-
-
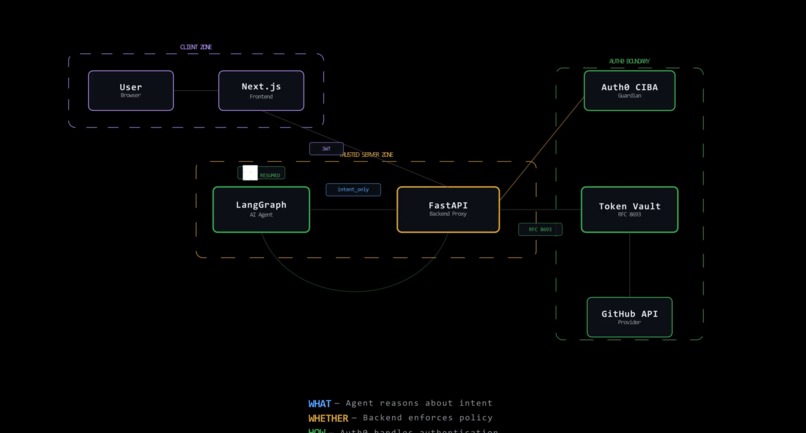
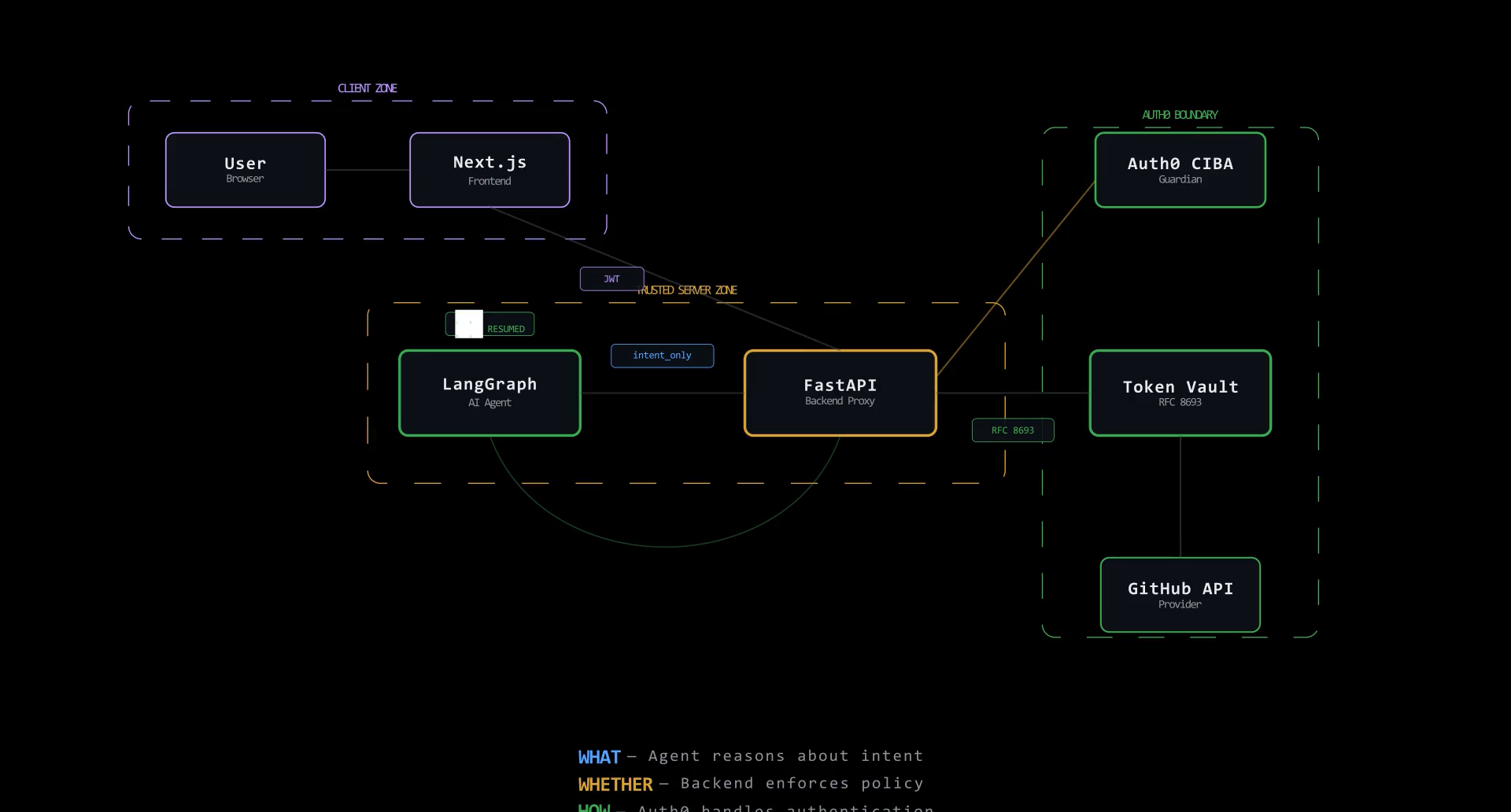
Double-Blind Pattern architecture with three security zones and Token Vault flow
-
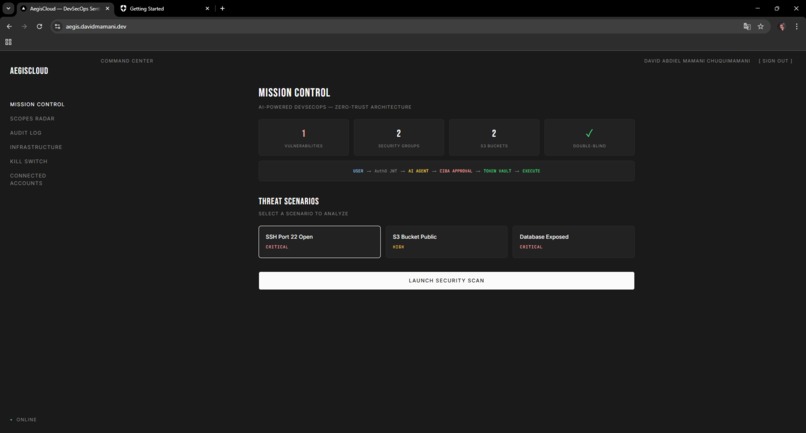
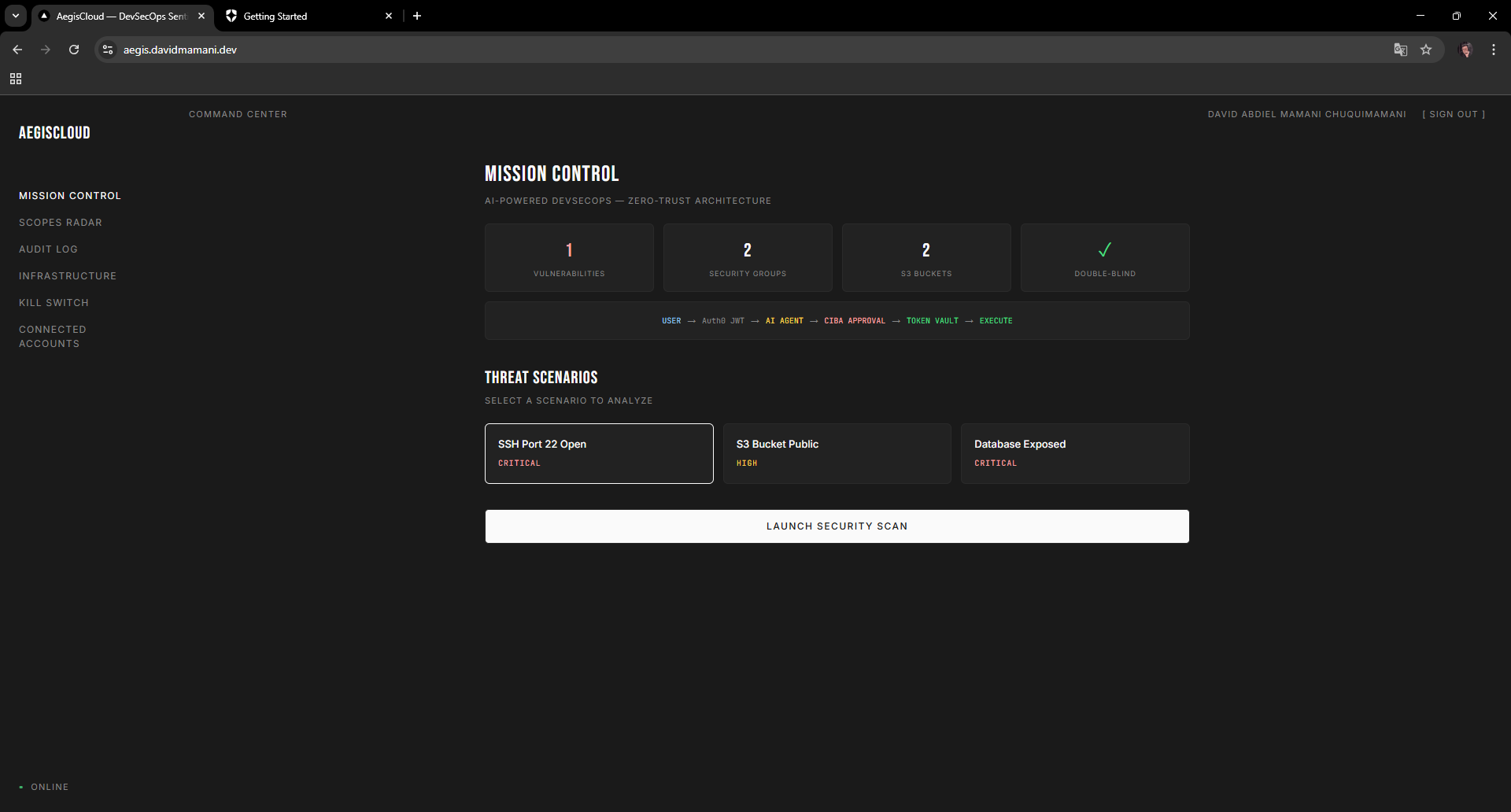
Mission Control dashboard with threat scenarios, security metrics, and the Double-Blind pipeline flow
-
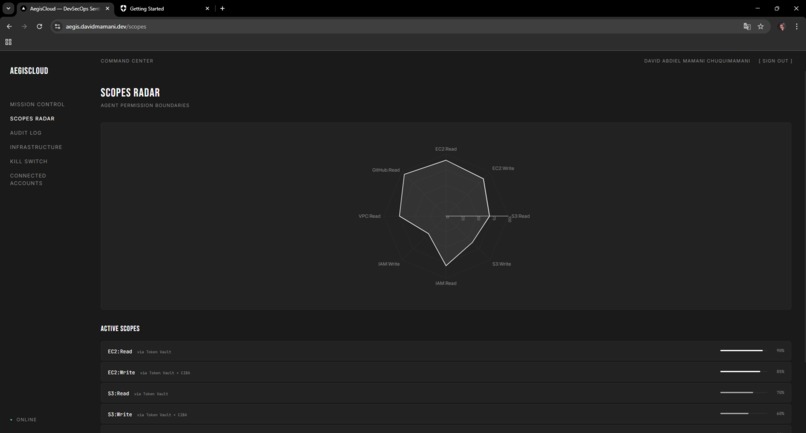
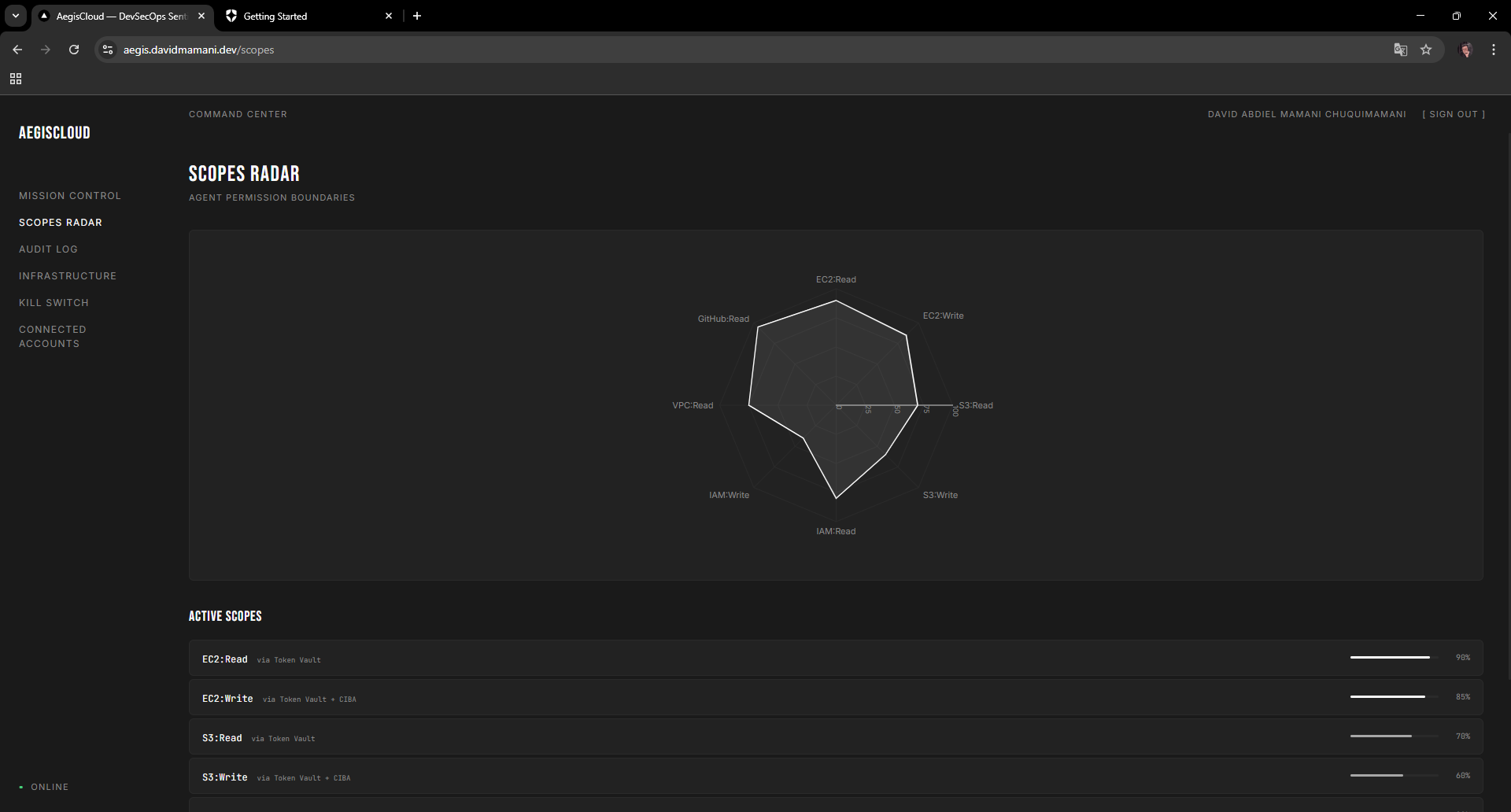
Scopes Radar spider chart visualizing the agent's permission boundaries from JWT claims and Token Vault scopes
-
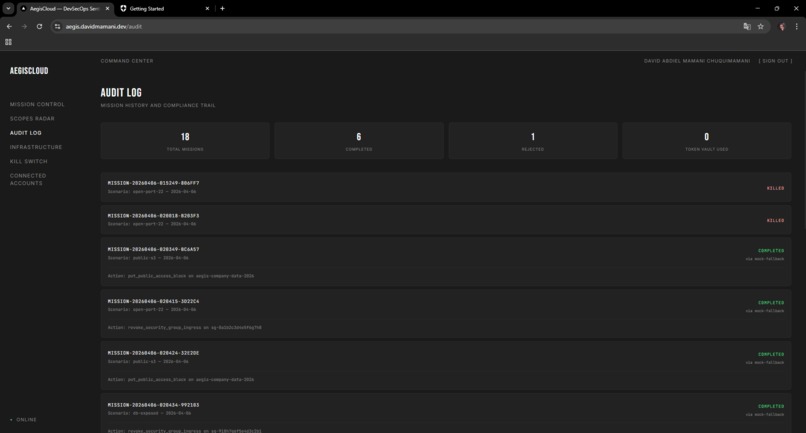
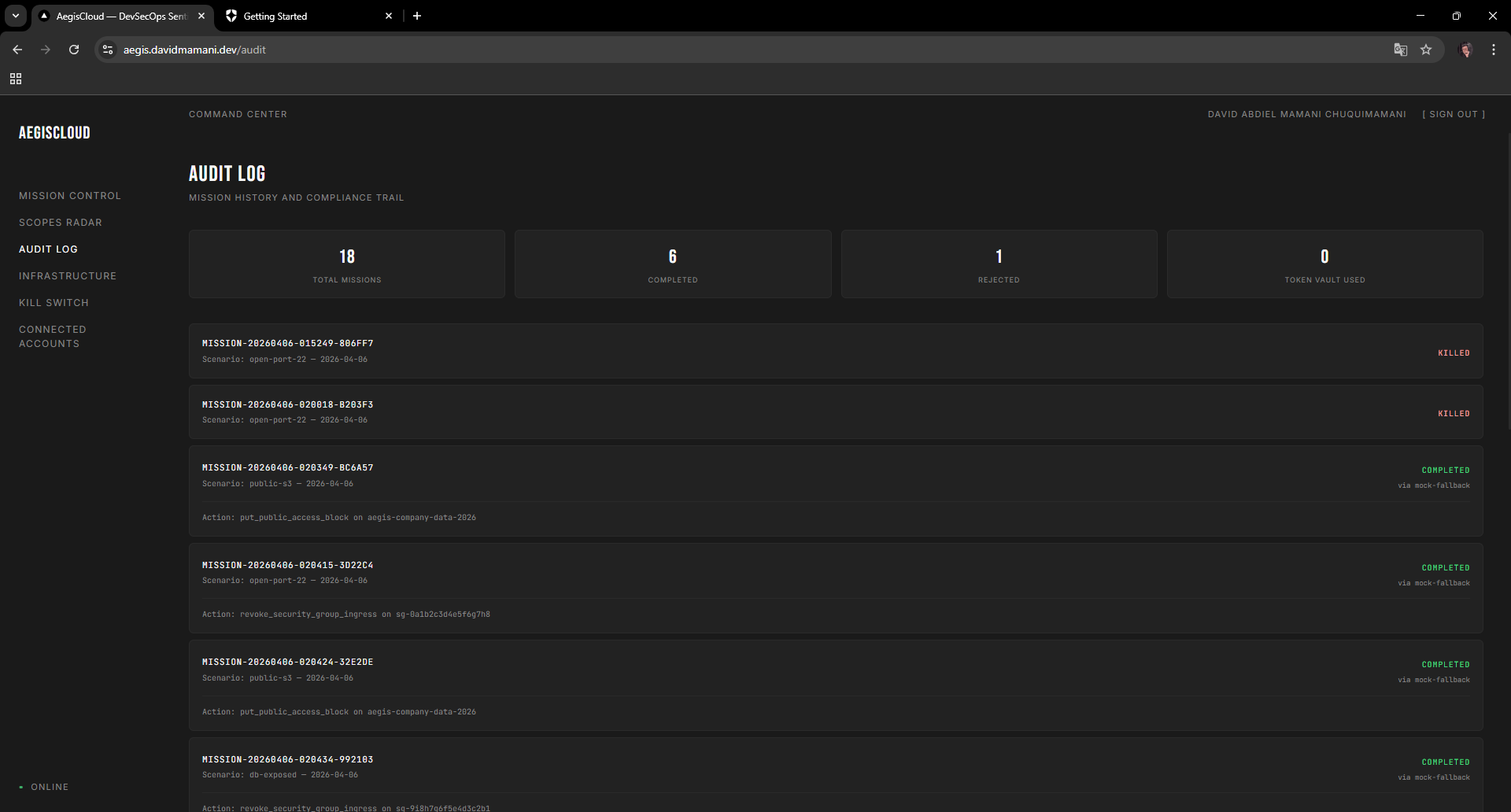
Audit Log with compliance trail showing completed, killed, and rejected missions across 18 operations
-
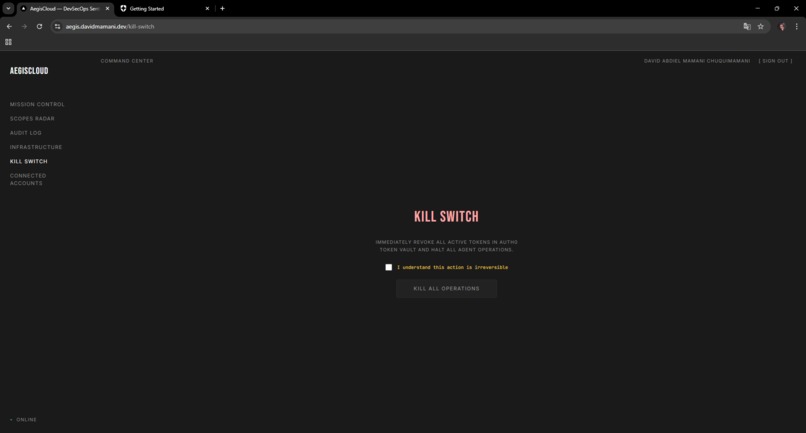
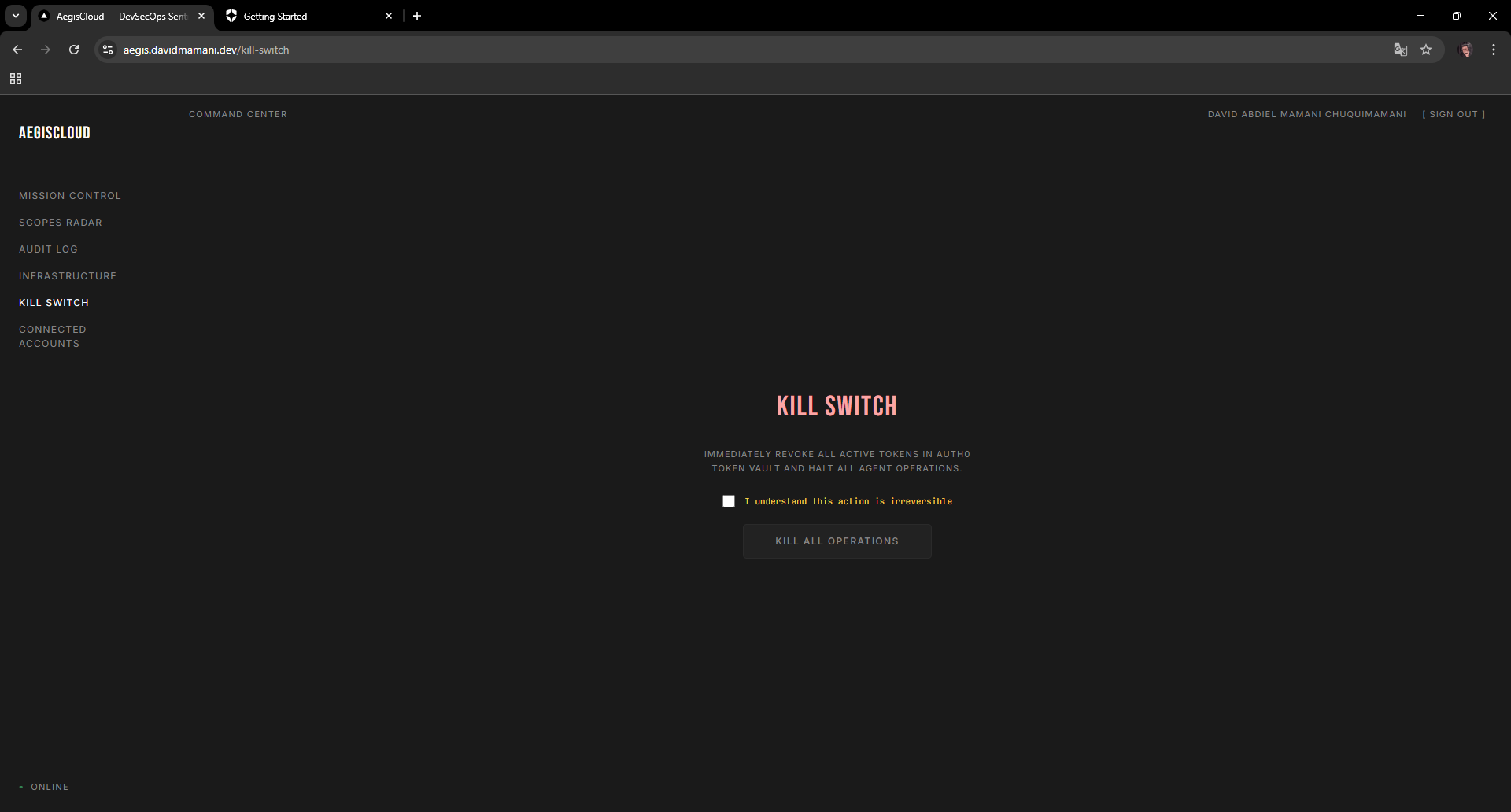
Kill Switch emergency page to revoke all active tokens in Auth0 Token Vault and halt agent operations
-
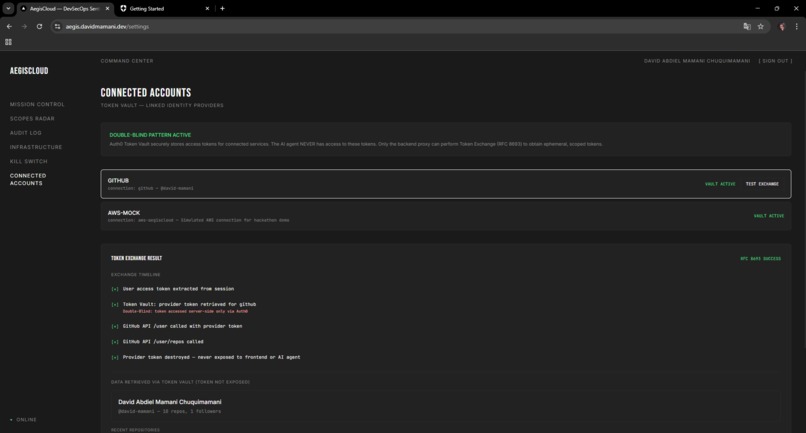
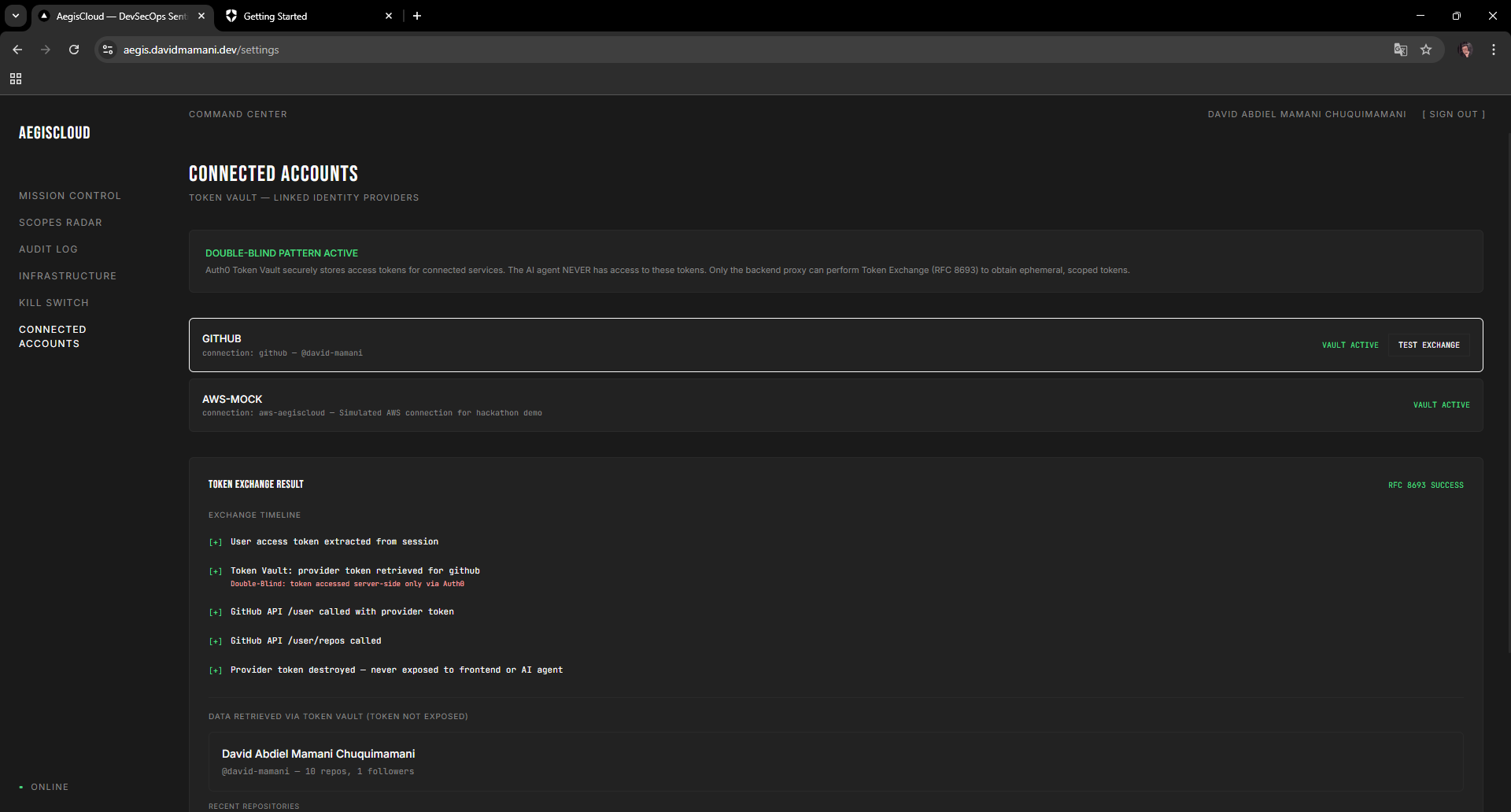
Connected Accounts showing Token Vault integration with GitHub and the RFC 8693 token exchange timeline
Inspiration
It started with a crash.
ValueError: When tool includes an InjectedToolCallId argument,
tool must always be invoked with a full model ToolCall
I was building a DevSecOps agent, an AI that analyzes cloud vulnerabilities and fixes them with human approval. My first approach: wrap a LangChain tool with Auth0's withTokenVault, add withAsyncUserConfirmation, stack them.
The inner decorator injected a schema field the outer one didn't recognize. LangChain rejected it. I tried every stacking order, wrote manual patches, wrapped the whole thing in custom functions. Nothing stuck.
After a day of frustration I realized the crash was telling me something: credentials and authorization logic don't belong in the same layer. They're different concerns at different trust levels.
The context made it urgent. GitGuardian detected 39 million leaked secrets on GitHub in 2024. AI-generated code leaks credentials at 1.6x the rate of human-written code. With tools like Claude Code, Codex, and Gemini becoming everyday companions for developers, it's a matter of time before an autonomous agent leaks a production key into a commit or log file. I wanted to make that physically impossible, not just unlikely.
What it does
AegisCloud scans cloud infrastructure for security issues (open SSH ports, public S3 buckets, IAM wildcard policies) and remediates them. The constraint: the agent cannot access any credential. Not "shouldn't." Cannot.
I call it the Double-Blind Pattern:
| Component | Role | Sees credentials? |
|---|---|---|
| LangGraph Agent | Figures out what to fix | Never |
| FastAPI Backend | Decides whether to do it | Ephemeral only, in RAM |
| Auth0 Token Vault | Handles how to authenticate | Manages full lifecycle |
The flow:
- User logs in via Auth0 Universal Login (RS256 JWT, JWKS-validated)
- Picks a threat scenario from the dashboard
- LangGraph agent analyzes and builds a remediation plan
interrupt()fires, the graph freezes, state serializes to SQLite. Only metadata leaves: resource ID, risk level, infrastructure diff. No tokens.- FastAPI sends a Rich Authorization Request via Auth0 CIBA. User sees the exact proposed change and approves through Guardian
- FastAPI exchanges the session for an ephemeral provider token via Token Vault (RFC 8693). Lives for seconds.
- Backend calls the cloud API, gets the result, revokes the token immediately
Command(resume)wakes the agent. It gets "remediated successfully" but never saw any credential
The frontend has six pages: Mission Control (launch scans, review diffs, approve/reject), Scopes Radar (spider chart of agent permissions from JWT claims), Audit Log (mission tracking), Infrastructure (CIS benchmark violations), Kill Switch (revoke all tokens instantly), and Connected Accounts (Token Vault management).
How I built it
FastAPI backend with python-jose for JWKS validation on every route. LangGraph agent with SQLite checkpointer for the interrupt/resume lifecycle. Next.js 14 frontend with Auth0's NextJS SDK. All API calls go through server-side routes that inject the JWT.
Auth0 handles: Universal Login for identity, Token Vault for RFC 8693 token exchange, CIBA with Rich Authorization Requests for approval, Guardian for push notifications.
Deployed in Docker containers on a VPS via Dokploy at aegis.davidmamani.dev.
What I implemented:
- [x] Auth0 Universal Login with RS256 JWT + JWKS validation
- [x] Token Vault integration (RFC 8693 token exchange)
- [x] CIBA with Rich Authorization Requests + Guardian
- [x] LangGraph agent with interrupt/resume lifecycle
- [x] SQLite checkpointing (zero credentials in state)
- [x] Infrastructure diff viewer (before/after)
- [x] Kill Switch with real token revocation
- [x] Scopes Radar (JWT claims visualization)
- [x] Production deployment (Docker + Dokploy)
Challenges I ran into
withTokenVault(withAsyncUserConfirmation(tool))
LangGraph's interrupt/resume required careful state choreography. I spent a full day making sure the resume path didn't leak the approval token into the agent's context.
CIBA on a free Auth0 tenant needed a poll-mode fallback since Guardian push requires enterprise features. Any developer can replicate this without an enterprise account.
Accomplishments that I'm proud of
You can inspect every SQLite checkpoint and find zero secrets:
>>> assert "credentials" not in agent.state
True
>>> assert "provider_token" not in sqlite_checkpoints
True
Not because I scrub carefully, but because the agent never had credentials to begin with.
The Kill Switch actually revokes all Token Vault tokens and halts operations. I built it thinking about what happens at 3am when nobody's watching.
And it's deployed. Not localhost. Live at aegis.davidmamani.dev with real Auth0 integration.
What I learned
Authorization and credential management are different problems. The decorator approach composes them at the function level, which works for demos but creates fragile boundaries. The Double-Blind Pattern separates them architecturally, making leaks structurally impossible.
Auth0's Token Vault is well designed at the right abstraction level. RFC 8693, scoped tokens, automatic revocation. The gap is in showing developers how to compose these at the system level.
What's next for AegisCloud
The pattern works beyond DevSecOps. AI coding agents (Claude Code, Codex, Gemini) pushing to private repos, email agents with OAuth access, financial agents executing transactions. The credential should never enter the LLM's context window.
- [ ] Publish as open-source reference architecture
- [ ] Write adapters for CrewAI and AutoGen
- [ ] Build a library to make the pattern trivial to implement
Bonus Blog Post
The decorator that crashed, and the architecture that emerged
I'm going to be honest about how this project started: badly.
My plan was simple. Use Auth0's AI SDK as documented. withTokenVault handles credential lifecycle, withAsyncUserConfirmation handles human approval, stack them on a LangChain tool, ship it. I figured I'd have a working demo in a weekend and spend the rest of the hackathon polishing the UI.
ValueError: When tool includes an InjectedToolCallId argument,
tool must always be invoked with a full model ToolCall
One decorator injected a schema field the other didn't know about. LangChain rejected the mismatch. I spent an evening trying everything: different stacking orders, manual schema patches, wrapper functions. Nothing worked reliably.
The question that changed everything
That error forced me to step back and ask something I should have asked from day one: why are credentials anywhere near the LLM in the first place?
Think about it. An AI agent needs to do two things: reason about what action to take, and authenticate to execute that action. Most frameworks treat both as the same problem, solved at the same level, inside the same function call. The token gets passed as a tool parameter, sits in the agent's context window, gets serialized into a checkpoint, maybe ends up in a log.
For simple demos, that's fine. For production systems where an agent manages real cloud infrastructure? That's a security architecture built on hope.
The model needs to figure out that port 22 is open and should be closed. It does not need to hold the AWS API key. Those are different responsibilities at fundamentally different trust levels. Mixing them is like giving a security consultant your building's master key so they can write you a report about which locks need replacing.
Building the Double-Blind Pattern
Once I stopped thinking about it as a decorator problem, the architecture fell into place surprisingly fast.
The agent lives in what I started calling an "intention space." It can analyze vulnerabilities, propose remediations, generate infrastructure diffs. It can describe with precision exactly what needs to change. But it exists in a universe where credentials literally don't exist. There's no path from the agent to any token, key, or secret. Not through tool parameters, not through shared memory, not through checkpointed state.
Token Vault lives exclusively in the backend proxy. The flow works like this:
Agent (intention only) Backend (credentials only)
┌──────────────────┐ ┌──────────────────────┐
│ "Close port 22" │──metadata──>│ Token Vault exchange │
│ "Risk: CRITICAL" │ │ Call AWS API │
│ "Diff: open→shut"│<──result────│ Revoke token │
│ │ │ (3 seconds total) │
└──────────────────┘ └──────────────────────┘
Never sees Touches token only
any credential in RAM, briefly
The backend takes the user's session, exchanges it for a scoped provider token through Auth0's Token Vault using RFC 8693, makes the API call, and revokes the token immediately. Three seconds of existence, in RAM only, then nothing. The agent wakes up and gets a clean result. "Port 22 closed." It never saw, held, or logged any credential.
The hardest part wasn't what I expected
Getting the backend integration right was straightforward. Auth0's Token Vault is well designed: RFC 8693 token exchange, scoped tokens, automatic revocation. CIBA through Guardian gave me human-in-the-loop approval. The primitives are solid.
What actually took the most time was LangGraph's interrupt() / Command(resume) lifecycle. When the agent proposes a remediation, the entire computation graph has to freeze. State gets serialized to SQLite. The frontend receives only intent metadata. Then the system waits, sometimes for minutes, for a human to review an infrastructure diff showing exactly what will change, and press approve or reject.
When approval comes, the agent has to wake up exactly where it left off, receive a sanitized result, and continue reasoning as if nothing happened. No credential leakage into its resumed state. No leftover tokens from the approval flow bleeding into the context window.
I spent a full day on this. The tricky part wasn't serialization itself, LangGraph handles that well. The tricky part was making sure the resume path was clean. That the approval token used in the CIBA flow never touched the agent's state, even indirectly. In the Double-Blind Pattern, this is guaranteed by construction: the approval happens entirely in the backend, and the only thing that crosses back to the agent is a result string.
You can verify this. Dump every SQLite checkpoint from a complete AegisCloud mission and grep for tokens, credentials, secrets, API keys. You'll find nothing. Not because I wrote careful scrubbing logic, but because there was never anything to scrub.
>>> assert "credentials" not in agent.state
True
That assertion is true at every point in the execution. During analysis, during interrupt, during resume. By architecture, not by convention.
The statistics that make this personal
Here's why I care about this beyond the hackathon. GitGuardian scanned GitHub in 2024 and found 39 million leaked secrets. Not hundreds. Not thousands. 39 million.
| Year | Secrets found | Growth |
|---|---|---|
| 2021 | 6 million | — |
| 2022 | 10 million | +67% |
| 2023 | 12.8 million | +28% |
| 2024 | 39 million | +67% |
The growth is accelerating. And here's what makes it worse: AI-generated code leaks credentials at 1.6x the rate of human-written code. As AI coding agents become standard tools in professional development, the volume of leaked secrets is going to increase unless we change the underlying architecture.
Right now, Claude Code is writing entire projects autonomously. Codex runs in sandboxed environments executing real code. Gemini is integrated into IDEs with access to local file systems. These agents need API keys, deployment credentials, database passwords to do useful work. Today, most of them receive those credentials in their context window or tool parameters, where they can be serialized, logged, or exfiltrated through prompt injection.
That's the problem I built AegisCloud to solve. Not by adding another layer of access control on top of the existing model, but by rearchitecting the trust boundary so credentials never enter the agent's world at all.
What I'd tell Auth0
One piece of feedback for the team: consider documenting something like the Double-Blind Pattern as a reference architecture.
The decorator approach (withTokenVault, withAsyncUserConfirmation) works for demos and simple integrations. But production agents, the ones that manage cloud infrastructure, push code to repositories, and handle sensitive user data, need architectural separation between the reasoning engine and the credential layer.
The primitives are all there in the SDK. Token Vault does exactly what you need for ephemeral credential management. CIBA provides the human approval layer. Guardian handles notification delivery. These are good tools. They just need a composition guide that shows developers how to think about agent authorization at the system level rather than the function level.
In my experience building AegisCloud, the moment I stopped treating Token Vault as a tool-level decorator and started treating it as a system-level service, everything clicked. The security properties became provable. The agent became genuinely trustworthy. And the code got simpler.
What this means going forward
The shift happening in professional software development right now is real. AI agents aren't just generating code suggestions anymore. They're deploying infrastructure, managing services, and executing transactions. That's not going away.
What needs to change is how we handle the credentials these agents need. The Double-Blind Pattern is my proposal: keep the reasoning engine and the credential layer in completely separate trust domains. Let the agent be intelligent. Let the backend be authorized. Don't mix the two.
It works with any framework (I built it on LangGraph, but CrewAI and AutoGen could use the same pattern) and any credential provider (Auth0 Token Vault is ideal, but the architecture is provider-agnostic).
AegisCloud runs this pattern in production right now at aegis.davidmamani.dev. It's not a whitepaper or a proposal. It's a working system. Log in, run a scan, watch the Double-Blind flow execute from analysis through approval to remediation.
I started this hackathon trying to stack two decorators. I ended it with an architecture that I genuinely believe can change how our industry thinks about AI agent authorization. Sometimes the best things come from the worst crashes.
Q.E.D. Trust is not a feeling. It's an assertion.
Built With
- auth0
- docker
- fastapi
- langgraph
- manim
- next.js
- python
- sqlite
- typescript

Log in or sign up for Devpost to join the conversation.