-
-
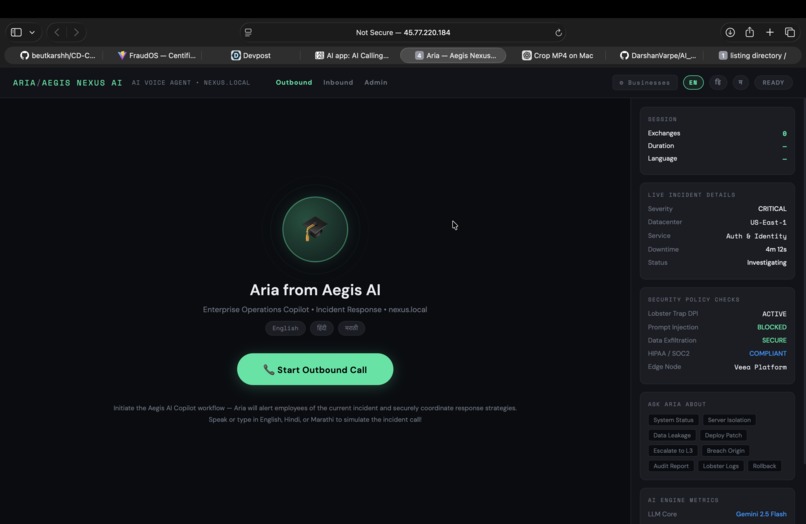
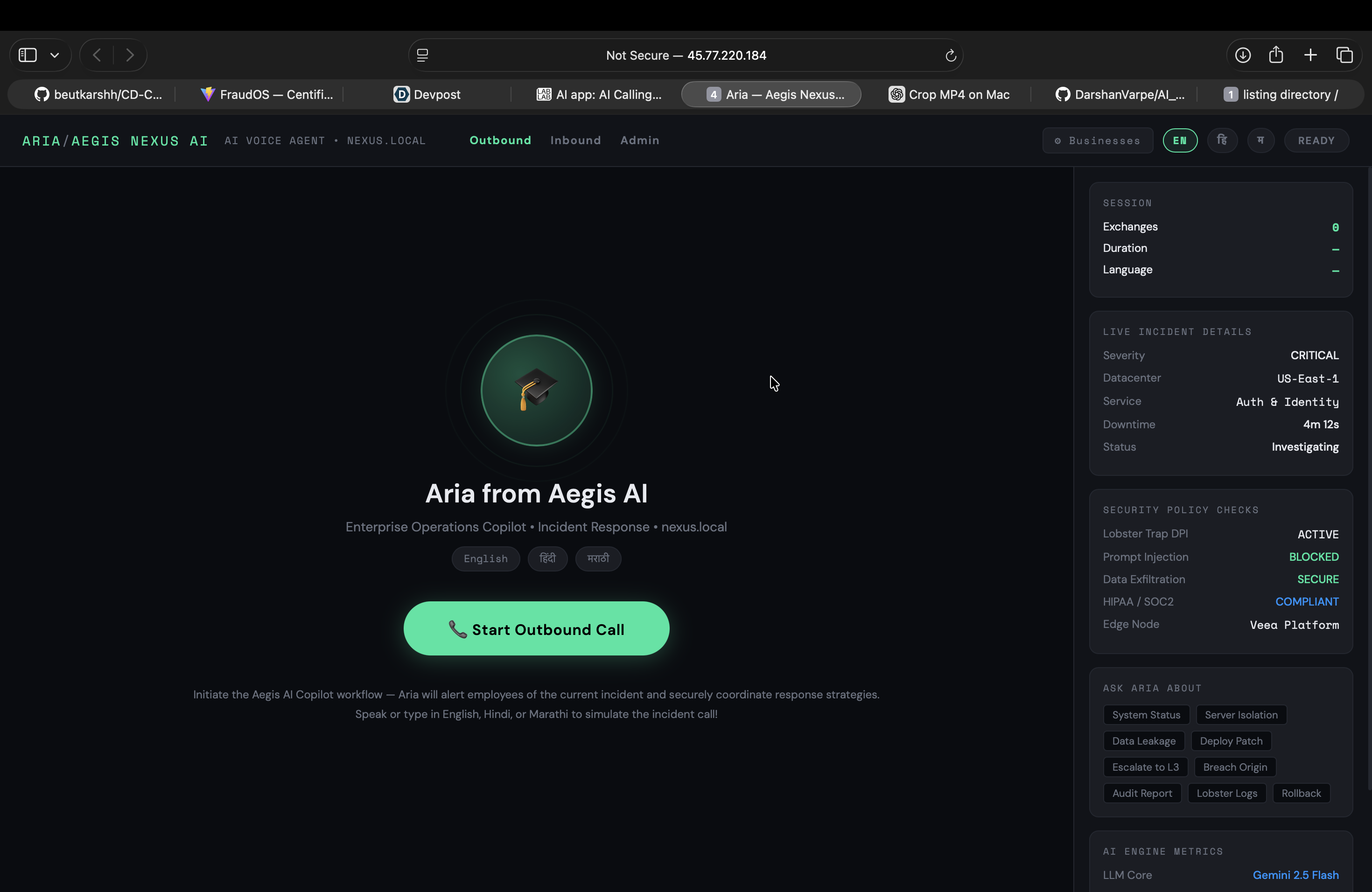
Outbound home call demo
-
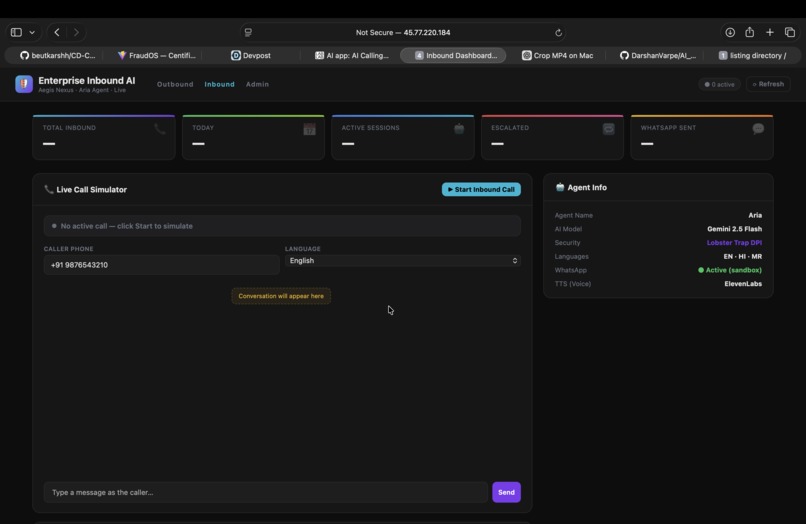
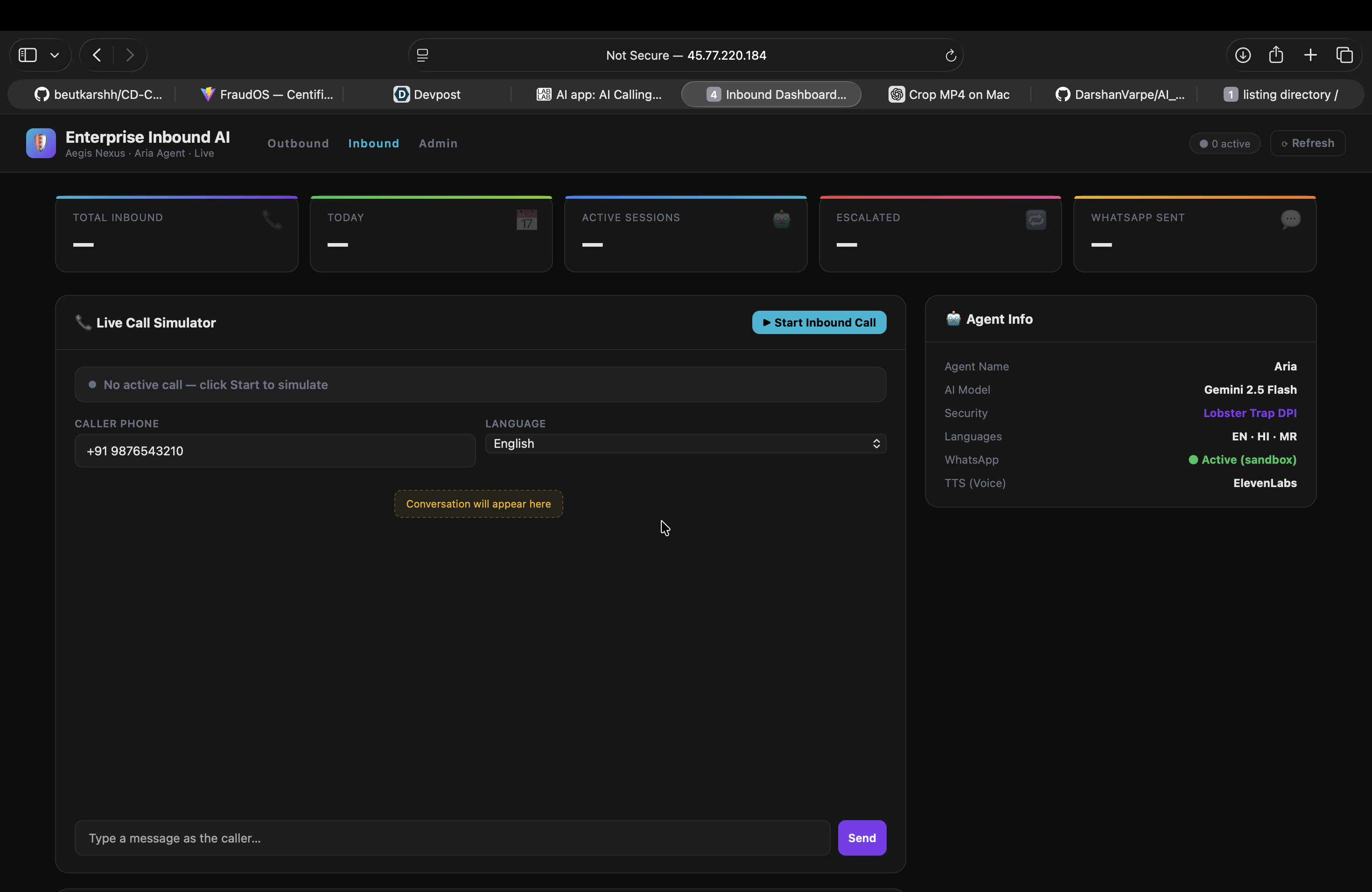
inbound
-
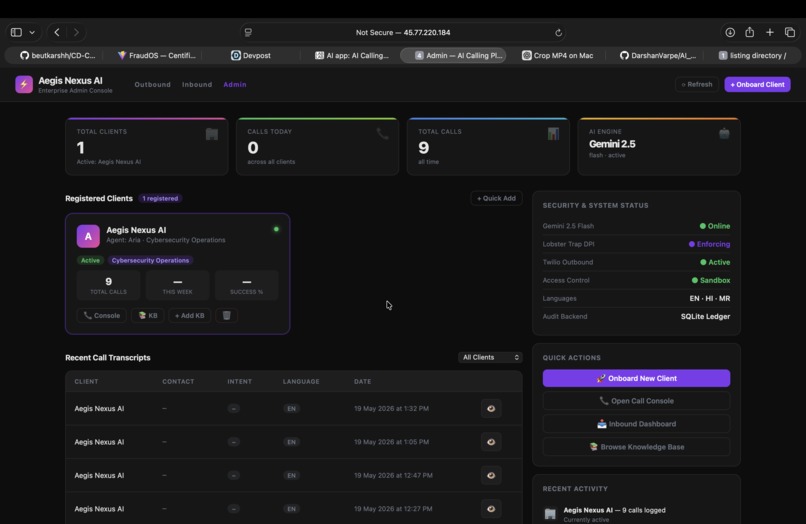
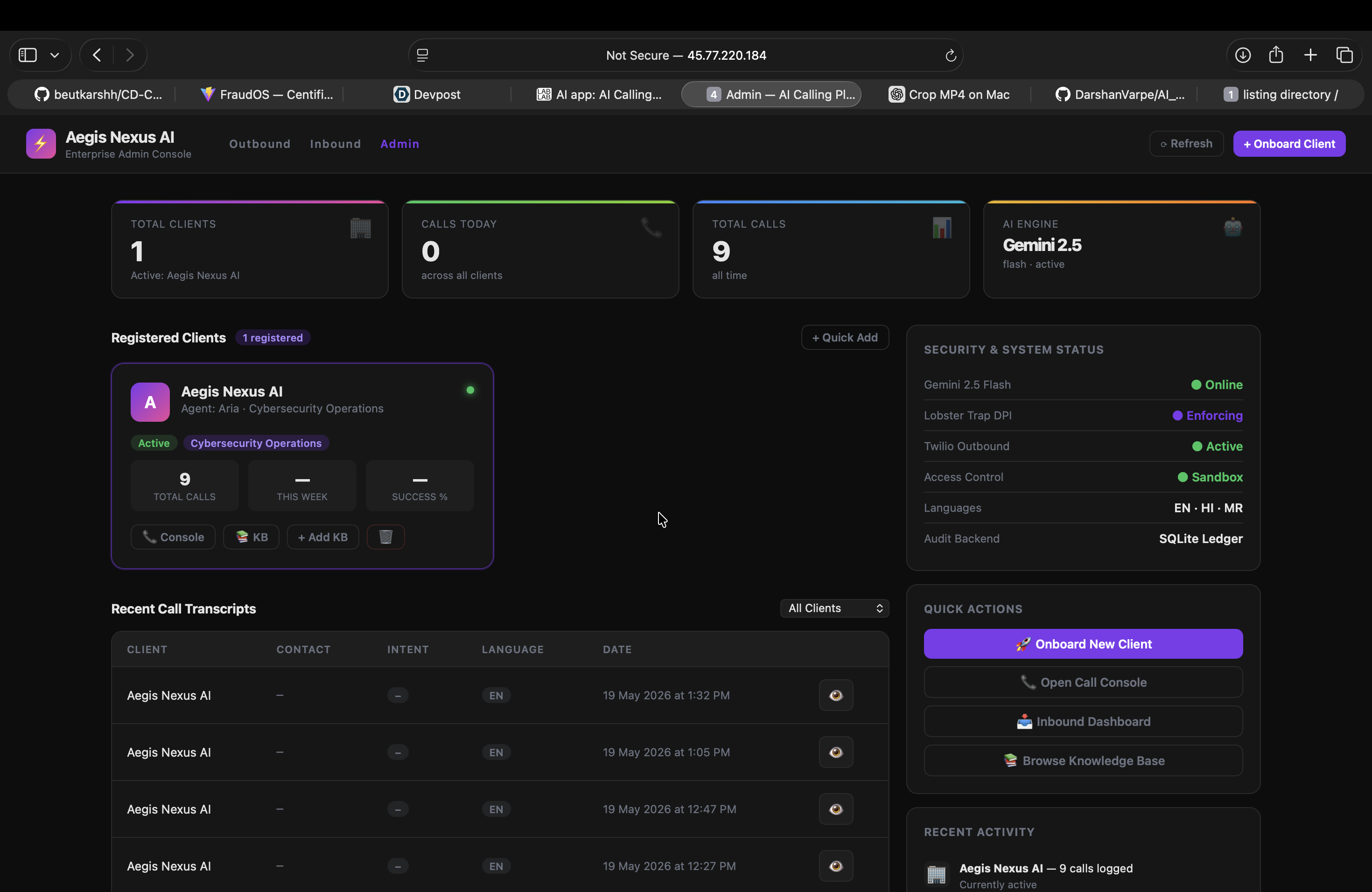
Admin
💡 Inspiration
It’s 3:00 AM. A critical zero-day exploit just breached the company’s primary authentication server. The SOC dashboard flashes red, PagerDuty fires off an alert, and an urgent email is dispatched to the IT team.
But there’s one massive problem... the on-call engineer is asleep.
In 2026, enterprise server downtime costs an average of $5,600 every single minute. A thirty-minute delay waiting for a human to wake up, read an email, and log into a VPN just cost the company over $150,000. I realized that while companies use highly advanced AI to detect threats, they still rely on passive, 1990s technology (email/Slack) to get human authorization to fix them.
I built Aegis Nexus AI to fix the most broken part of enterprise security: the human communication bottleneck.
🤖 What it does
Aegis Nexus AI is an autonomous, real-time security operations copilot. When a critical incident occurs, Aegis doesn't send an email. It picks up the phone.
My AI agent, Aria, calls the on-call engineer on their actual phone. She:
- Explains the exact threat in plain, spoken language.
- Answers complex technical questions in real-time.
- Uses Gemini function-calling to autonomously query databases or check server statuses mid-conversation.
- Secures verbal authorization to deploy security patches.
- Dispatches post-call crash logs to the engineer's WhatsApp for compliance auditing.
I reduce critical incident response time from 30+ minutes down to under 60 seconds.
⚙️ How I built it
To make Aria feel like a real human, I couldn't rely on standard, high-latency voice bots. I had to build a highly synchronized, event-driven architecture:
- The Brain (Logic & Reasoning): I utilized Google Gemini 2.5 Flash for its massive context window and rapid intent detection. Gemini natively handles all function-calling (e.g.,
search_threat_intel,escalate_to_level3). - The Ears (Real-Time STT): I bypassed standard Twilio latency by architecting a continuous WebSocket bridge. I stream raw 8kHz mulaw audio directly into the Speechmatics Real-Time API for near-zero latency transcription.
- The Voice (TTS): I integrated ElevenLabs Multilingual V2, allowing Aria to seamlessly auto-detect and speak in English, Hindi, and Marathi depending on the engineer's preference.
- The Backbone (Orchestration): The entire system is orchestrated via a custom Node.js/Express.js backend, capable of batch-processing up to 750 concurrent calls per day.
- The Infrastructure: For high-concurrency read/writes during simultaneous live calls, I utilize SQLite in WAL (Write-Ahead Logging) mode, deployed live on a Vultr Cloud Compute production instance.
🚧 Challenges I ran into
- The "Barge-in" Problem: Standard telephony APIs force users to wait until the AI finishes speaking before replying. I solved this by processing raw audio packets locally via WebSockets. I wrote custom logic to instantly kill the ElevenLabs audio stream the exact millisecond Speechmatics detects the user interrupting, enabling true human "barge-in."
- Concurrency & Database Locks: Handling multiple active phone calls simultaneously crashed my standard SQLite setup due to database locks. I overcame this by implementing SQLite Write-Ahead Logging (WAL) and optimizing
queueProcessor.jswith exponential backoff. - Voice AI API Budgets: Running 750 enterprise calls a day across 3 languages burns through ElevenLabs character limits fast. I engineered a custom
CharacterManagerthat dynamically tracks daily budgets and can "borrow" character limits from different language pools in real-time.
🏆 Accomplishments that I'm proud of
- Achieving Human-Like Latency: Successfully bridging Twilio Media Streams with Speechmatics via WebSockets to completely eliminate robotic pauses during phone calls.
- Dynamic Function Calling: Aria isn't a state machine ("Press 1 for threats"). Because I hooked Gemini’s function calling directly into the voice loop, engineers can lead conversations naturally and ask Aria to perform tasks dynamically.
- Zero-Configuration Multilingualism: The system accurately detects when a user switches from English to Hindi or Marathi and adapts its voice model on the fly.
📚 What I learned
I learned that combining LLMs with real-time telecommunications is heavily dependent on network optimization. Processing text is easy, but maintaining bi-directional audio streams over WebSockets while waiting for LLM generation requires aggressive buffering and state management.
🚀 What's next for Aegis Nexus AI
- Slack/Teams Integration: Pushing live transcripts of phone calls into enterprise communication channels as conversations happen.
- Custom Enterprise Voice Cloning: Allowing SOC teams to clone the voice of their actual Chief Information Security Officer (CISO) for emergency automated calls.
- Multi-Tenant SaaS: Transitioning the Vultr SQLite architecture to PostgreSQL to support multi-tenant enterprise onboarding.
Built With
- elevenlabs
- express.js
- google-gemini
- node.js
- speechmatics
- sqlite
- twilio
- vultr
- websockets


Log in or sign up for Devpost to join the conversation.