-
-
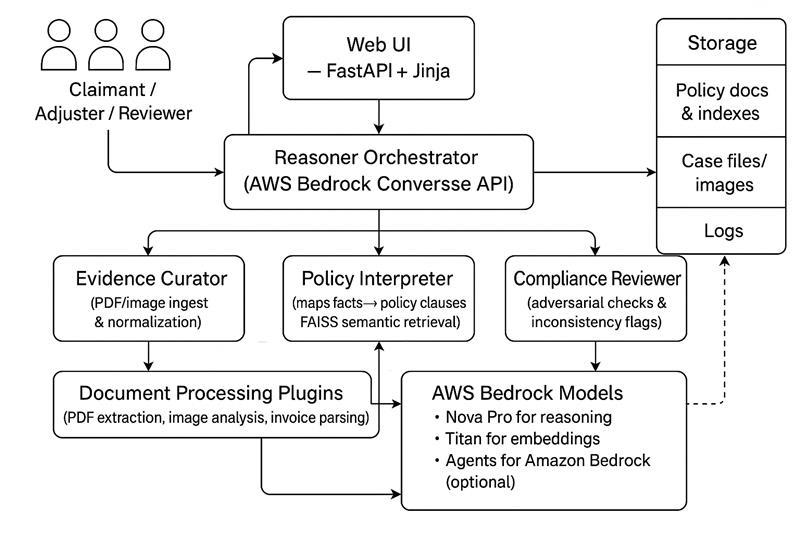
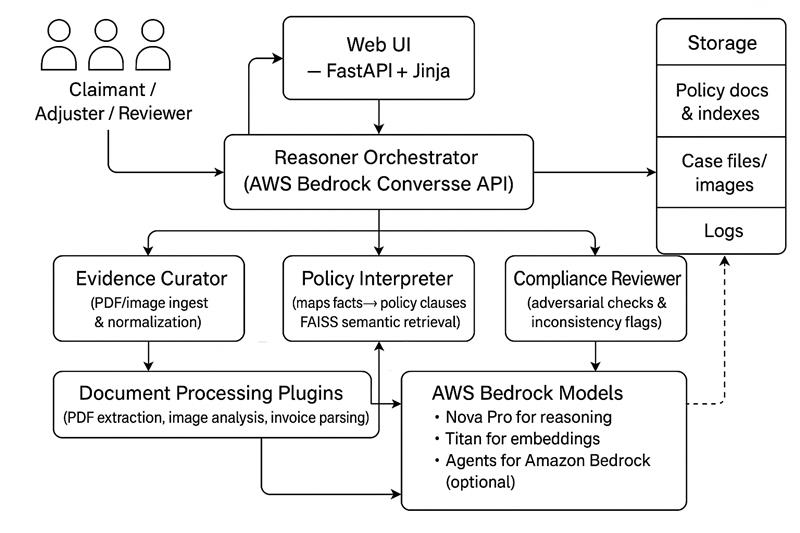
Architecture Diagram
Inspiration
Insurance claim coverage decisions are not easy to make: evidence scatters across photos, invoices, FNOL (First Notice of Loss) forms, and policy PDFs. Human reviewers juggle interpretation ambiguities (e.g., Was the damage pre‑existing? Does the exclusion apply? Is documentation complete?) under time pressure. We wanted a system that doesn’t just answer “Is this covered?” but shows its work, surfaces uncertainty, and invites clarification instead of hallucinating confident but opaque conclusions. That led to a multi‑agent collaboration pattern—distinct specialized roles debating toward a defensible, audit‑friendly outcome. To start, we need a proof of concept system to really demonstrated the feasibility, particularly with AWS. The release of AWS Kiro with Spec Development provide us the inspiration and opportunity of developing a proof of concept system for the bigger vision, as it leverage the Sonnet 4.5 model with agent utilization. One of the major objective is to explore whether or not it is feasible to build an full-stack application through the AI assistant that can adapt to our client's real business need.
What it does
End‑to‑end flow
- User submits claim artifacts (photos, invoices, PDFs, FNOL forms, etc.).
- Evidence Curator agent extracts and normalizes structured evidence (damage observations, image chronology, invoice line items, EXIF timestamps, FNOL entities).
- Policy Interpreter agent performs semantic clause retrieval against the FAISS‑indexed policy corpus, mapping facts of relevant conditions/exclusions/limits.
- Compliance Reviewer agent adversarially challenges assumptions, raises objections (scope creep, missing substantiation, temporal inconsistencies), and demands clarification where blocking.
- Orchestrator runs rounds of debate using a selection + termination strategy. If blocking objections arise early, the system “pauses” and returns a resume packet so the user can add missing evidence.
- On consensus (or exhaustion of rounds), a structured decision packet is assembled: recommended coverage stance, rationale, citations, objections (resolved/unresolved), KPI metrics, optional clarification checklist, and a memo/email draft.
Result: A transparent, traceable coverage reasoning workflow with explicit intermediate representations of evidence, interpretation, and compliance challenges.
Where AI plays out: Each AI agent we initialized has their own behavior and capability to use tools or plugins. together, they connected through chain of thought, to analyze complex problem. LLM with vision reasoning is now able to replace computer vision object detection (as indicated in the image object bounding box json body in the result page).
How we built it
We started by brainstorming with AI. When a conclusion is reached: it break the problem into clear roles. One part looks at the raw claim files (photos, invoices, forms, PDFs) and turns them into clean, structured facts. Another part matches those facts against the insurance policy text. A third part challenges the reasoning and asks “Are we missing anything?” or “Is this conclusion solid?”
To make that work: We built a simple web app so someone can upload claim files and later download a decision packet. We added three AI “agents”: one collects and cleans evidence, one links facts to policy clauses, one reviews and pushes back. We use an orchestration layer that lets these agents take turns, debate for a few rounds, and stop when either they agree or more evidence is needed. We store policy documents in a semantic index (FAISS) so we can quickly find the most relevant clauses instead of scanning everything blindly. We use AWS Bedrock models: one for general reasoning and vision (reading images, forms), and one for creating embeddings for the policy search. We wrote small plug-in processors for specialized tasks: reading EXIF data from photos, parsing invoices, pulling text from PDFs, analyzing damage in images, and checking consistency. We defined clear data structures (for evidence items, decisions, objections) so the output is predictable and easy to reuse. We built guardrails around AI outputs so if the model returns messy JSON, we can still recover the structured pieces without crashing. We added a pause-and-resume flow: if the review agent says “I can’t finish without more proof,” the system returns a checklist so the user can add missing items and continue. Finally, we bundle everything—decision summary, rationale, cited policy snippets, objections, and a draft memo—into a download package.
Challenges we ran into
- There is not enough time to do a full scale application, only 5 days when we start officially.
- AgentCore is quite new to the market and either us or LLM model do not have enough training on the utilization.
- Real data is not available and it is challenging to find suitable case study data from public domain.
Accomplishments that we're proud of
We completed the end-to-end full development life-cycle within only 5 days: from ideal brainstorming and preparation of aws resources, to data creation, architecture design, solutioning, developing, testing and deployment. This project is done with roughly 80% by Kiro and 20% from by codex for refining and online search needs. 100% of the code are written by AI and human efforts only on the prompts in the vscode or Kiro IDE, which had been impressed a lot by us on the capability of Kiro.
What we learned
A full stack web application (of simple to medium complexity) development is now possible within one week time frame with the AI assistant tools. Kiro has great utilization potential. Its strength is on its unique capability of the spec development and agent call arrangements. Kiro does not yet has online search capability so when needed new code generation and samples such as AWS Agentcore, or Microsoft agent frameworks or any plannings that needs combination with online resources, it replys on MCP, which takes time to find and setup. It would be nice if it has the avalibity to do online search agent within IDE itself as codex gpt-5 would do in vscode. We started with asking Kiro to implement Semantic Kernal based agent solution however not successful whileas Kiro seem to be more familar with aws own agent SDK and frameworks. We also noticed that BedRock Nova Pro has very good quality and performance in generating image analysis and reasoning answers which surpass significantly the GPT-4o series in our use case.
What's next for AegisAgent - An insurance-claim app fully developed by Kiro
Planned improvements: Confidence & Calibration: Add per-citation relevance scores and aggregate uncertainty metrics. Dynamic Chunk Re-ranking: Hybrid embedding + clause-type filtering (coverage/exclusion/conditions). Managed Bedrock Agents Integration: Offload some plugin orchestration to native agent tools. Streaming & Progressive UI: Show incremental agent turns live rather than batch completion. Advanced Objection Taxonomy: Severity scoring + recommended remediation actions. Policy Structuring Pipeline: Pre-process policies into normalized clause ontologies (benefit limits, exclusions, endorsements). Anomaly & Fraud Signals: Cross-reference invoice claims vs damage patterns vs temporal metadata. Formal Evaluation Harness: Regression tests for agent outputs on curated synthetic claim scenarios. Schema-Driven Prompt Contracts: Shift from freeform strings toward enforced JSON tool invocation formats. Multi-Line-of-Business Expansion: Extend beyond property claims to auto, liability, workers’ comp.
What's more important: we would like to explore further how to leverage Kiro and other AI tools to achieve a best practice for our internal Engineers efficiency improvement.


Log in or sign up for Devpost to join the conversation.