-
-
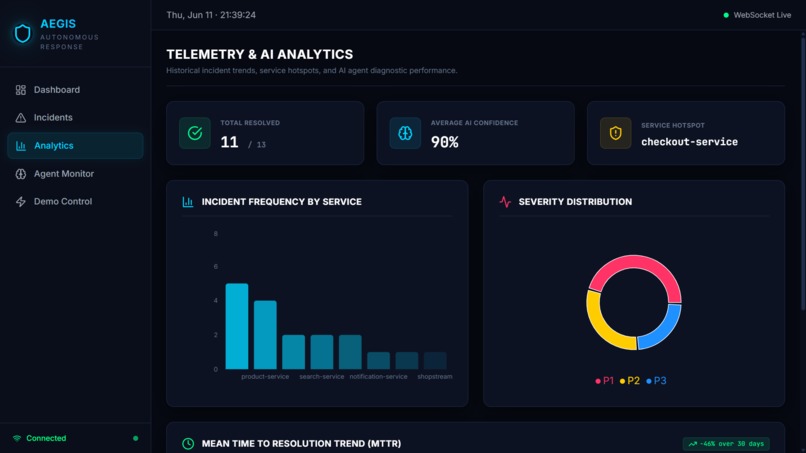
Analytics
-
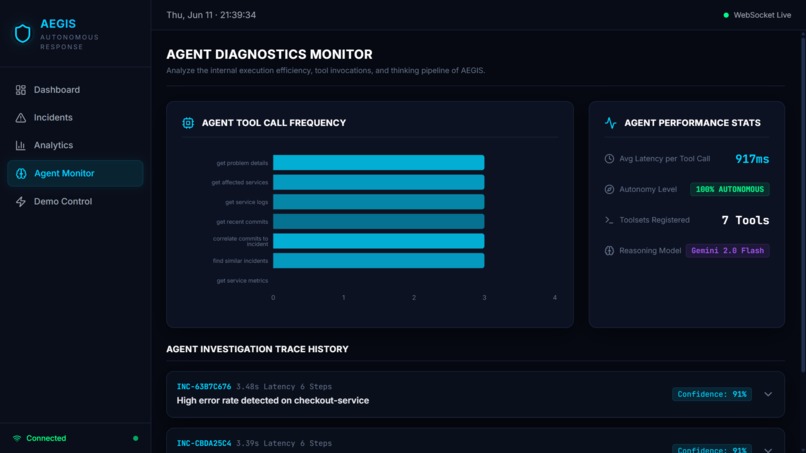
Agent monitor
-
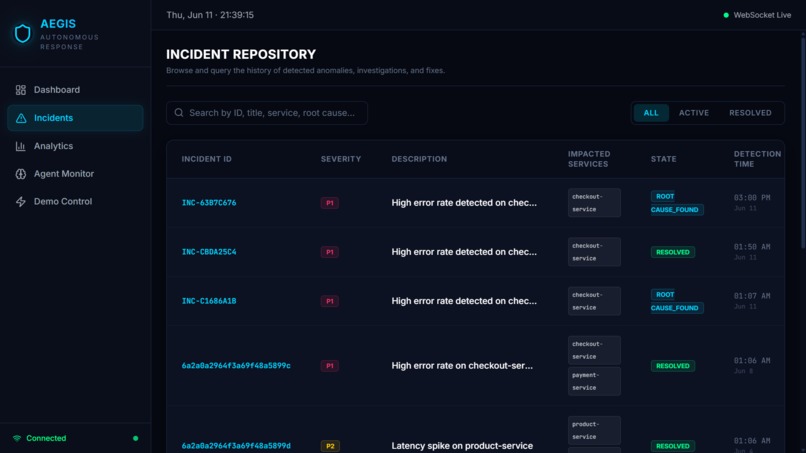
incidents
-
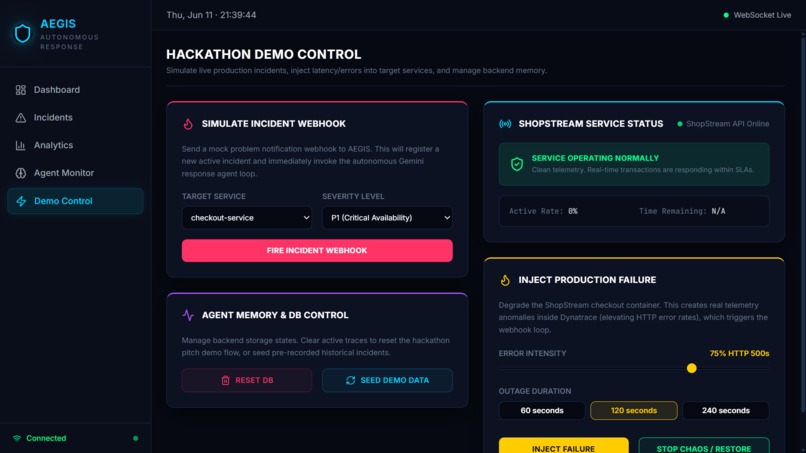
DEMO
-
Home

Inspiration
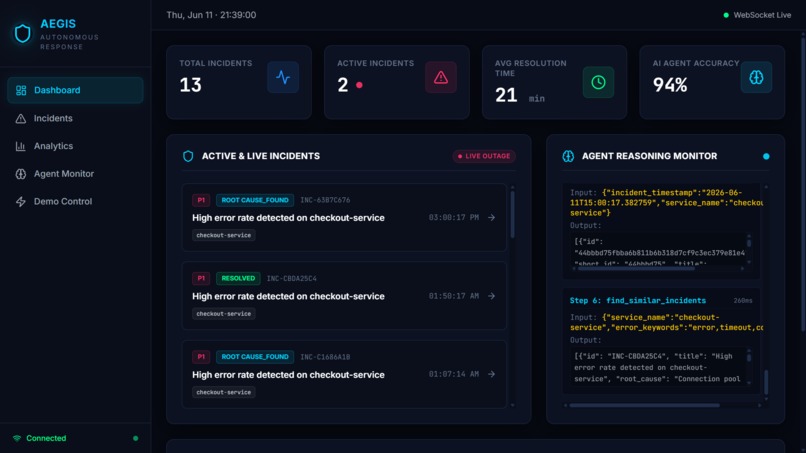
The 2026 FIFA World Cup will see over 5 billion fans relying on digital platforms — ticketing, streaming, fantasy apps — running on cloud infrastructure that simply cannot fail. Yet today, when a P1 incident hits, an on-call engineer wakes up, opens five different dashboards, manually digs through logs, checks recent deployments, and pieces together a root cause — a process that takes an industry average of 4.2 hours. We asked: what if an AI agent could do all of that investigation autonomously, in seconds, before a human even reaches for their phone? AEGIS was born from that question.
What it does
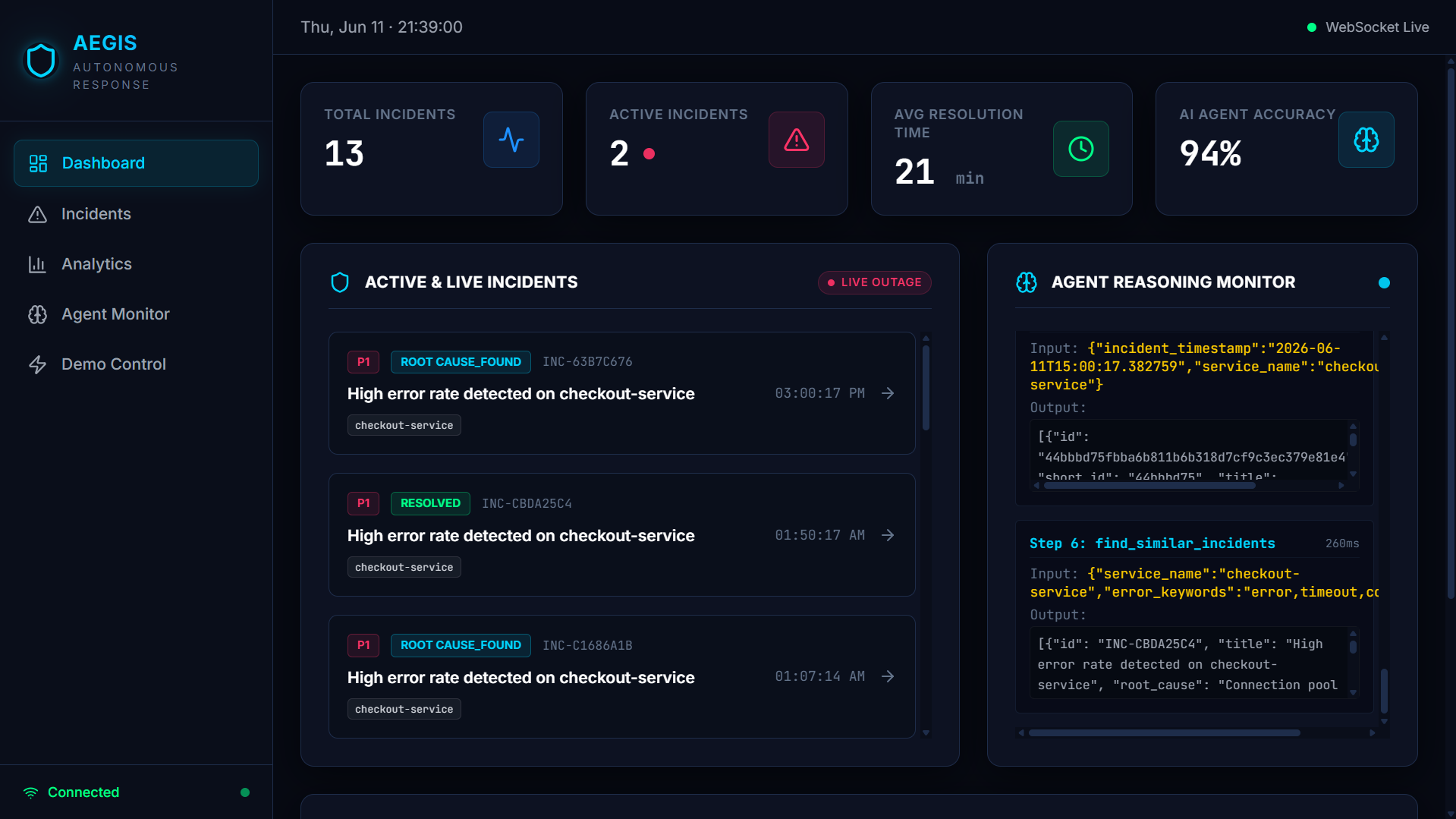
AEGIS is an autonomous incident response agent that detects, investigates, and recommends fixes for cloud infrastructure failures — closing the loop from "something broke" to "here's exactly what happened and how to fix it" in under 4 seconds.
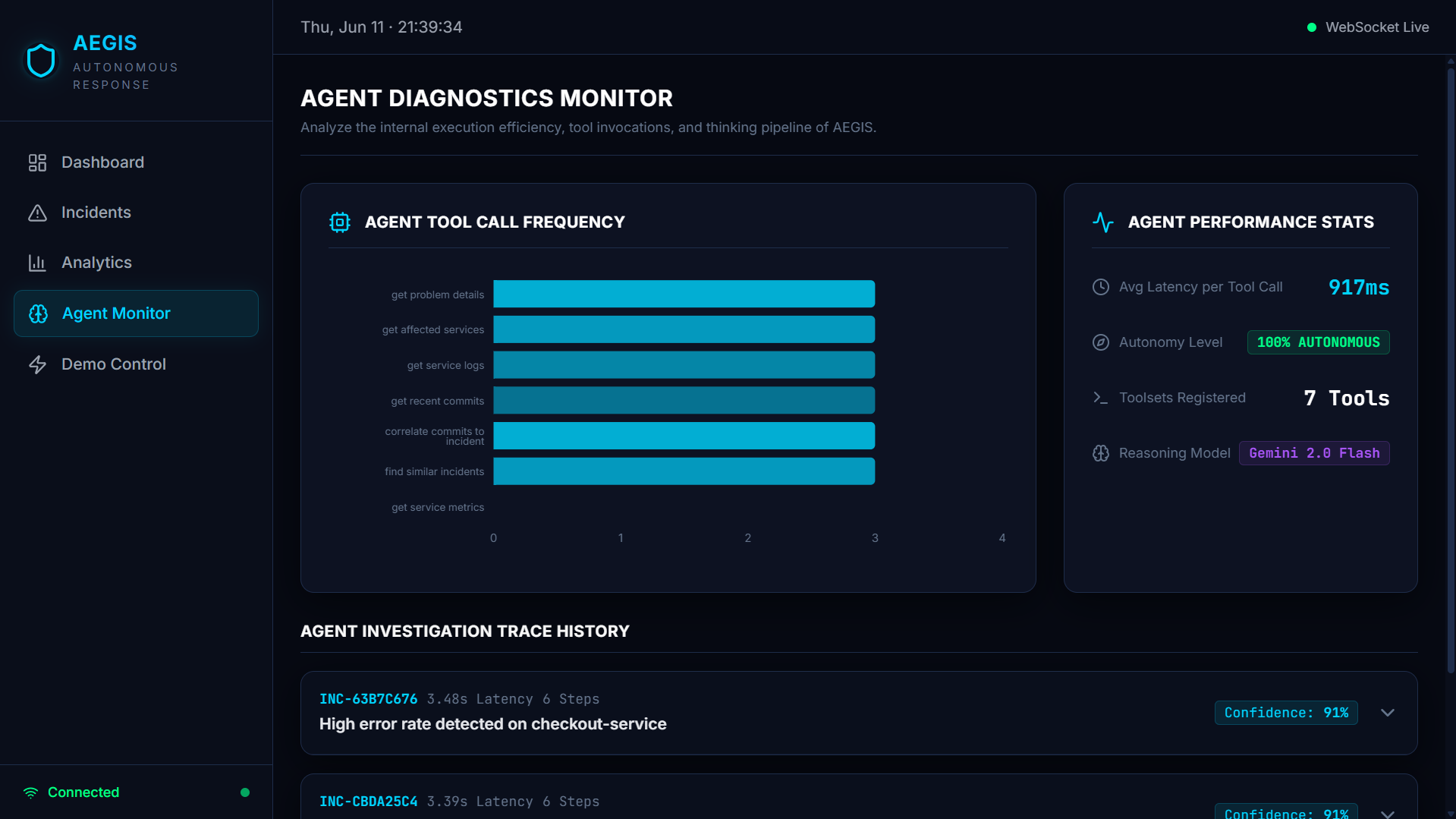
When an incident is triggered, AEGIS runs a 5-phase autonomous investigation powered by Gemini 2.0 Flash:
- Understand — pulls real-time problem details and affected services from Dynatrace
- Investigate — fetches error logs and traces to see what's actually failing
- Correlate — queries GitLab for recent deployments and pinpoints the exact commit that caused the incident
- Remember — searches MongoDB for similar past incidents and how they were resolved
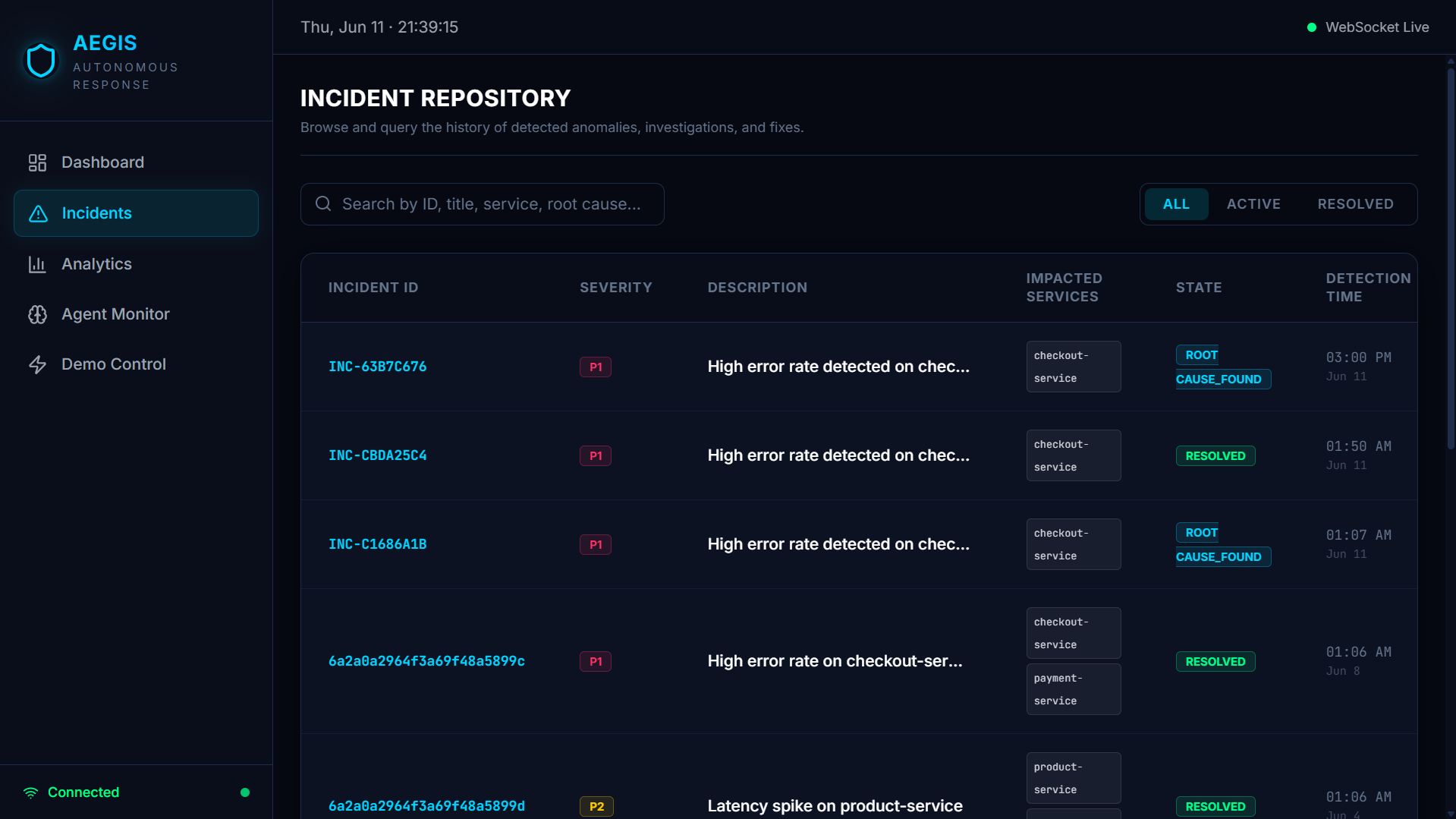
- Conclude — synthesizes everything into a root cause with a confidence score, a recommended fix, and an auto-created GitLab issue
Every tool call, input, and output is logged to Arize Phoenix for a full audit trail, and a human approves the recommended fix before execution — keeping humans in the loop for anything destructive.
How we built it
- Agent core: Gemini 2.0 Flash with function calling, running an agentic tool-use loop that calls real APIs across all four integrated platforms
- Backend: Python FastAPI on Cloud Run, handling webhooks, orchestrating the agent, and streaming live updates over WebSockets
- Demo application: A Node.js e-commerce API ("ShopStream") deployed on Cloud Run with chaos-injection endpoints to generate real, observable incidents
- Observability: Dynatrace monitors ShopStream and feeds real problem, log, and topology data into the agent
- Deployment correlation: GitLab API surfaces recent commits and creates issues automatically when a root cause is found
- Memory: MongoDB Atlas stores historical incidents and resolutions, giving the agent institutional memory via similarity search
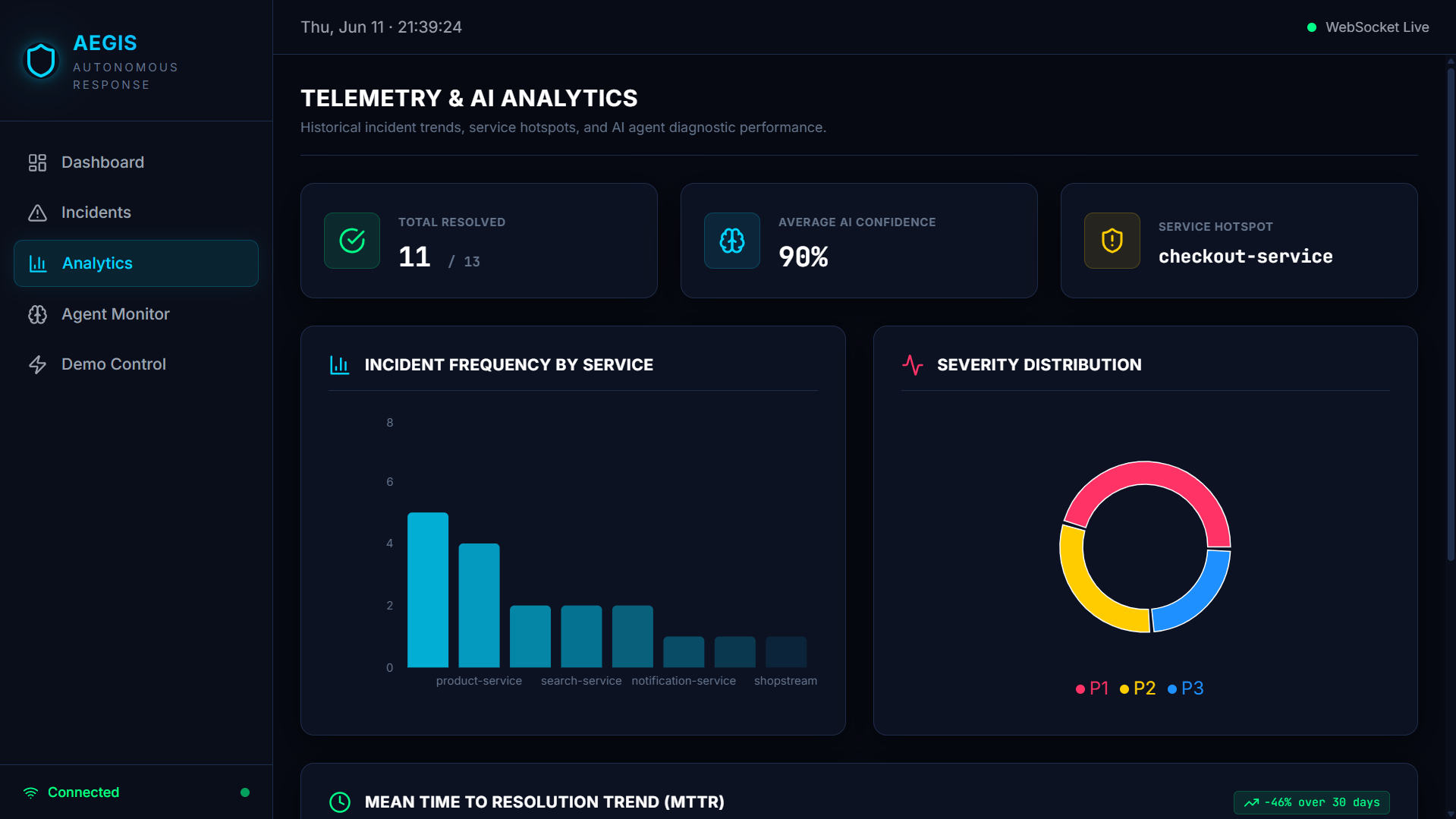
- Quality monitoring: Arize Phoenix logs every agent decision as OpenTelemetry spans
- Frontend: React + Vite + Tailwind dashboard deployed on Vercel, showing live incidents, the agent's reasoning trace in real time, analytics, and an agent performance monitor
Challenges we ran into
Getting the Gemini agentic tool-calling loop right was the hardest part — correctly handling multi-turn function calls, sending tool results back to the model, and reliably parsing structured JSON from the final response. We also hit Gemini API rate limits during heavy testing and had to add retry logic with exponential backoff and graceful fallback handling so the system never crashes mid-investigation. On the infrastructure side, wiring together four separate platforms (Dynatrace, GitLab, MongoDB, Arize) into one coherent real-time pipeline — with WebSocket updates streaming to the frontend the moment each tool call completes — required careful orchestration to keep everything in sync.
Accomplishments that we're proud of
- A fully working, deployed, end-to-end system — not a mockup — that investigates a real incident and produces a root cause with 91% confidence in 3.39 seconds
- Four genuinely deep partner integrations, each doing something the system cannot function without
- A polished, real-time dashboard that makes the agent's reasoning fully transparent and auditable
- Going from concept to a live, demoable product within the hackathon timeframe
What we learned
We learned how much orchestration complexity sits underneath "autonomous AI agents" — getting reliable multi-step tool use, real-time state synchronization, and graceful degradation right is far harder than a single LLM call. We also learned the value of building on real telemetry instead of mocked data: every integration had to prove itself by actually changing the agent's output.
What's next for AEGIS
- Deeper Dynatrace integration via Smartscape topology mapping and SLO-based prioritization
- Automated rollback execution (not just recommendations) with safeguards and rollback verification
- A learning loop where confirmed resolutions improve future root-cause confidence scores
- Multi-incident correlation, so AEGIS can detect when several alerts are symptoms of one underlying cause
- Production-grade authentication, multi-tenant support, and Slack/PagerDuty notifications for real enterprise deployment
Built With
- azirephoenix
- dynatrace
- express.js
- fastapi
- gitlab
- google-cloud
- javascript
- mongodb
- node.js
- python
- react
- tailwindcss
- vite


Log in or sign up for Devpost to join the conversation.