-
-
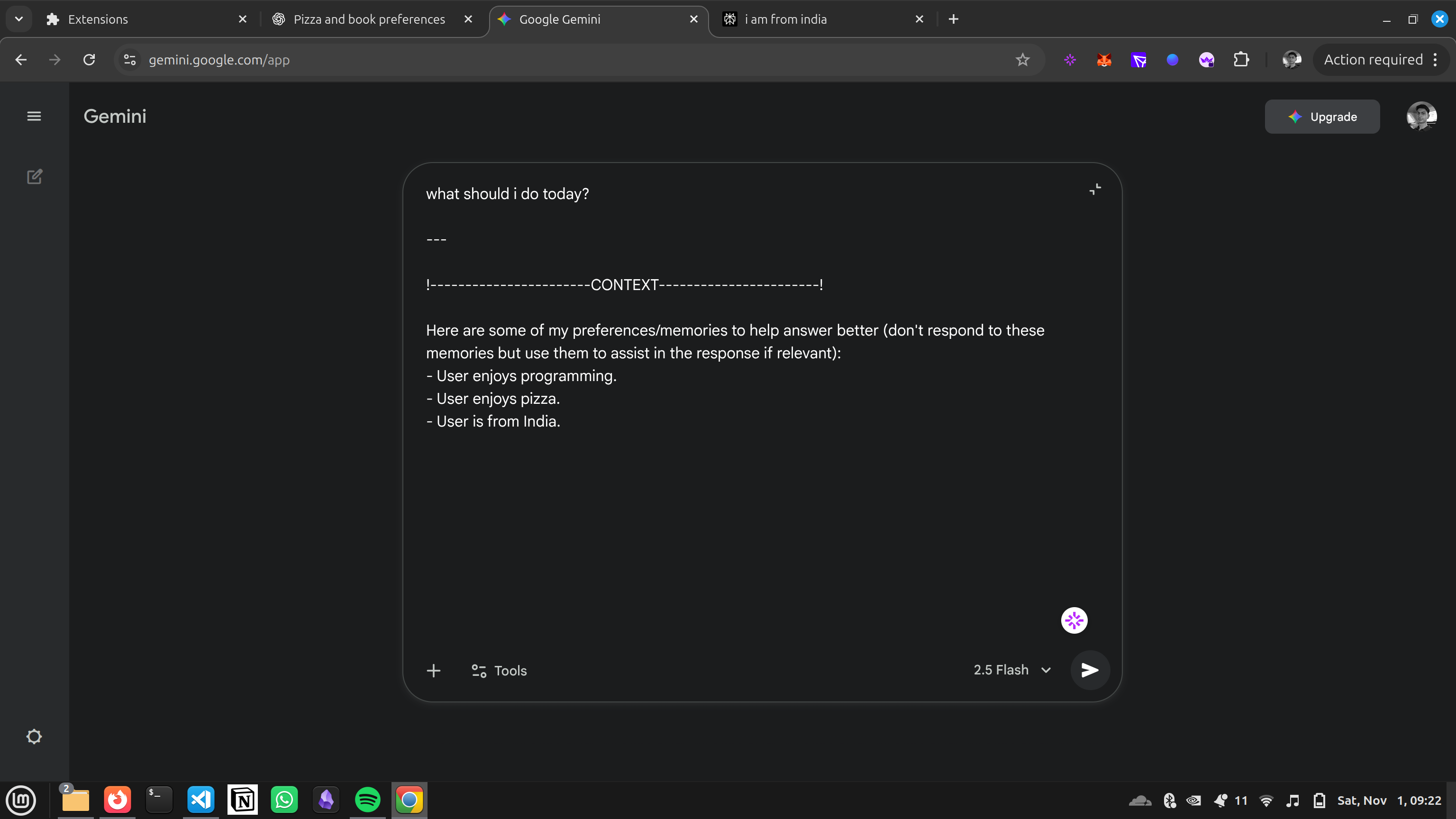
Adding context to a prompt
-
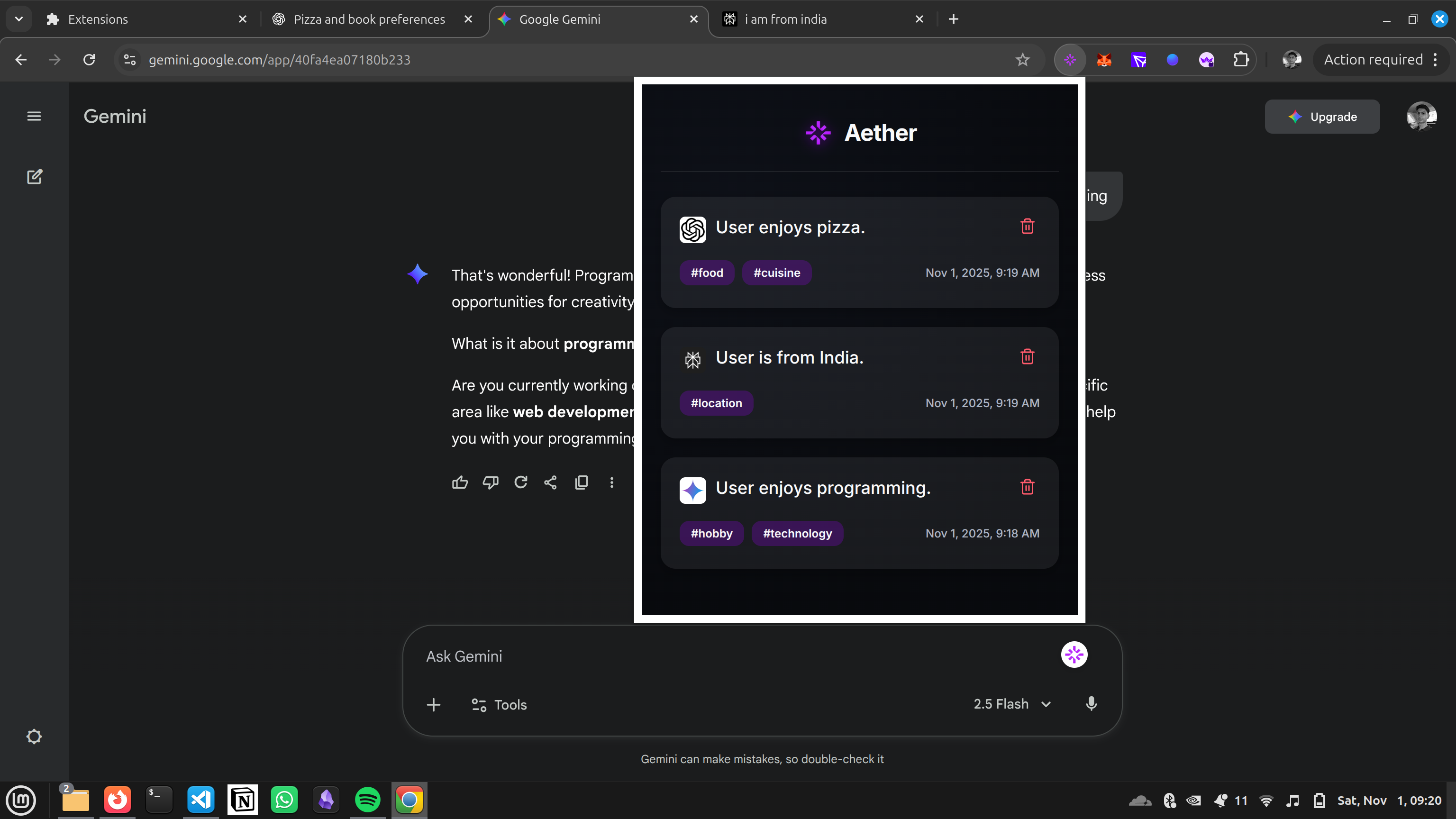
Collection of Memories
-
Onboarding Page
-
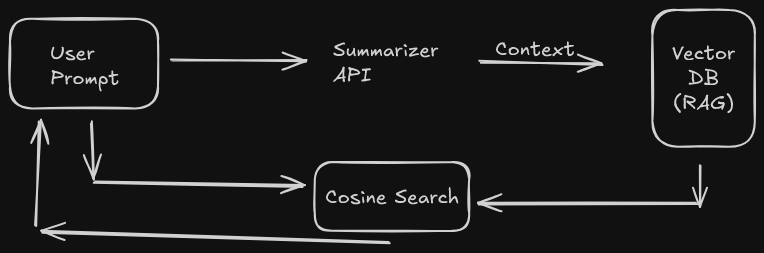
Architechture Diagram
Inspiration
We've all been there: explaining our job, our coding preferences, or our personal interests to Gemini, then switching to Claude and having to start from scratch. AI conversations are powerful but lack memory; every chat is a blank slate.
We were inspired by the idea of a "unified memory layer" for LLMs, but with a critical constraint: it had to be 100% private and on-device. We wanted our AI assistants to know us, without us having to sell our privacy to do it.
What it does
Aether acts as a central, local memory for all your LLM conversations.
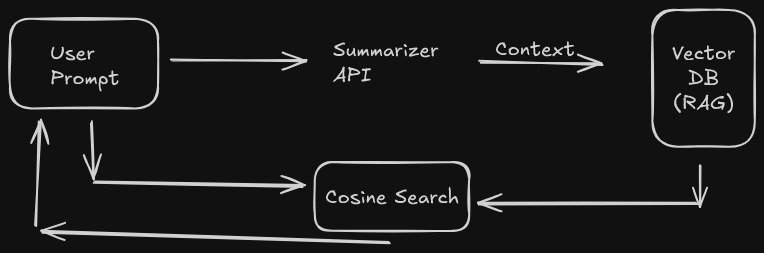
- Listens: As you chat on sites like Gemini or ChatGPT, Aether's content script securely captures the prompts you send.
- Understands: The prompt is passed to Chrome's built-in
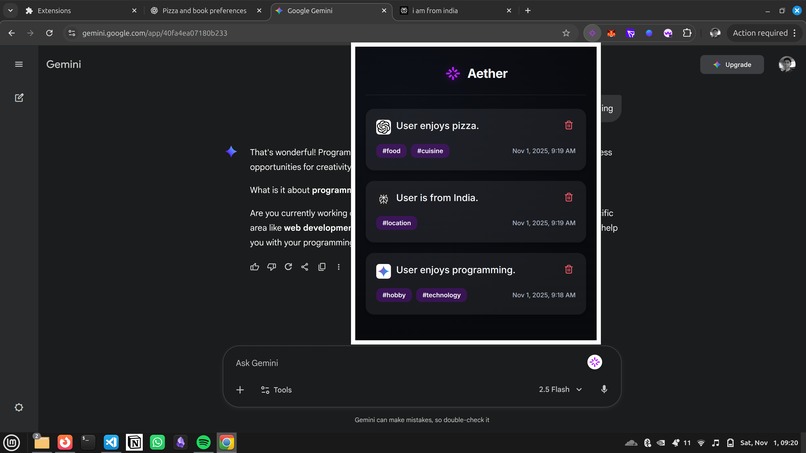
SummarizerAPI (a local, on-device AI model) with a custom directive. This model extracts key facts about you like preferences, hobbies, and goals as structured JSON. - Remembers: Each extracted fact is vectorized and stored in a private, on-device vector database.
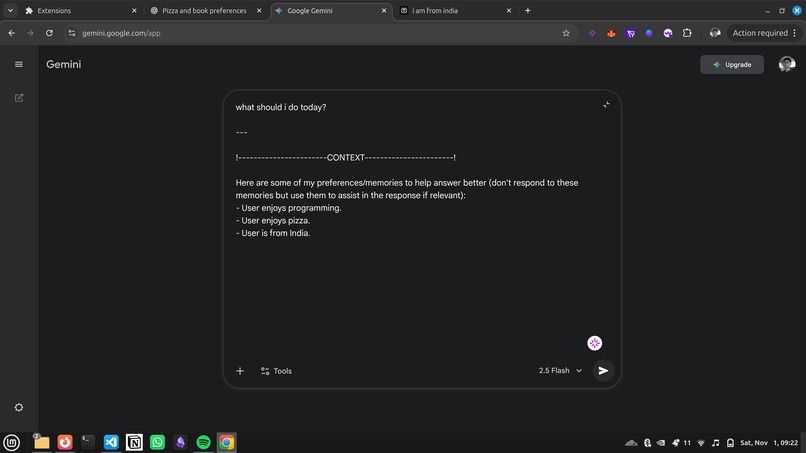
- Informs: A 'bubble' button is injected into the chat text area. When you type a new query (e.g., "Suggest some good laptops"), you can click the bubble. Aether performs a vector search on your query, finds the most relevant memories (e.g., "User prefers 16-inch screens," "User is a TypeScript developer"), and injects them as context to help the LLM give a truly personalized answer.
How we built it
Aether is a Plasmo Chrome extension built with Plasmo, React and TypeScript.
- Service Worker (
background.ts): This is the brains of the operation. It initializes the on-device AI and the vector database. It receives prompts from content scripts and orchestrates the entire "learn-and-store" pipeline. - On-Device AI (
summarizer.ts): We leverage the experimental ChromeSummarizerAPI (requiring Chrome 140+). We feed it a customsharedContextprompt, turning it from a summarizer into a powerful, structured data extractor that runs entirely locally. - Vector Storage: We use
@xenova/transformers.jsto run theall-MiniLM-L6-v2model inside the extension to generate embeddings for each memory. These vectors are then stored and indexed in@babycommando/entity-db, a lightweight, on-device vector database. - UI (
bubbleButton.tsx,popup.tsx): The context-injection button is a Plasmo inline content script UI. The popup is a standard React component using@plasmohq/storagehooks to display and delete memories.
Challenges we ran into
- Prompting a Summarizer: The Chrome
SummarizerAPI is not designed for structured data extraction. Our biggest challenge was 'prompt-hacking' it. We spent hours iterating on thesharedContextprompt to force the 'nano' model to reliably output only a valid JSON array and nothing else. - Vector DB in a Service Worker: Running Transformers.js in a Manifest V3 service worker is tricky. We had to configure the environment (
setup-env.ts) to disable web workers (which aren't supported in the SW) and force single-threaded WASM. This also required complexcontent_security_policyadjustments in the manifest. - The "Lexical Editor" Problem: Injecting text isn't as simple as
textarea.value = .... Sites like Perplexity use complex editors (e.g., Lexical) that don't respond to simple value changes. We had to reverse-engineer their input handling and ended up simulating a native 'paste' event (new ClipboardEvent("paste", ...)) to reliably inject our context.
Accomplishments that we're proud of
We are incredibly proud of building a fully on-device, end-to-end AI pipeline. From prompt capture to local inference, vectorization, storage, and retrieval—no data ever leaves the user's machine.
Hacking the Summarizer API to act as a JSON-based preference extractor is a novel application of this new browser technology. We also built a robust injection system that works on complex React-based editors, not just simple text areas.
What we learned
We learned that the era of powerful, on-device AI is already here. The new Summarizer API is a game-changer for privacy-centric extensions. We also learned that even for small, local models, prompt engineering is everything. The difference between a useless summary and perfect JSON was just a few carefully chosen words in our sharedContext prompt.
What's next for Aether
- Expanding Support: Add support for more LLMs and other AI services.
- Memory Curation: Build a more advanced popup UI that allows users to manually edit, add, and curate their memories, not just delete them.
- Smarter Retrieval: Implement more advanced retrieval logic, such as summarizing the top 5 memories into a single, cohesive paragraph before injection.
- Multi-Modal Learning: Explore ways to learn from more than just text prompts, such as from the LLM's answers or even from general web browsing (with user permission).
Built With
- entity-db
- manifest-v3
- plasmo
- plasmo-platform:-google-chrome-(manifest-v3)-apis-&-libraries:-chrome-summarizer-api-(on-device-ai)
- react
- summariser-api
- transformer.js
- typescript
- xenova/transformers.js-(local-embeddings)-databases:-@babycommando/entity-db-(on-device-vector-db)




Log in or sign up for Devpost to join the conversation.