-
-
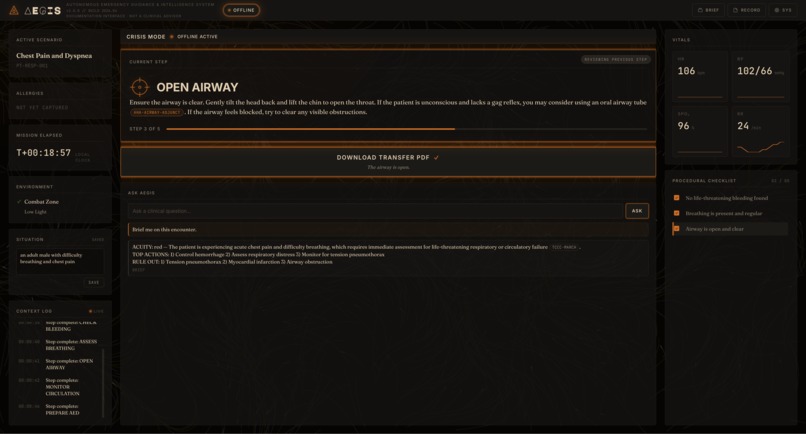
AEGIS UI/UX
-

ASUS ASCENT GX10 Supercomputer
-

Interfacing with the ASUS ASCENT GX10 using a CAT6 cable
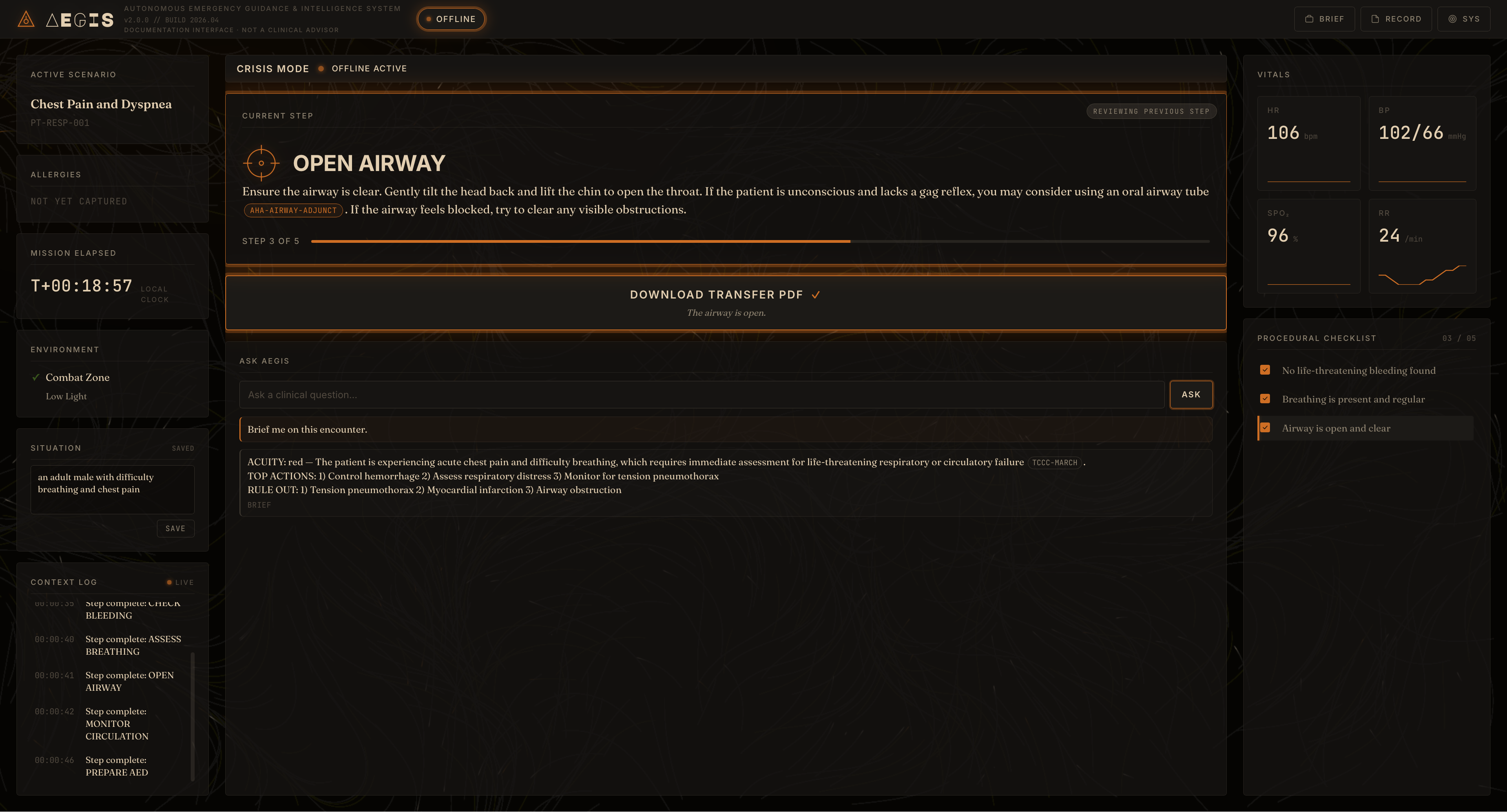


AEGIS: Autonomous Emergency Guidance & Intelligence System
Offline clinical decision-support for first responders in places without cell signal
Inspiration
Maria Chen is an EMT in rural Colorado, seventy minutes from the nearest Level III trauma center. Last winter she responded to a snowmobile crash in a canyon with no cellular coverage. Her patient had a suspected pelvic fracture, and she had thirty minutes of training on that specific injury, two years earlier. She made the call alone. She did okay. She still thinks about whether she got it right. AEGIS exists for the next time Maria takes that call, and for every responder working in austere environments where the network has gone dark and the nearest expert is hours away. We wanted to build clinical decision-support that meets the responder where they actually are, not where the cloud assumes they are.
What it does
AEGIS is an offline clinical decision-support cockpit. The operator types a short situation description ("teen male with difficulty breathing"), and a local LLM produces a structured encounter scaffold: a short title, a patient label, four to six ordered procedural steps with 40-to-60-word layperson instructions, per-step completion affirmations, and an initial brief covering acuity, top actions, and rule-outs.
- Intake: typed situation goes to a local Gemma 26B-A4B model with eight RAG-retrieved guideline chunks for grounding.
- Cockpit: a CURRENT STEP card displays the active instruction; the procedural checklist grows row-by-row as the operator advances; vitals telemetry animates on a generic arc; an ASK AEGIS chat panel handles follow-up questions against the same corpus.
- Citations: every numbered claim (compression rate, depth, dose) carries an inline citation pill that opens the source chunk pulled from local AHA, TCCC, WHO, and ILCOR guideline extracts.
- Backward navigation: the operator can click any past step to review it, with a "reviewing previous step" ribbon preventing them from losing place.
- Transfer PDF: at encounter completion, AEGIS produces one self-contained PDF with the situation, brief, every step performed with timestamps, the original instructions, source citations with quotes, and an integrity footer carrying a SHA-256 hash and Ed25519 signature.
The entire system runs locally with no network egress. No cloud LLM. No telemetry. No transmit.
How we built it
The reasoning runs on an ASUS Ascent GX10, a Grace-Blackwell AI workstation paired with a Mac Studio over a Cat6 link. The GX10's unified memory architecture is what let us run Gemma 26B-A4B unquantized, served via Ollama through an OpenAI-compatible endpoint. Round-trip latency to the model is sub-30 ms; full intake responses come back in 12 to 21 seconds; chat replies in under 2 seconds.
- Backend: FastAPI plus uvicorn, with strict-JSON LLM calls wrapped in a normalizer that coerces model output into the procedural-cockpit schema. Encounters are stored in SQLite with an append-only event-chain integrity model — every situation update, step completion, chat turn, and backward navigation is hashed and chained.
- Retrieval: ChromaDB with Nomic embeddings indexes ~15 corpus chunks extracted from authoritative guideline PDFs (AHA, TCCC, WHO, ILCOR). The intake call retrieves the top eight chunks for the situation and includes them in the prompt as a
[CORPUS]block. - Frontend: vanilla HTML/CSS/JS, no framework. The cockpit floats over a continuously evolving flow field generated from 3D simplex noise (280 particles, amber-tinted vector grid, 30-60 second reorganization cycles), with a strict opacity ceiling so the foreground stays unambiguously the brightest thing on screen.
- Transfer PDF: ReportLab renders a single comprehensive document; chain-of-custody uses Ed25519 signing of the canonical encounter JSON.
Challenges we ran into
- Strict-JSON discipline at scale: the procedural cockpit needs reliable schema output every call. Early prompts produced the right shape but occasionally truncated long step instructions. We bumped the token budget to 3072, tightened the schema with explicit word-count constraints (40-60 words per instruction), and added a normalizer that coerces missing fields rather than failing.
- Citation grounding without hallucination: getting the model to embed
[CITATION_ID]tags only when a corpus chunk actually supported the claim required iteration on the system prompt. We crossed the threshold by adding a worked example and a hard rule against inventing citation IDs. Across hundreds of test runs, no fabricated IDs appeared. - Backward navigation without losing fidelity: the V4 jump-card flow synthesized steps from checklist text alone, losing the original instruction and citations. We restructured
/procedural-stepsto return the full step shape on every graph entry, then split the checklist row click handler so the body navigates and the checkbox toggles done. - Ambient visual that does not compete with the cockpit: the first ambient layer (drifting topography, periodic sweep, coordinate ghosts) felt static. We replaced it with a flow field driven by 3D simplex noise, with a strict opacity ceiling so the cockpit's amber emission elements stay dominant.
Accomplishments that we're proud of
- A 60.7 fps simplex-noise flow field with 280 particles that runs on the same machine as the cockpit without thermal throttling.
- A transfer PDF that fits everything a receiving clinician needs into 6 KB, signed and hashed, with no separate verifier required.
- Citation grounding that survives adversarial prompts: every numbered clinical claim in the cockpit traces to a real guideline chunk on the page level.
- Sub-30 ms LLM round-trip latency over the Cat6 pairing, which made "offline" a real guarantee instead of a marketing claim.
- A procedural cockpit that displays only what the operator needs right now, with the checklist visible window contracting and expanding as they navigate forward and back.
What we learned
Local LLMs paired with workstation-class hardware have crossed a threshold where production-grade structured output is reliable. We did not need a retry-and-repair pipeline; the schema came back clean essentially every call. RAG works best when the model is explicitly forbidden from inventing citation IDs, with a worked example showing the right behavior. Restraint in the visual layer is harder than maximalism: we deleted the topography, sweep, and coordinate ghosts to get to the flow field, and the result is more present than any of the louder versions. The transfer document is the product as much as the cockpit is — what gets handed off matters as much as what gets done.
What's next for AEGIS
- Voice intake: the existing transcription pipeline is wired but not surfaced; bringing it into the cockpit lets the operator keep their hands on the patient.
- Multilingual deployment: Gemma's multilingual reach matters for field deployments outside English-speaking contexts; we need to validate the strict-JSON schema across the languages we care about.
- Expanded corpus: 15 chunks is enough for a demo; a real deployment needs 200+ across pediatric, OB, environmental, and toxicological guidelines.
- Hardware miniaturization: the GX10 is the right power class but the wrong form factor for a backpack. The path forward is the same model on a Jetson-class device that fits in a med kit.
- Field validation: the next milestone is putting AEGIS in front of actual EMTs, paramedics, and field medics, watching them use it under stress, and rebuilding whatever does not survive contact.







Log in or sign up for Devpost to join the conversation.