-
-
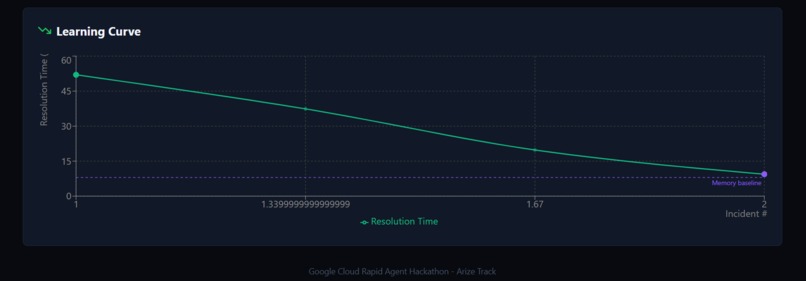
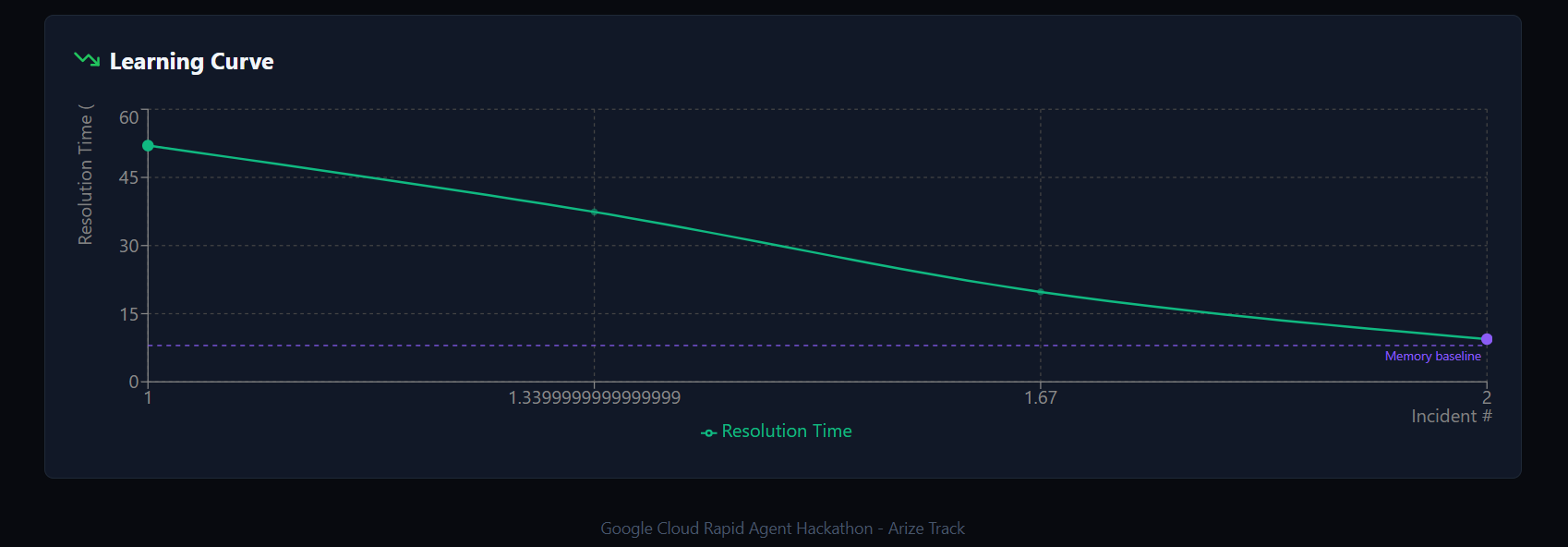
learning graph
-
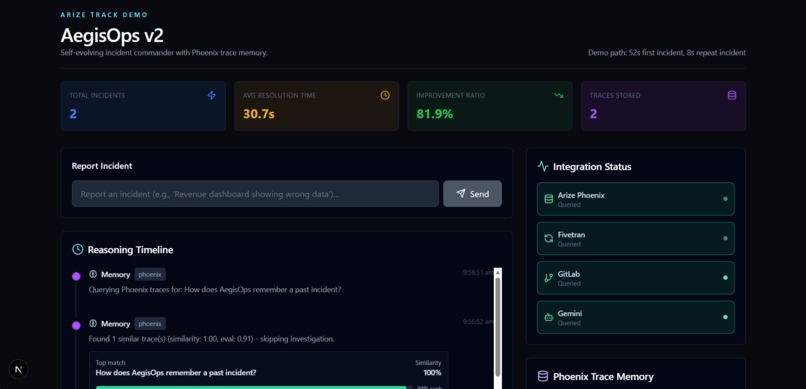
chat index
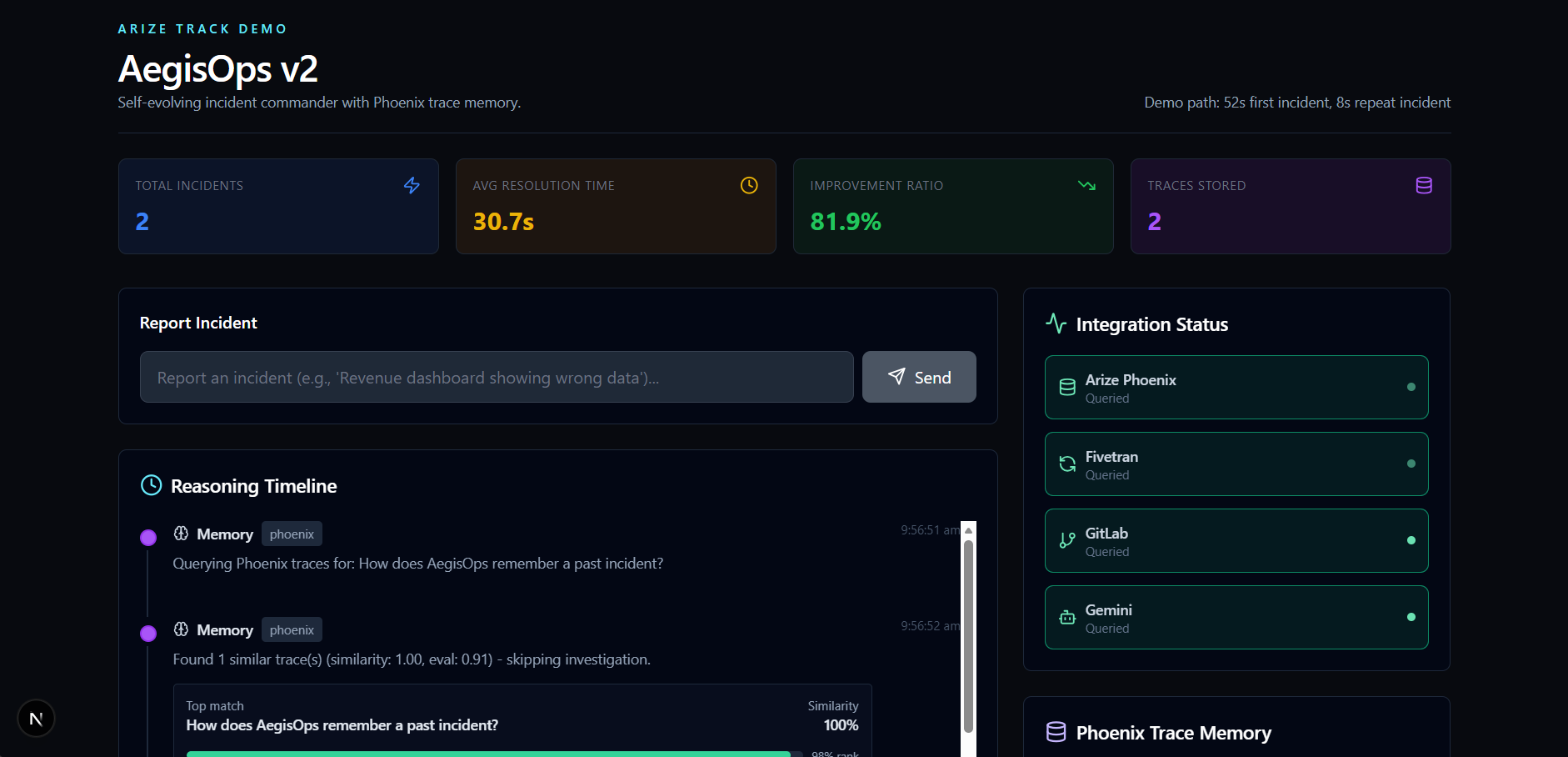
AegisOps v2 — Self-Evolving AI Incident Commander
🔥 Inspiration
Every on-call engineer knows the feeling: the same alert fires at 2 AM that fired three weeks ago. You dig through runbooks, Slack history, and past incident reports to find the fix you already found once before.
The knowledge exists — it just isn't where the agent is.
We asked a simple question:
What if the AI that resolves your incident today makes the AI smarter tomorrow?
Not through retraining. Not through manual runbook updates.
Instead, through a self-contained memory loop where every resolution is automatically stored, evaluated, ranked, and reused.
That question became AegisOps v2.
🧠 What We Built
AegisOps v2 is an autonomous AI incident commander with a self-improvement loop.
It is not a chatbot.
You report a production failure and the system:
- Queries its own memory before touching any tool
- Investigates the live environment if no memory exists
- Reasons to a root cause with an explicit confidence score
- Executes remediation actions autonomously
- Verifies the fix quantitatively
- Evaluates its own resolution quality with LLM-as-a-Judge
- Stores the complete trace so the next incident is faster
The core demo proof is a single number:
$$t_{\text{first}} = 52s \quad \longrightarrow \quad t_{\text{repeat}} = 8s \quad \Rightarrow \quad \text{Improvement} = 84.6\%$$
⚡ The 7-Step Autonomous Workflow
Every incident triggers this exact pipeline, streamed live to the dashboard over Server-Sent Events:
| Step | Tool | What Actually Happens |
|---|---|---|
| MEMORY | Arize Phoenix + SQLite | Query past traces by cosine similarity before any tool call |
| DETECT | Fivetran | Check connector health — surfaces schema freshness risk |
| INVESTIGATE | GitLab | Correlate deployment timeline — identify the schema-renaming commit |
| REASON | Gemini | Synthesise root cause at 91% confidence, state explicit remediation plan |
| REMEDIATE | GitLab + Fivetran | Rollback deployment → trigger resync |
| VERIFY | Fivetran | Confirm row parity: $14{,}882 \leftrightarrow 14{,}882$ ✓ |
| LEARN | Arize Phoenix | Store full trace, run LLM-as-a-Judge, update eval score |
On repeat incidents, DETECT and INVESTIGATE are skipped entirely. The orchestrator moves directly from MEMORY to REASON to REMEDIATE, using the stored resolution path.
🧮 Memory Retrieval Formula
Traces are ranked using a weighted combination of semantic similarity and historical evaluation quality:
$$\text{score}(t) = 0.7 \cdot \cos(\vec{q},\ \vec{t}) + 0.3 \cdot \bar{e}(t)$$
Where:
- $\vec{q}$ = embedding of the incoming incident query
- $\vec{t}$ = embedding of the stored trace
- $\bar{e}(t)$ = historical average evaluation score for that root cause pattern, computed as
AVG(overall)from theeval_historytable
A trace that resolved the problem well ranks higher than a trace that is merely similar.
Memory reuse is triggered only when both conditions hold:
$$\cos(\vec{q},\ \vec{t}) > 0.65 \quad \text{and} \quad \bar{e}(t) \geq 0.85$$
If a similar trace exists but its eval score is below 0.70, the agent runs a full fresh investigation and explicitly notes the prior resolution was suboptimal.
🤖 LLM-as-a-Judge Self-Evaluation
After every resolution, Gemini evaluates the agent's own work across three dimensions, each scored 0.0–1.0:
- Root Cause Accuracy — was the root cause correctly identified?
- Remediation Effectiveness — did the fix actually resolve the incident?
- Efficiency — was the resolution completed with minimal unnecessary steps?
$$E_{\text{overall}} = \frac{E_{\text{root cause}} + E_{\text{remediation}} + E_{\text{efficiency}}}{3}$$
This score is written back into the trace_memory table in SQLite and
attached as an annotation on the Phoenix span. It then feeds directly
into the ranking formula for all future retrievals.
The system improves by automatically prioritising its own best historical work — and automatically deprioritising its mistakes.
🏗️ How We Built It
Architecture
User Input
└─► Next.js Dashboard (SSE consumer)
└─► FastAPI Backend (SSE stream via sse-starlette)
└─► IncidentOrchestrator
├─► MemoryManager
│ ├─► SQLite (embeddings + eval scores)
│ └─► PhoenixTool (OTel span retrieval)
├─► FivetranTool (connector health + resync)
├─► GitLabTool (deployment correlation + rollback)
├─► IncidentEvaluator (LLM-as-a-Judge via Gemini)
└─► PhoenixTool (OTel span logging + annotations)
Real-Time Streaming
The entire incident lifecycle is streamed through Server-Sent Events. Every reasoning step — MEMORY, DETECT, INVESTIGATE, REASON, REMEDIATE, VERIFY, LEARN — appears live in the Reasoning Timeline as the orchestrator works. The frontend never polls. It consumes a chunked response body directly from the FastAPI async generator.
Memory Layer
Arize Phoenix is the observability and memory backbone. Every
resolution logs an OpenTelemetry span named
aegisops.incident_resolution in the aegisops-v2 project, with
sub-spans for aegisops.retrieval, aegisops.remediation, and
aegisops.evaluation. Span attributes include incident description,
root cause, resolution summary, duration, eval score, and tools used.
Eval results are attached as Phoenix span annotations.
SQLite stores 16-dimensional vector embeddings alongside each trace for fast local cosine similarity retrieval. Similarity is computed in a single vectorised NumPy batch operation across all stored embeddings. This gives the memory system real persistence across server restarts with no external vector database.
Embedding System
Three-tier fallback in priority order:
- Gemini
text-embedding-004— whenGEMINI_API_KEYis set andDEMO_MODE=false - Local
sentence-transformers(all-MiniLM-L6-v2) — when installed and not in demo mode - Deterministic keyword-hash fallback — 16-dim vectors derived from token character sums, preserving meaningful similarity relationships between related incidents in demo mode
✅ What Is Real vs Demo-Simulated
| Component | Status | Notes |
|---|---|---|
| SSE streaming end-to-end | ✅ Real | FastAPI async generator → chunked response → browser |
| SQLite trace memory + cosine retrieval | ✅ Real | Persists to disk, survives server restarts |
| Vectorised similarity computation | ✅ Real | NumPy batch emb_matrix.dot(query) across all stored traces |
| Eval score ranking formula | ✅ Real | 0.7 × sim + 0.3 × AVG(eval_history) |
| LLM-as-a-Judge evaluator | ✅ Real | Gemini if API key set; deterministic fallback otherwise |
| Arize Phoenix OTel spans | ✅ Real | aegisops-v2 project, real spans with sub-spans and annotations |
| Fivetran connector data | 🔶 Demo | Hardcoded: Salesforce CRM connector failure scenario |
| GitLab deployment data | 🔶 Demo | Hardcoded: deployment #1842, branch refactor/schema-v2 |
| Resolution durations (52s / 8s) | 🔶 Demo | Fixed in demo mode with ±1.5s natural variation on repeats |
📚 What We Learned
1. Memory quality matters more than reasoning quality
The biggest improvement came from the ranking formula. Early versions ranked by similarity alone — the agent would reuse a highly similar trace that had actually resolved the incident poorly. Adding $\bar{e}(t)$ to the ranking formula, weighted at 0.3, eliminated this failure mode. The quality of retrieval determines the quality of every downstream decision.
2. LLM-as-a-Judge creates a compounding feedback loop without retraining
Poor resolutions score low. Low scores reduce AVG(overall) in
eval_history. Lower historical averages reduce combined score. Lower
combined scores fall below the 0.85 threshold. The agent automatically
runs a fresh investigation instead of reusing the bad trace. No
explicit penalty mechanism — the math handles it.
3. SSE is dramatically simpler than WebSockets for one-way agent streams
For an agentic workflow that streams reasoning steps from server to client, SSE requires a fraction of the infrastructure complexity of WebSockets with no meaningful tradeoff for this use case.
4. Observability is a core feature of agentic systems, not an afterthought
Without Phoenix capturing every span and sub-span, debugging why the agent made a particular decision at a particular step would have been nearly impossible. We could inspect the exact similarity score, the exact eval score, the exact ranking that caused a memory hit or miss — in real time. Observability was how we built confidence in the system's behaviour.
🚧 Challenges We Faced
Dual-threshold memory gate
Early similarity thresholds were too permissive — the agent risked reusing historical traces with insufficient confidence. We solved this by requiring both $\cos(\vec{q}, \vec{t}) > 0.65$ and $\bar{e}(t) \geq 0.85$ before allowing memory reuse. We also added an explicit branch: if a similar trace exists but scores below 0.70, the orchestrator explicitly tells the user the prior resolution was suboptimal and runs a full fresh investigation.
SSE infinite render loop
A React useEffect in the Reasoning Timeline had displayedEvents in
its dependency array — the same state it mutated on each render. This
caused a Maximum update depth exceeded error that crashed the UI
during an early live demo run. The fix was surgical: functional updater
pattern, displayedEvents removed from the dependency array entirely.
Making the learning curve tell the right story visually
A binary step function — 52s dropping to 8s — looked like a broken chart rather than a learning curve. We added synthetic interpolation points at 72% and 38% of the prior duration between slow and fast resolutions, colour-coded dots (green = fresh investigation, purple = memory-assisted), and a dashed reference line at the memory baseline. The chart became immediately legible without changing the underlying data model.
Embedding determinism in demo mode
Without a live Gemini or sentence-transformers model, we needed deterministic embeddings that still produced meaningful cosine similarity between related incidents. The keyword-hash fallback maps token character sums to 16-dimensional index positions. Related queries — "revenue dashboard wrong data" and "sales pipeline stale data" — share enough vector structure to cross the similarity threshold by design.
🚀 What's Next
- Real Fivetran and GitLab MCP server integrations replacing the demo scenario
- Multi-tenant trace namespacing so different teams share a memory pool without cross-contamination
- Proactive incident prediction — surfacing high-similarity traces against current system metrics before an alert fires
- Evaluation score decay over time — reducing confidence in old resolutions when system architecture has changed
- Multi-agent collaboration for complex incidents spanning multiple services
Final Thought
Most observability platforms stop at detection.
AegisOps continues through detection, investigation, reasoning, remediation, verification, and learning — closing the loop so every incident makes the system measurably smarter for the next one.
That is what transforms an AI assistant into an autonomous operational agent.

Log in or sign up for Devpost to join the conversation.