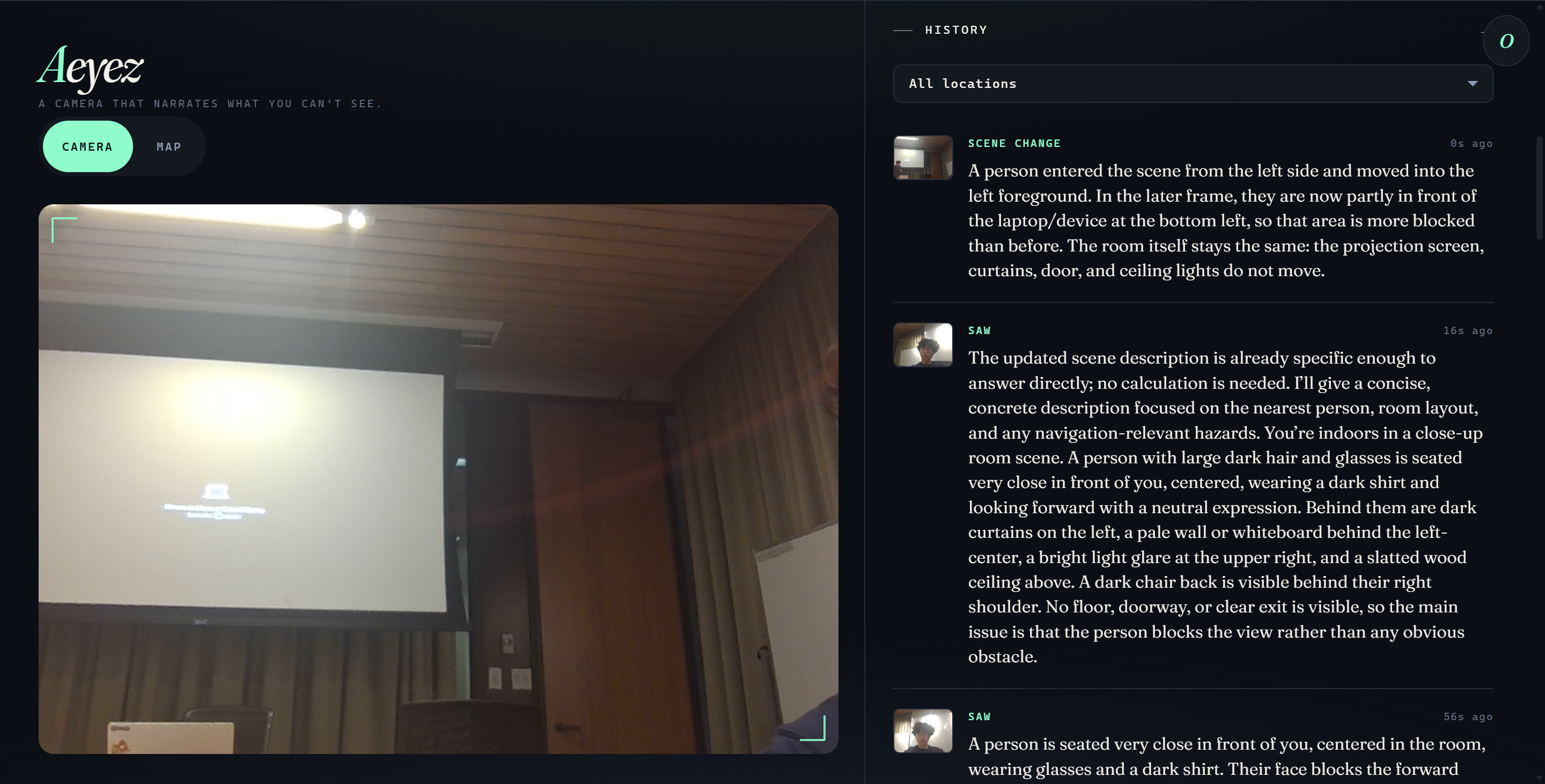
Memory Mode — Auto-capturing the Scene
-
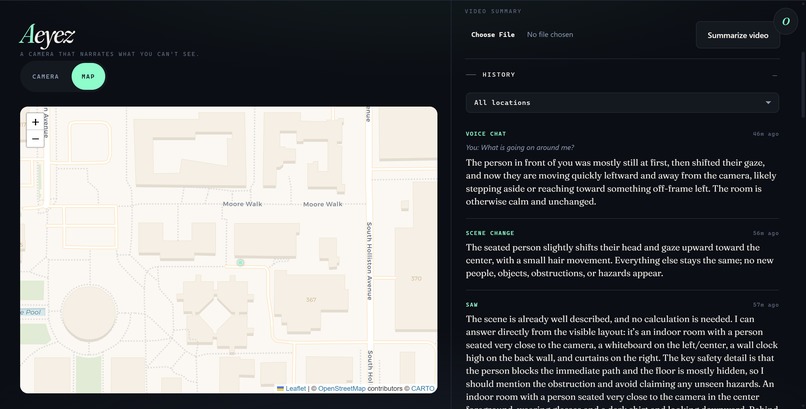
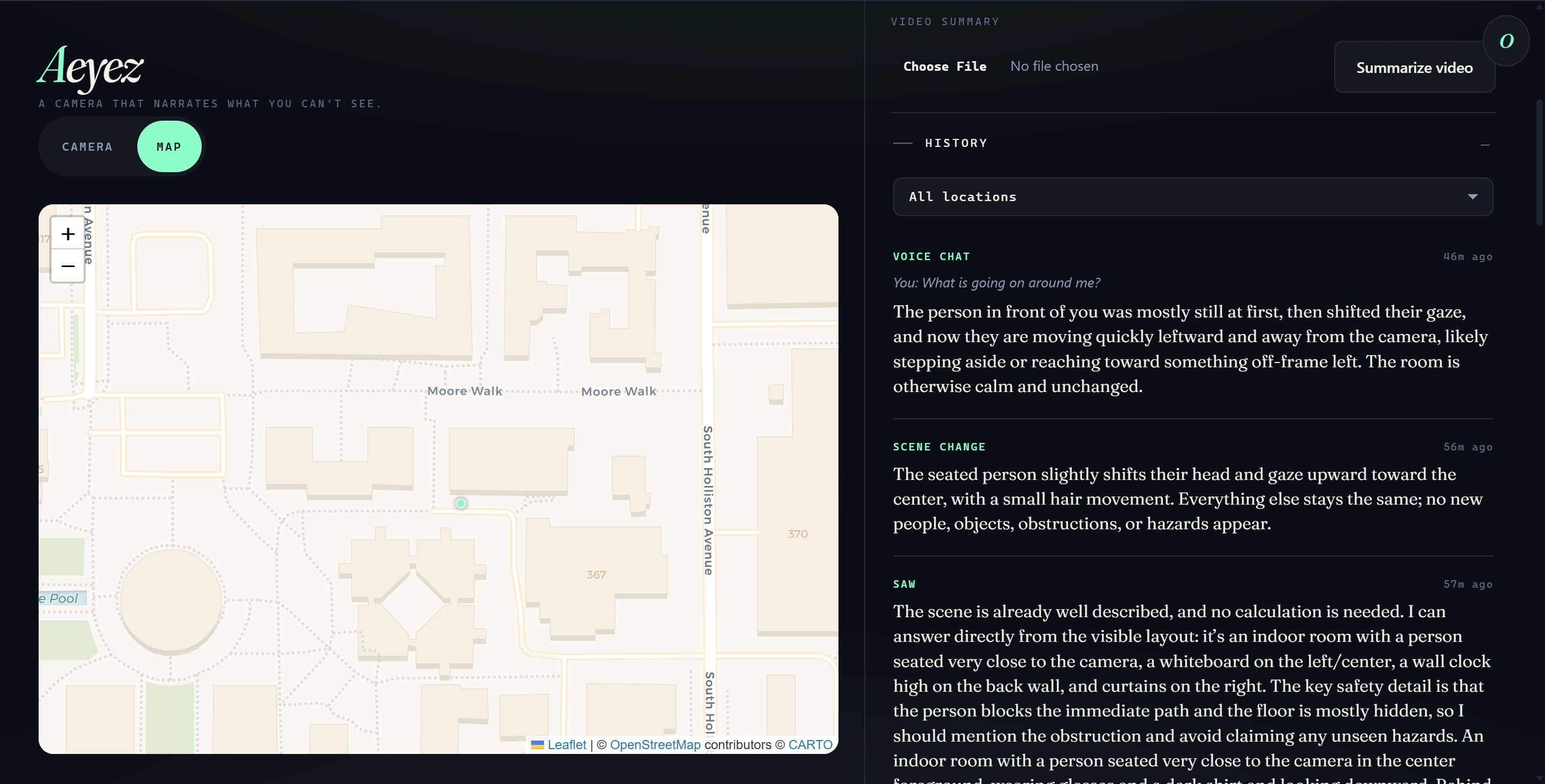
Shared Map — Location Tracking Between Accounts
-
Login Page
-

Logo in Action

Inspiration
Navigating the world independently is something most of us take for granted. For the 250 million people worldwide living with significant visual impairment, every unfamiliar environment carries invisible friction — a crowded room, a rearranged kitchen, a street corner at a new intersection. Existing assistive tools like screen readers work well for structured digital content, but the physical world doesn't come pre-labeled.
We wanted to build something that could act as a patient, always-present companion — one that sees on behalf of the user, narrates the world in natural language, and builds up a memory of the places they frequent. The name Aeyez comes from that idea: AI eyes, always watching, always ready to describe.
What it does
Aeyez is a real-time accessibility web app built for blind and visually impaired users. A device camera continuously observes the user's environment while the SeeingEye vision model narrates what they cannot see.
Key capabilities:
- Describe surroundings — on-demand single-frame scene description
- Change detection — "What changed?" diffs the oldest and newest frames in a rolling buffer, ideal for noticing when someone enters a room or an object moves
- Voice chat — hold-to-speak interface; SeeingEye answers in spoken audio via ElevenLabs TTS
- Safe mode — routes all voice input to active guidance prompts, useful in high-stakes navigation scenarios
- Persistent history — every auto-capture is logged with a photo thumbnail, GPS coordinates, and a text caption
- Named locations — users can tag familiar places; the app auto-detects repeated visits to unnamed spots and prompts to save them
- Live map — a Leaflet/CartoDB map shows the user's current position and all saved location pins
How we built it
The stack is a FastAPI backend serving a vanilla JS single-page frontend.
Vision pipeline: The core intelligence runs through SeeingEye (bundled as the Spaz submodule) — a LangGraph pipeline with two agents:
- A Translator agent that converts the raw image or video frames into a structured intermediate representation
- A Reasoner agent that answers the user's question against that representation, with up to 3 refinement iterations
This two-stage design lets the model separate perception from reasoning, which meaningfully improves accuracy on spatial questions.
Backend: server.py exposes a clean REST API (auth, history, locations, investigation, chat). Persistent data lives in SQLite via aiosqlite — lightweight enough to run entirely on a laptop or small server. Auth is JWT + bcrypt.
Frontend: A dark "Lighthouse" theme using Fraunces serif. The rolling frame buffer (clip_buffer.js) keeps recent captures in memory for the diff endpoint. The map tab is Leaflet with CartoDB tiles and reverse geocoding via the Google Maps API.
Audio: Voice input uses the Web Speech API; responses are synthesized via ElevenLabs and played back directly in the browser.
$$\text{response latency} \approx T_{\text{translate}} + T_{\text{reason}} + T_{\text{TTS}}$$
Each component is independently tunable — you can swap in a local vLLM endpoint for the Translator and Reasoner via environment variables, which we used extensively during development to control costs.
Challenges we ran into
Latency. The two-agent pipeline adds sequential overhead. A full describe-and-respond cycle currently waits for the complete model output before handing off to TTS, which creates a noticeable pause. Streaming the response to the frontend mid-generation is the obvious fix — it's the first item on our roadmap.
numpy compatibility. The SeeingEye runtime was compiled against numpy 1.x; upgrading the host environment to numpy 2 caused silent import failures. The fix is a one-liner (pip install "numpy<2"), but it cost us an hour of debugging an error message that pointed nowhere useful.
Mobile HTTPS. The Web Speech API and camera access both require a secure context on mobile browsers. Getting live-reload development to work on a phone required routing everything through ngrok — not painful, but an extra step that tripped up early testers.
Thumbnail storage. Auto-capture saves a 96×72 JPEG thumbnail directly into SQLite as a blob. This works fine for a demo, but it won't scale. A proper object store (S3, R2) is the production answer.
Accomplishments that we're proud of
- A fully working end-to-end pipeline: camera → vision model → spoken audio response, on a real device
- The change detection feature, which turned out to be uniquely useful — users described it as the feature that felt most "magical"
- A spatial memory system that ties vision events to GPS coordinates and lets users build up a mental map of familiar environments over time
- Keeping the entire stack runnable offline (with a local vLLM) so the app doesn't require a cloud connection in every scenario
What we learned
LangGraph is a genuinely powerful abstraction for multi-agent vision pipelines, but the graph wiring adds surface area for subtle state bugs. Keeping agent nodes small and their outputs strongly typed pays off quickly.
One of the hardest lessons was balancing latency and accuracy. The two-agent pipeline produces noticeably better descriptions than a single-pass approach, but every refinement iteration adds wait time. For a user navigating a physical space, every second matters. Each shortcut we tried to reduce latency introduced subtle but meaningful errors. We landed on prioritizing accuracy, reasoning that a slower correct answer is safer than a fast wrong one.
What's next for Aeyez
- Streaming responses — pipe SeeingEye output token-by-token to TTS to cut perceived latency dramatically
- Pagination in the history panel (currently capped at 20 entries)
- Mobile layout polish — the two-column grid breaks on small screens
- Hands-free wake word — reduce reliance on hold-to-speak
- Production image storage — move thumbnails out of SQLite into object storage
- Offline-first mode — cache recent history and map tiles for use in low-connectivity environments
- Wearable / glasses form factor — the real dream is a lightweight clip-on camera that runs Aeyez continuously without requiring the user to hold a phone
Built With
- api
- chatgpt
- elevenlabs
- fastapi
- javascript
- jwt
- k2thinkv2
- leaflet.js
- python
- speech
- sqlite
- web


Log in or sign up for Devpost to join the conversation.