-
-

cover
-
embed pop up + analysis
-
embed pop up
-
flow

Inspiration
Large language models are incredibly powerful, yet they often sound more certain they actually are.
While exploring the tracks, I zoned in on the AI Safety Track and become interested in overreliance and automation bias: the tendency to trust AI outputs simply because they are well-structured, fluent, and confident. In many cases ChatGPT presents answers with a tone of certainty, even when evidence is weak, context is missing, or assumptions go unstated. Because the responses feel authoritative, users rarely pause to question them.
This led to me to a question: What if we could see when AI confidence doesn't match it's evidence?
What it does
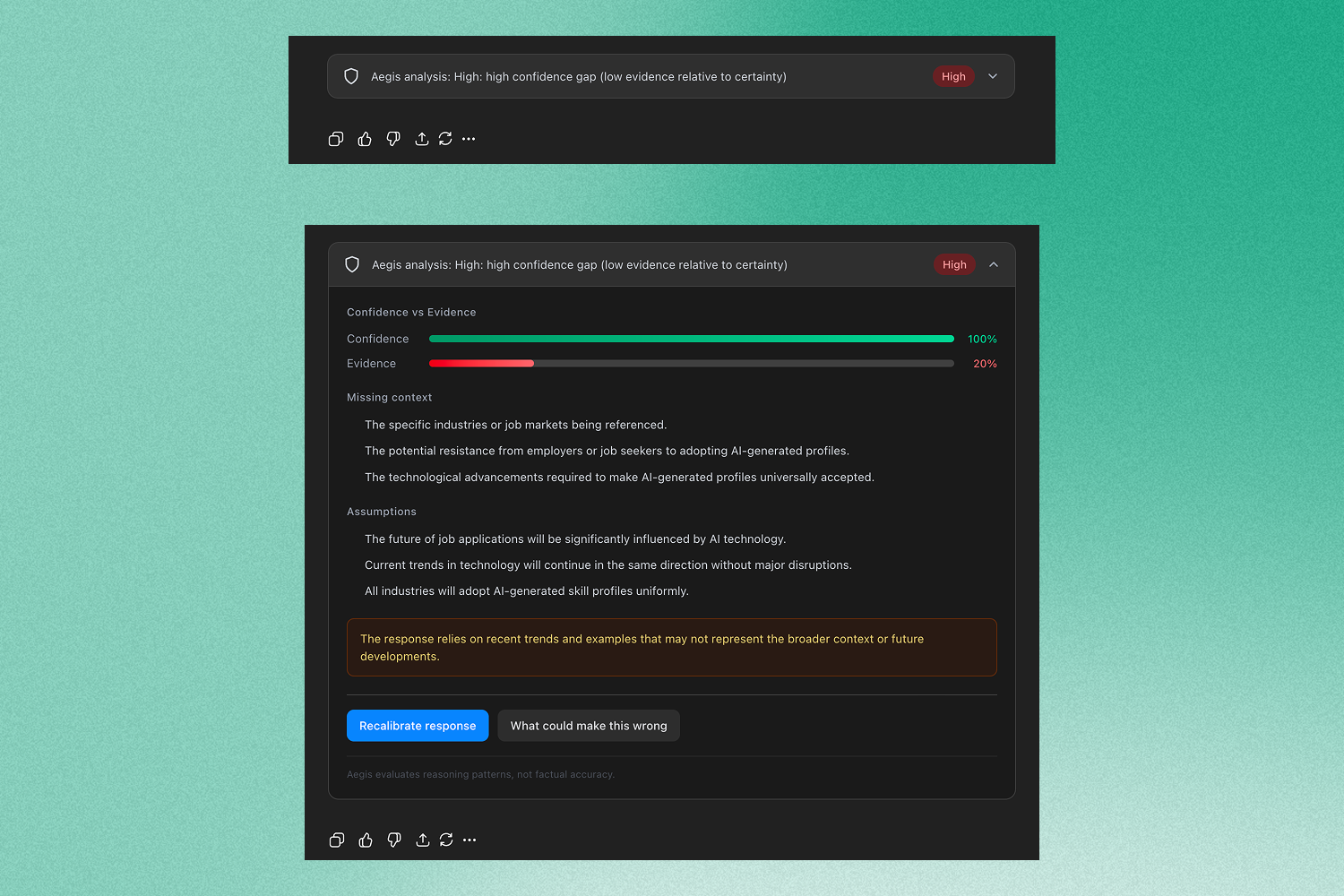
Aegis is a chrome extension that adds inline safety analysis directly under each ChatGPT response.
For every reply, Aegis:
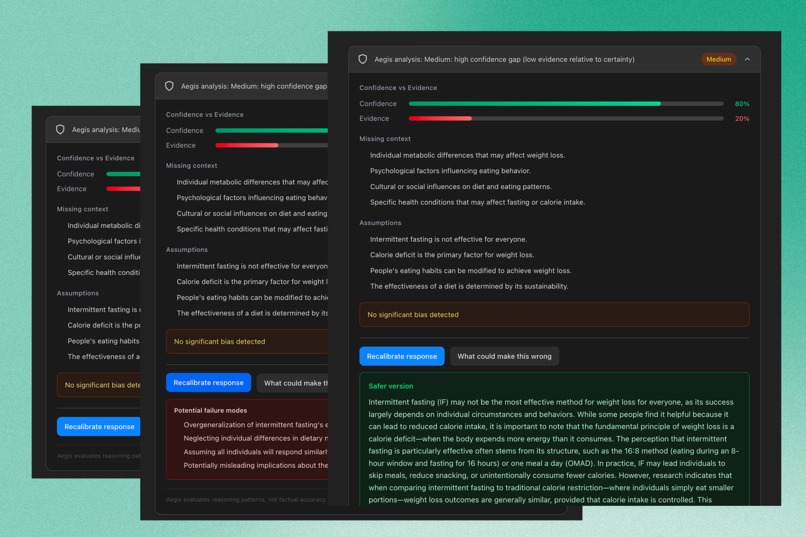
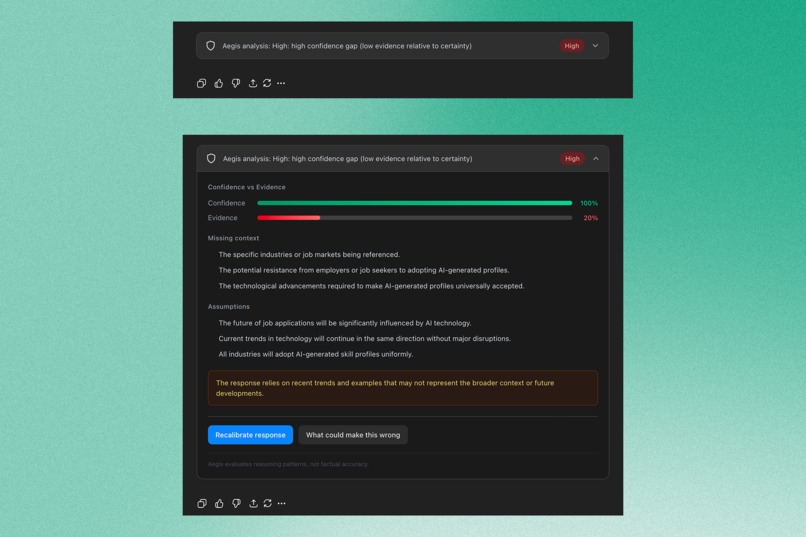
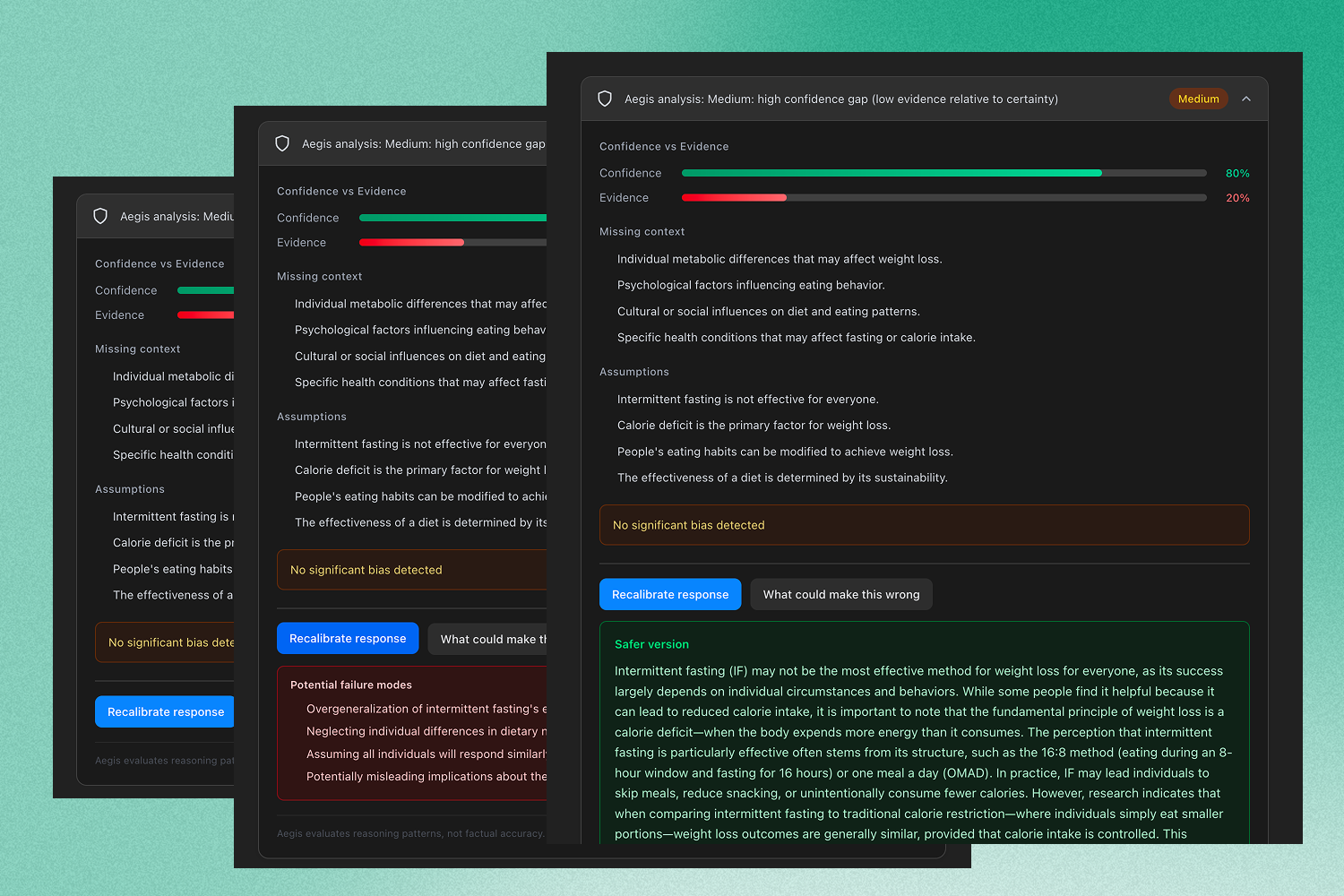
- Assigns a risk level (Low / Medium / High)
- Displays a confidence vs. evidence meter
- Extracts assumptions
- Identifies missing context
- Surfaces potential bias
- Lists failure modes
- Offers a recalibrated version that better aligns certainty with support
- Provides a one-click “What could make this wrong?” exploration
Rather than blocking content or restricting usage, Aegis helps users judge when to trust AI to unsurface invisible risks.
How we built it
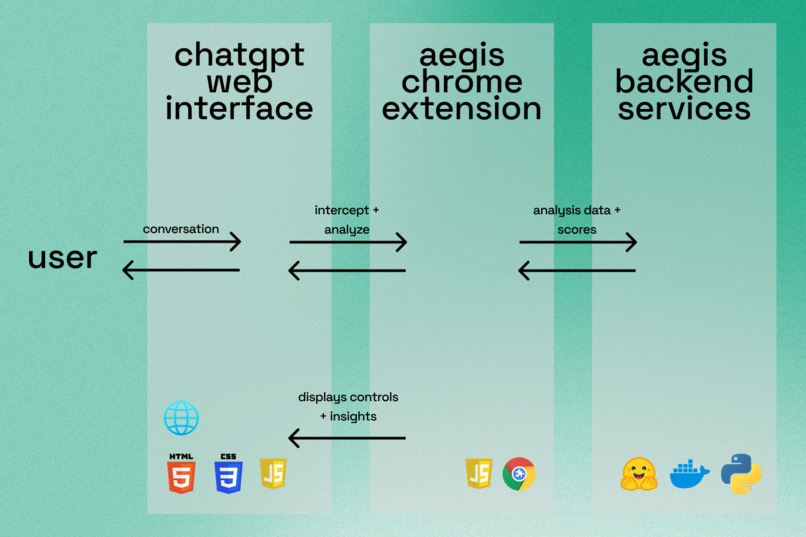
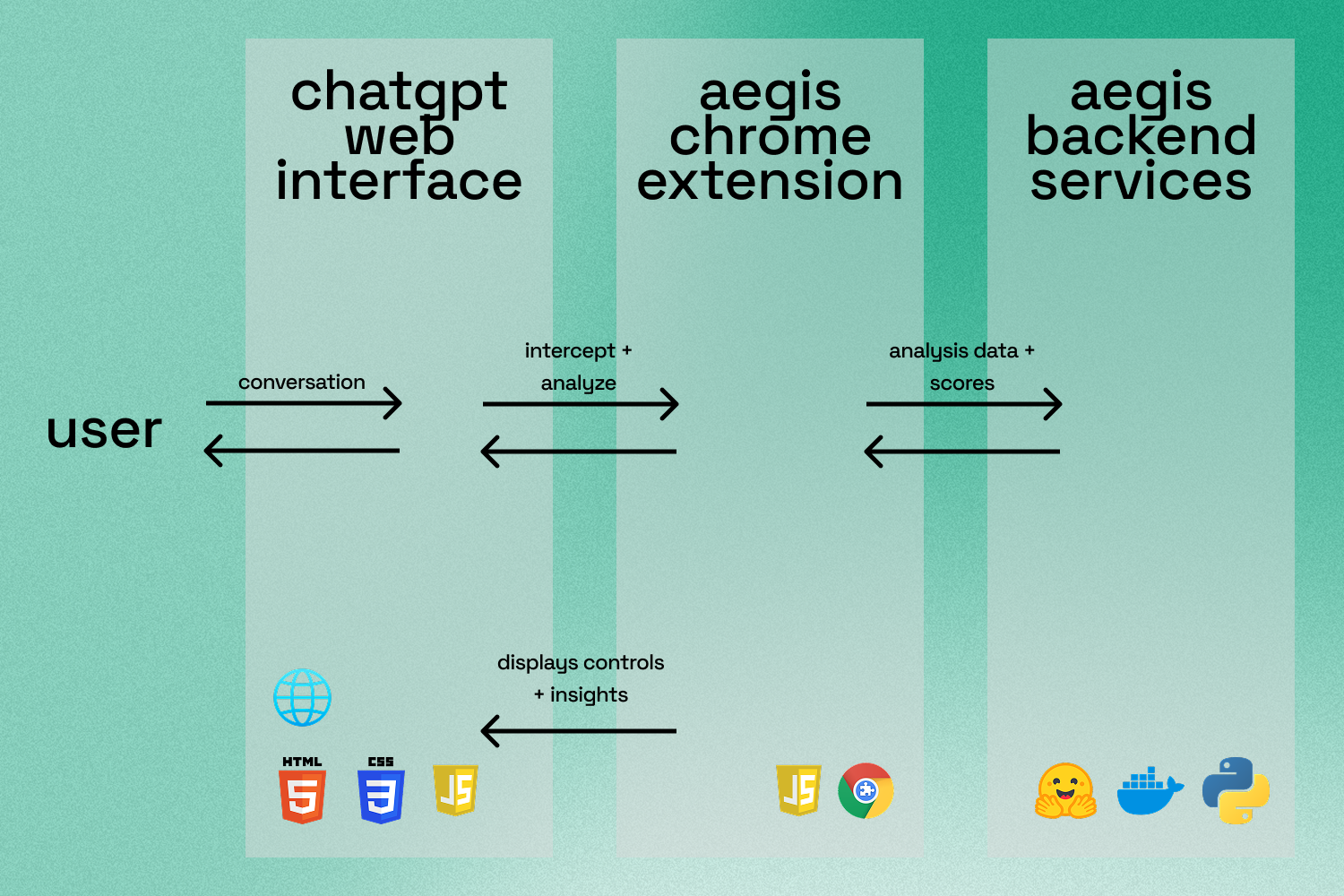
Aegis uses a layered safety architecture pipeline combining heuristics, semantic scoring, and LLM extraction.
First, rule-based heuristics detect certainty language, evidence signals, and high-risk domain keywords. Next, sentence-transformers (all-MiniLM-L6-v2) is used to generate embeddings and estimate semantic confidence. Then, GPT-4o-mini extracts structured analysis including assumptions, missing context, bias, and failure modes. A hybrid risk engine then calculates a confidence-evidence gap.
Finally, Aegis can generate a recalibrated version of the response that better aligns certainty with support.
Challenges we ran into
This was a one-person project, meaning every design, technical, and architectural decision had to be made alone under time pressure.
Midway through the hackathon, I pivoted entirely. My original idea was a mobile app that analyzed extracted social media content. However, I quickly ran into extraction limitations from social platforms. Without reliable content access, the core concept became infeasible. By Saturday afternoon, I made the decision to scrap the idea and rebuild from scratch.
The biggest technical challenge was calculating confidence and evidence scores realistically within a hackathon timeframe. Initially, I considered pure keyword matching and rule-based logic, but that approach felt too rudimentary. I explored research on LLM calibration techniques and found more sophisticated hybrid scoring approaches, but implementing them fully would have required far more time.
I ended going with a hybrid system that combines heuristic signals, semantic embedding-based scoring, and LLM structured extraction.
Accomplishments that we're proud of
- I was able to complete and submit a project to a hackathon solo :)
- Built and deployed a fully functional Chrome extension
- Successfully pivoted and rebuilt a completely new project mid-hackathon Most importantly, Aegis directly tackles the problem I had in mind: making overconfidence visible.
What we learned
This was my first time building a Chrome extension, which required learning DOM observation and injecting inline UI into dynamic streaming responses. Working with sentence-transformers was also new to me and it gave me a deeper understanding of semantic similarity, embeddings, and complexity of measuring confidence in generated text.
What's next for Aegis
I hope to publish a stable, low-latency version of the app onto the Chrome Web Store so inline analysis is faster. I also hope to improve the scoring calculations with expanding the app beyond just ChatGPT.



Log in or sign up for Devpost to join the conversation.