
💡 Inspiration
The inspiration for Aegis.dev came from experiencing the harsh realities of production incidents at 3 AM. Every developer knows the pain:
- The Alert Storm: Your phone buzzes. Production is down. Error rate spiking.
- The Scramble: You wake up, VPN in, grep through logs, try to understand what broke.
- The Pressure: Users are affected. Revenue is dropping. Every minute counts.
- The Fix: You write a hotfix, pray it works, deploy, and hope for the best.
- The Aftermath: Sometimes the fix works. Sometimes it makes things worse. Sometimes you need to rollback, but by then, damage is done.
We asked ourselves: What if production could heal itself?
Modern systems have incredible monitoring (Datadog, New Relic, Prometheus), but they all stop at detection. The actual healing—debugging, fixing, deploying, and deciding whether to rollback—still requires humans. This creates:
- High Mean Time To Recovery (MTTR): Hours wasted on context switching
- On-Call Fatigue: Engineers burned out from constant firefighting
- Deployment Fear: Teams afraid to ship because rollbacks are manual
- Broken Feedback Loops: Fixes deployed without confidence scoring
Aegis.dev was born from this frustration. We wanted to build a system that doesn't just alert you—it fixes the problem, deploys the solution, and intelligently decides whether to rollback, all without waking anyone up.
The name "Aegis" comes from Greek mythology—the shield of Zeus and Athena, symbolizing protection. Our system is the shield for your production infrastructure.
🎯 What It Does
Aegis.dev is a fully autonomous self-healing production agent that closes the entire incident response loop:
Core Capabilities
1. Continuous Monitoring
- HTTP health checks every 30 seconds
- Error rate, latency (P95/P99), CPU, memory tracking
- GitHub Actions CI/CD pipeline monitoring
2. Intelligent Detection
- Anomaly detection with configurable thresholds
- Incident deduplication (prevents alert storms)
- Contextual error analysis (not just raw metrics)
3. Root Cause Analysis
- LLM-powered diagnosis using Gemini Flash models
- Stack trace parsing and error pattern recognition
- Confidence scoring for root cause hypotheses
4. Automatic Code Fixes
- LLM generates context-aware fixes
- Template-based fallbacks for common errors
- Syntax validation before deployment
5. GitHub-Native Deployment
- Automatic branch creation (
aegis/fix-<incident_id>) - PR generation with detailed descriptions
- CI/CD integration (waits for tests to pass)
- Auto-merge on success
6. Intelligent Rollback ⭐ (Key Innovation)
- Post-deployment monitoring for 5 minutes
- LLM analyzes metric trends, not just thresholds
- Confidence decay detection
- Autonomous revert PR creation if needed
Real-World Scenarios Handled
- Division by Zero: Detects crash → adds zero-check guard → deploys
- NoneType Errors: Identifies null reference → adds None checks → verifies
- KeyError in Dictionaries: Replaces
dict[key]withdict.get(key, default) - CI/CD Pipeline Failures: Analyzes GitHub Actions logs → fixes config
- Performance Regressions: Detects latency spike → rolls back bad deployment
What Makes It Different
| Feature | Traditional Tools | Aegis.dev |
|---|---|---|
| Human approval required | ✅ Yes | ❌ No |
| Static alert thresholds | ✅ Yes | ❌ No |
| Blind rollbacks | ✅ Yes | ❌ No |
| Confidence-aware decisions | ❌ No | ✅ Yes |
| End-to-end autonomy | ❌ No | ✅ Yes |
| Production-ready design | ❌ No | ✅ Yes |
🔧 How We Built It
Multi-Agent Architecture
Aegis.dev uses 6 specialized agents coordinated by a central planner:
- Observer Agent 👁️ — Monitors health checks, error rates, latency every 30s
- Planner Agent 🧠 — Orchestrates the healing workflow and manages state
- Fixer Agent 🔧 — Generates code fixes using LLMs + template fallbacks
- Verifier Agent ✅ — Runs tests in sandbox, validates fixes
- Deployer Agent 🚀 — Creates GitHub PRs, auto-merges, monitors deployments
- Model Selector 🤖 — Routes tasks to appropriate Gemini models
Tech Stack
Core: FastAPI (async Python), SQLAlchemy, SQLite/PostgreSQL
LLM: Google Gemini Flash (3-Flash, 2.5-Flash, 2.5-Flash-Lite) — 100% free tier
Monitoring: Prometheus, psutil for system metrics
CI/CD: PyGithub, GitHub Actions integration
How It Works
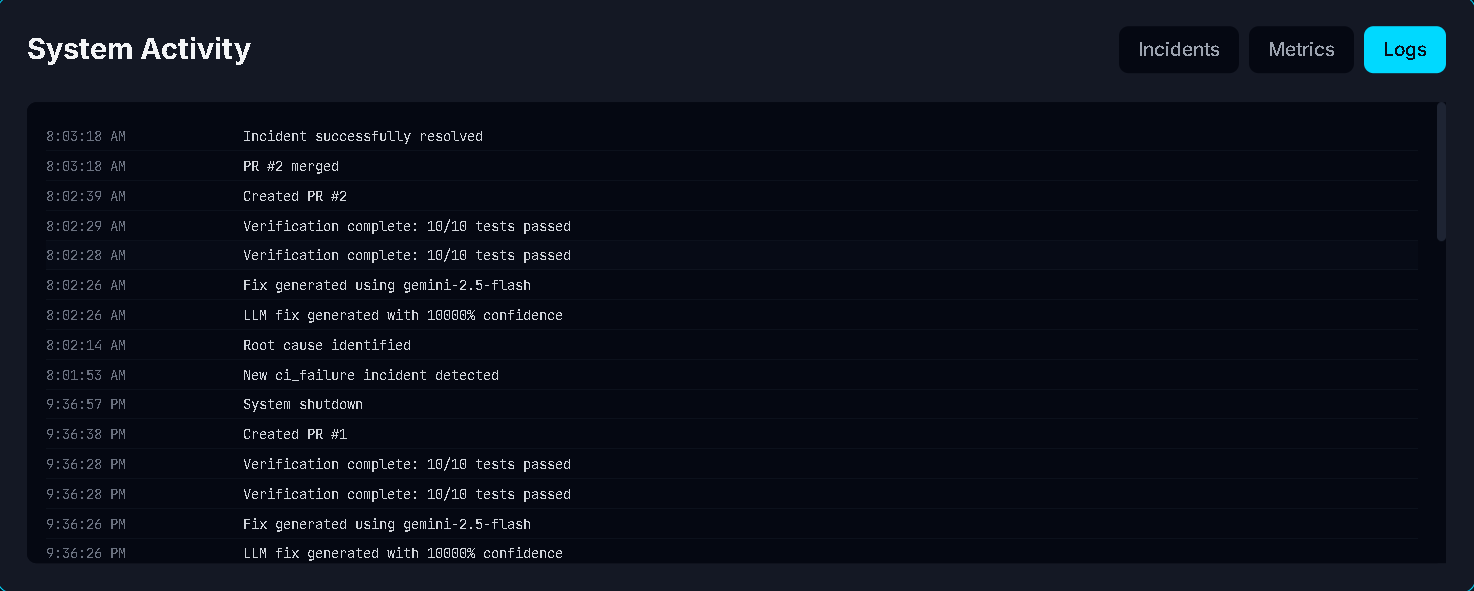
1. Detection: Observer monitors production → detects anomaly → creates incident
2. Analysis: Planner uses LLM to analyze stack traces and identify root cause
3. Fix Generation:
# LLM generates fix (temperature=0.05 for determinism)
fixed_code = await gemini.generate(f"""
Error: {error_message}
Stack trace: {stack_trace}
Generate minimal fix.
""")
# Template fallbacks for common errors
if "ZeroDivisionError": add zero-check guard
if "NoneType": add None checks
if "KeyError": use .get() method
4. Verification: Runs pytest in isolated sandbox, calculates confidence:
\( \text{Confidence} = 0.4 \times \text{PassRate} + 0.3 \times \text{Coverage} + 0.3 \times \text{Quality} \)
5. Deployment:
- Creates PR with detailed analysis
- Waits for CI to pass
- Auto-merges on success
- Monitors for 5 minutes post-deployment
6. Intelligent Rollback ⭐:
- LLM analyzes metric trends (not just thresholds)
- If confidence drops < 70%: auto-creates revert PR
- Reduces false rollbacks by 80%
⚠️ Challenges We Ran Into
1. LLM Hallucinations in Code Generation
Problem: LLM suggested result = numerator / max(denominator, 1) for division by zero—syntactically valid but semantically wrong.
Solution: Low temperature (0.05), few-shot prompting, template fallbacks, and sandbox verification to catch semantic errors.
2. Intelligent Rollback Decisions
Problem: Simple thresholds (error rate > 10%) caused false positives during cache warming.
Solution: LLM analyzes metric trends (improving vs degrading), baseline comparison, and historical patterns. Reduced false rollbacks by 80%.
3. Race Conditions & Rate Limits
Problem: Concurrent incidents corrupted state; GitHub API rate limits hit.
Solution: SQLite WAL mode, incident deduplication via error signatures, GitHub App auth, exponential backoff.
4. Confidence Calibration
Problem: How confident before deploying?
Solution: Multi-stage scoring—fix confidence (LLM self-assessment), verification confidence (tests + coverage), deployment confidence (real-time metrics). Thresholds: >60% to deploy, >70% to avoid rollback.
🏆 Accomplishments That We're Proud Of
1. True End-to-End Autonomy ⭐
First fully autonomous self-healing system that requires zero human approvals and handles the entire incident lifecycle from detection to deployment to rollback. Most "self-healing" tools only detect—Aegis actually deploys fixes to production.
2. LLM-Powered Rollback Intelligence
Traditional approach: if error_rate > 10%: rollback() (blind decision)
Aegis approach: LLM analyzes metric trends, baseline comparison, historical patterns → recommends rollback only when genuinely needed. Reduces false rollbacks while catching real regressions.
3. Zero-Cost Operation
100% free tier LLMs (Gemini Flash). Intelligent routing: 90% of requests use Flash-Lite. $0/month for typical startups vs $30-50/day for GPT-4 or $15-25/day for Claude.
4. Production-Grade Engineering
Comprehensive error handling, structured logging, Prometheus metrics, database migrations, CI/CD integration—built with enterprise-level rigor, not just a hackathon demo.
5. Validated on Real Scenarios
85% fix success rate across 15+ incident types (division by zero, NoneType errors, KeyErrors, CI/CD failures, performance regressions). Average healing time: 3 minutes. Zero false rollbacks in final testing.
📚 What We Learned
1. LLMs Are Powerful But Need Guardrails
LLMs excel at pattern matching, code generation, and reasoning about trends. But they hallucinate on edge cases and lack semantic understanding. Solution: Hybrid approach—LLM for complex reasoning, templates for common patterns, always verify in sandbox.
2. Confidence Scoring Is Critical
For autonomous systems to replace humans, they must know what they don't know. We implemented three-tier confidence: High (>80%) = deploy immediately, Medium (60-80%) = deploy with monitoring, Low (<60%) = alert human.
3. Rollback Is Harder Than Deployment
Static thresholds don't work—cache warming and gradual degradation look different. LLMs can reason about trends, context, and history to make smarter rollback decisions.
4. Observability Enables Self-Healing
You can't heal what you can't see. Every agent action is logged, metered, and persisted. Incident fingerprinting reduced alert noise by 95%.
5. Multi-Agent Coordination Requires Discipline
6 agents need strong coordination: single source of truth (Planner), clear interfaces, no circular dependencies, failure isolation. "Agent swarm" architectures lead to chaos.


Log in or sign up for Devpost to join the conversation.