



Checkout Full Video:
Inspiration
Modern combat data shows something uncomfortable: a large portion of deaths aren’t due to lack of advanced medicine, but because care didn’t happen fast enough. The first few minutes decide survival, and in most cases, the person on scene is not a trained medic.
That same pattern exists in everyday life. Car accidents, choking, severe bleeding, and cardiac arrest all share one constraint:
$$ P(\text{survival}) \propto e^{-k t} $$
We were inspired by a simple question:
What if anyone could act like a medic in those first critical minutes?
What it does
Aegis Vision is an AI-guided emergency assistant that uses wearable POV (Meta Ray-Ban glasses) to:
- See what the user sees (live camera feed)
- Listen to the situation (audio context)
- Analyze the scene in real time
- Provide step-by-step first aid guidance
Example:
- Detects heavy bleeding → instructs tourniquet or pressure
- Detects unconscious person → guides airway + breathing check
- Detects distress → initiates structured response flow
The goal is simple:
turn untrained bystanders into effective first responders
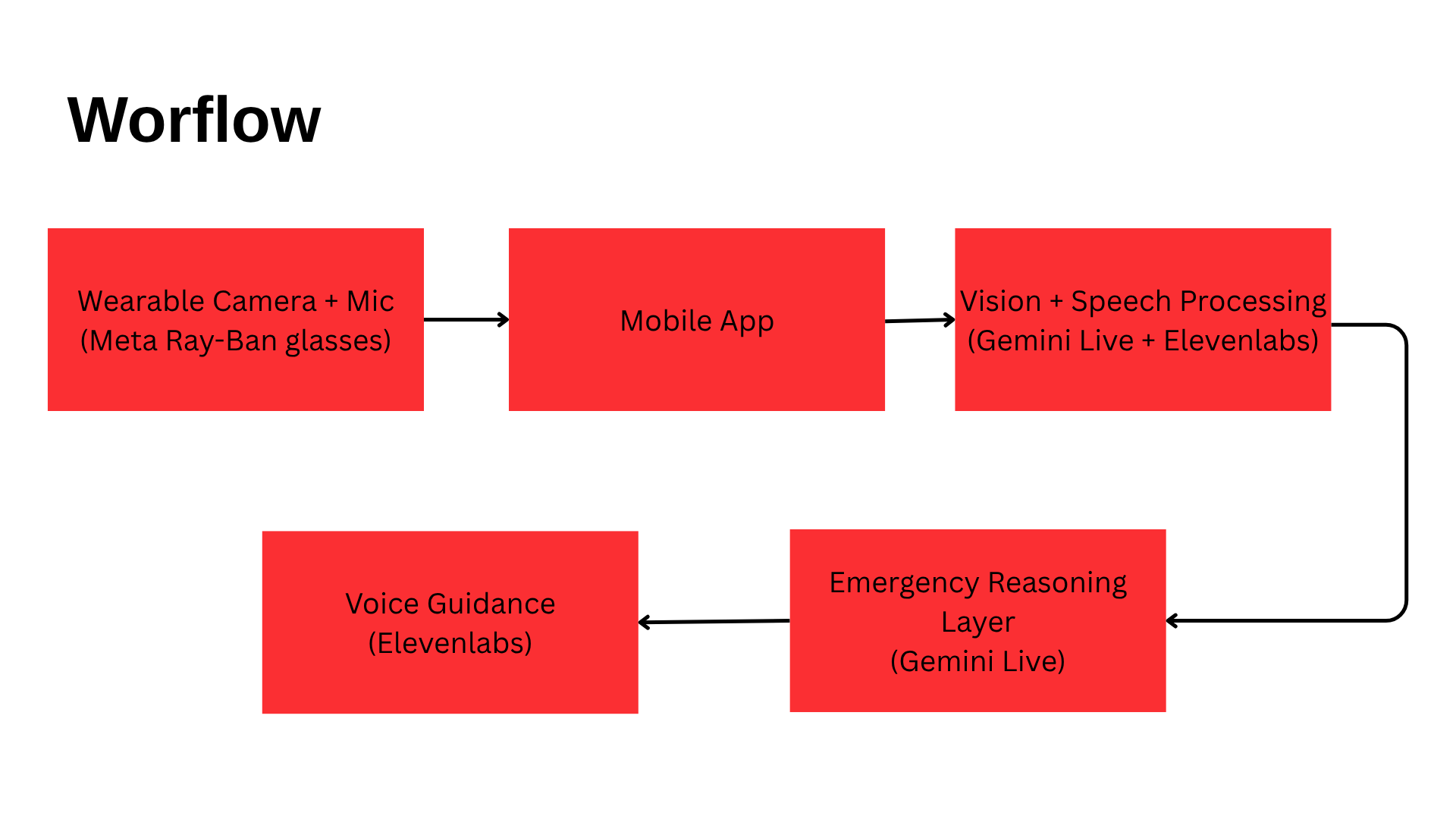
How we built it
We built Aegis Vision as a real-time pipeline:
1. Input (Wearable POV)
- Meta Ray-Ban glasses → camera + mic
- Stream routed through mobile device
2. Processing Layer
- Vision models (frame-by-frame analysis)
- Speech-to-text (real-time transcription)
- LLM reasoning layer for decision-making
3. Output Layer
- Text-to-speech guidance (low-latency voice)
- Continuous feedback loop (observe → guide → adjust)
System flow:
$$ \text{Camera + Audio} \rightarrow \text{CV + STT} \rightarrow \text{Reasoning} \rightarrow \text{Voice Guidance} $$
We prioritized:
- low latency
- continuous context awareness
- simple, actionable outputs
Challenges we ran into
1. Hardware constraints
- Wearables stream at low FPS (~1–3 fps)
- Limited direct access to camera pipelines
2. Latency
- Real-time guidance requires near-instant response
- Chaining CV + STT + LLM + TTS introduces delays
3. Reliability
- AI hallucination in high-stakes environments is unacceptable
- Needed structured, constrained outputs
4. UX under stress
- Users in emergencies can’t process complex instructions
- Instructions must be:
- short
- clear
- sequential
- short
Accomplishments that we're proud of
- Built a working end-to-end real-time pipeline
- Integrated wearable POV into an AI decision system
- Achieved continuous feedback loop (not one-shot AI)
- Designed for real-world constraints, not just demos
Most importantly, we moved beyond “AI answers questions” →
to AI actively guiding human action in critical moments
What we learned
- The hardest problem isn’t AI accuracy, it’s timing + usability
- In emergencies, clarity > intelligence
- Real-world systems break at integration points, not models
- The highest-impact AI applications are in time-critical decision gaps
We also learned that:
the gap between injury and professional care is where AI can matter most
What's next for Aegis Vision
Short term
- Improve vision models for:
- bleeding detection
- consciousness assessment
- bleeding detection
- Reduce latency across the pipeline
- Add offline/local fallback systems
Mid term
- Expand to more scenarios:
- CPR guidance
- trauma triage
- disaster response
- CPR guidance
Long term
- Integrate into:
- advanced wearables
- emergency response systems
- advanced wearables
- Become a universal first-response layer
Built With
- kotlin
- python

Log in or sign up for Devpost to join the conversation.