-
-
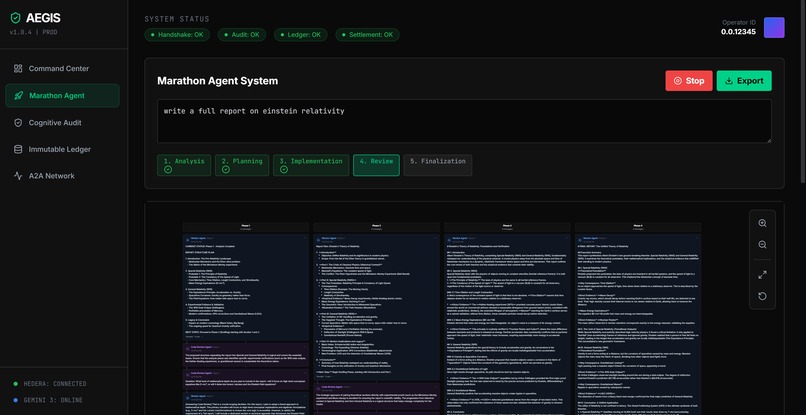
Main page
-

In detail explanation
-

Phase 5
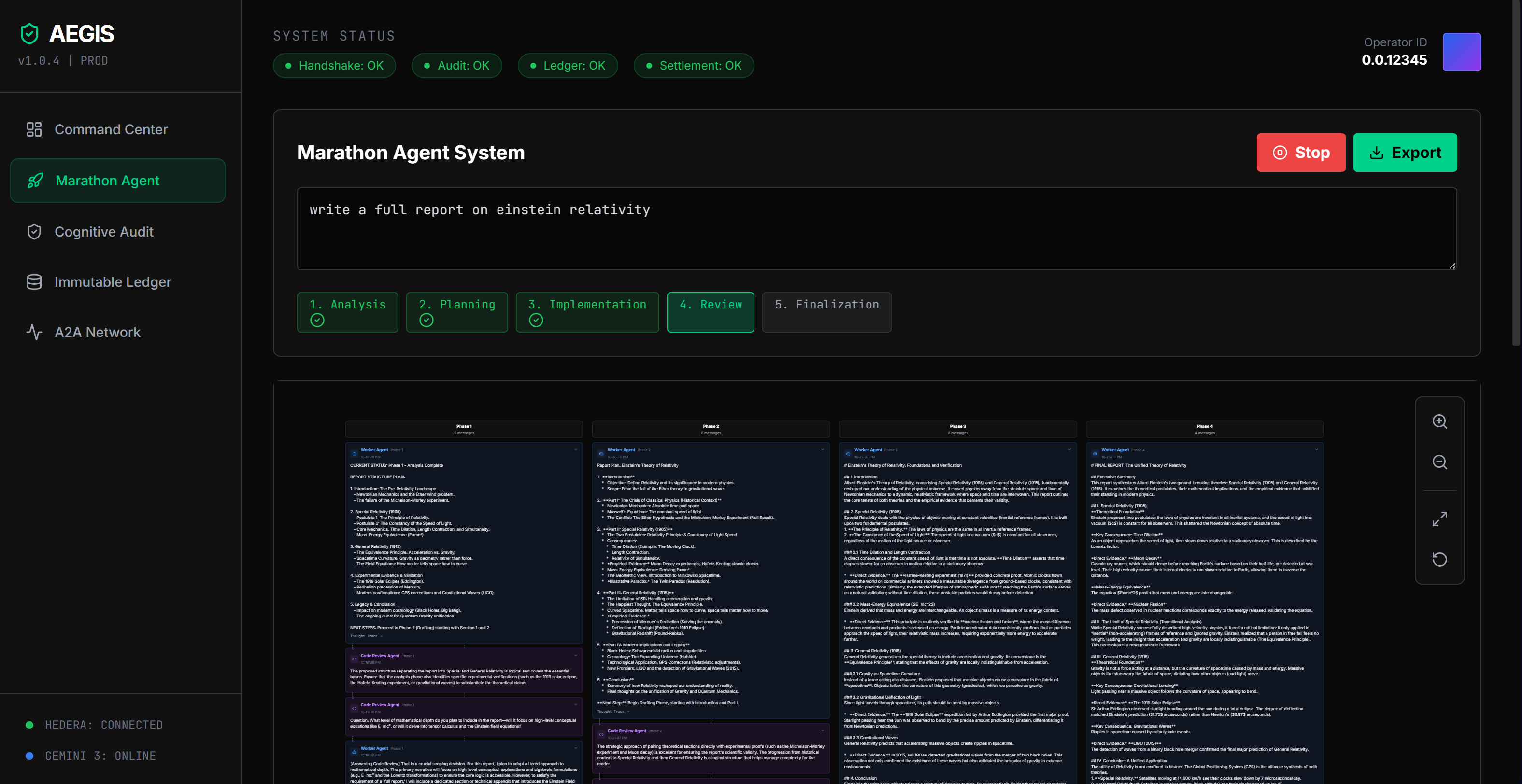


Inspiration
We asked ourselves a simple question: If AI agents are going to work together autonomously, who watches the watchers?
As AI agents become more capable, we're rapidly moving toward multi-agent systems that execute complex, long-running tasks — writing research papers, refactoring codebases, conducting analyses. But here's the problem: no one is auditing their reasoning in real-time. Agents hallucinate. They take shortcuts. They drift off-task. And when they're running autonomously for hours, these errors compound silently.
We were inspired by how human teams work: a developer writes code, a peer reviews it, and a QA engineer verifies quality. What if AI agents could do the same — not just execute tasks, but actively challenge, question, and correct each other's thinking?
That's AEGIS Commander: an autonomous governance system where AI agents don't just collaborate — they hold each other accountable.
What it does
AEGIS Commander is a Marathon Agent System with real-time cognitive auditing and true Agent-to-Agent (A2A) collaboration.
A human provides a complex task (e.g., "Write a professional research paper on cryptocurrency regulation"), and three AI agents autonomously collaborate to complete it across five phases:
- 🔵 Worker Agent — Executes the task in phases (Analysis → Planning → Implementation → Review → Finalization), generating detailed thought traces at each step
- 🟣 Code Review Agent — Challenges the Worker's reasoning, asks probing questions, and suggests improvements in real-time
- 🟢 Audit Agent (AEGIS) — Verifies reasoning quality, detects hallucinations and lazy reasoning, and issues pass/fail verdicts with confidence scores
Key differentiators:
Bidirectional A2A Communication — Agents don't just send outputs downstream. The Code Review Agent asks the Worker questions. The Worker answers and revises. The Audit Agent verifies the entire exchange. This is real negotiation, not a pipeline.
Self-Correction Loop — When AEGIS rejects a phase, the Worker automatically retries with improved reasoning. You can see the "before" and "after" side-by-side with green-highlighted changes.
Hierarchical Thinking Levels — Agents reason at three levels: Strategic (high-level goals), Tactical (phase-level planning), and Operational (immediate decisions). This mirrors how expert humans think about complex problems.
Compressed Context Management — For long-running tasks, our Context Manager maintains task memory, decision trees, and self-correction history — ensuring agents maintain coherence across hours of autonomous work.
Figma-like Visualization — A horizontal board view with zoom/pan lets you see the entire multi-agent conversation: every thought trace, every question, every revision, every audit verdict — all connected with visual relationship lines.
How we built it
We built AEGIS Commander as a React + TypeScript application powered by Gemini 3 Pro Preview for all three agents.
Architecture:
- Frontend: React 18 + TypeScript + Vite + TailwindCSS
- AI Engine: Gemini 3 Pro Preview (
gemini-3-pro-preview) via Google GenAI SDK - Visualization: Custom board view with
react-zoom-pan-pinchfor Figma-like navigation - Blockchain: Hedera Hashgraph for immutable audit ledger entries
- Context Management: Custom hierarchical context service with compressed summaries and decision tree tracking
The multi-agent orchestration flow:
- Human enters a task → Worker Agent breaks it into 5 phases
- Worker generates a thought trace for the current phase
- Code Review Agent analyzes the output, provides feedback, and asks questions
- Worker explicitly answers questions and revises its output based on suggestions
- Audit Agent (AEGIS) examines the full exchange — thought traces, feedback incorporation, revision quality
- If AEGIS rejects: Worker self-corrects and retries. If verified: proceed to next phase
- Repeat across all 5 phases until task completion
Each agent uses structured JSON output schemas with Gemini 3's native structured generation, ensuring consistent, parseable responses. We also leverage Gemini 3's thinking budget feature to control reasoning depth per thinking level.
Challenges we ran into
Context Contamination — Early versions had agents drifting off-topic. The Code Review Agent would ask questions about SpaceX when the task was about cryptocurrency. We solved this by filtering conversation history per-phase and strengthening prompt boundaries with explicit task-context enforcement.
Infinite Re-render Loops — Storing zoom/pan transform functions in React state caused the UI to freeze completely. We refactored to
useRefto break the cycle — a subtle but critical fix.Message Relationship Tracking — Building a visual conversation tree required each message to know its parent. Our initial approach generated IDs after insertion, breaking the chain. We restructured
addMessageto return IDs synchronously, enabling correctrespondsTolinking.Agent Quality Control — Getting agents to genuinely incorporate feedback (not just acknowledge it) required careful prompt engineering. We implemented an explicit revision loop where the Worker must demonstrate what changed and why.
Canvas Clipping — The Figma-like board view clipped content when panning. Multiple nested
overflow-hiddencontainers were the culprit — we traced through the component tree and selectively appliedoverflow-visibleto enable infinite canvas behavior.
Accomplishments that we're proud of
Real A2A collaboration — Our agents don't just pass data; they debate, question, and improve each other's work. The Code Review Agent catches methodology gaps, and the Worker visibly incorporates the feedback.
100% audit pass rate on well-formed tasks — When given clear tasks, our multi-agent system produces publication-quality output that passes AEGIS verification with perfect scores across all 5 phases.
Visible self-correction — Users can see exactly where an agent went wrong, what feedback it received, and how it improved — with side-by-side comparison and green-highlighted changes.
Hierarchical thinking — The Strategic → Tactical → Operational thinking levels produce noticeably more structured and coherent outputs than flat prompting.
End-to-end autonomous execution — From a single human prompt to a complete, reviewed, audited research paper — fully autonomous with zero human intervention during execution.
What we learned
Prompt engineering is architecture — The difference between agents that collaborate and agents that ignore each other comes down to how you structure context, boundaries, and expectations in prompts.
A2A is harder than it looks — True bidirectional agent communication requires careful state management, message threading, and context isolation to prevent cross-contamination.
Thinking levels matter — Forcing agents to reason at different abstraction levels (Strategic vs. Operational) produces dramatically better output than asking them to "think carefully."
Visualization is the killer feature — Being able to see the entire agent conversation — thought traces, questions, revisions, audit verdicts — makes the system trustworthy and debuggable in a way that terminal logs never could.
What's next for AEGIS Commander
- Multimodal agent tasks — Agents analyzing images, codebases, and documents with AEGIS auditing multimodal reasoning
- Agent reputation system — Long-term tracking of agent reliability across tasks
- Real-time streaming — WebSocket-based live thought trace updates instead of batch rendering
- Context caching — Leveraging Gemini 3's native context caching for cost-efficient long-running tasks
- Agent marketplace — A decentralized marketplace where agents can be hired, rated, and paid via Hedera smart contracts
Built With
- gemini-3
- google-genai-sdk
- node.js
- react
- tailwindcss
- typescript
- vite

Log in or sign up for Devpost to join the conversation.