Anthropic's latest model was so dangerous at cyberattacks that cybersecurity stocks dropped 7% when it leaked. That's not a headline from a sci-fi thriller. It happened in early 2026. In Anthropic's own framing, frontier cyber capability is becoming a race where offensive automation can outpace traditional defensive response. We kept coming back to a simple question: if AI can now run offensive attacks autonomously, why is defense still largely rule-based and human-driven? Cybersecurity has always had red teams and blue teams, attackers and defenders. We wanted to know what happens when you make the blue team an AI that never sleeps, never misses a signal, and gets smarter every run. That's where Aegis came from.
Neither of us came into this weekend with ML or cybersecurity experience, which made this a genuine stretch. On the ML side, we learned how to frame cyber defense as a reinforcement learning problem, defining the state space, action space, and reward function in a way that produces meaningful defensive behavior rather than reward hacking. The hardest part was cost-aware reward shaping: the agent had to learn that isolating a host is expensive, so it should only do it when confidence is high enough to justify the operational cost. We also learned that PPO is surprisingly robust even in sparse-reward environments, as long as your environment contract is airtight.
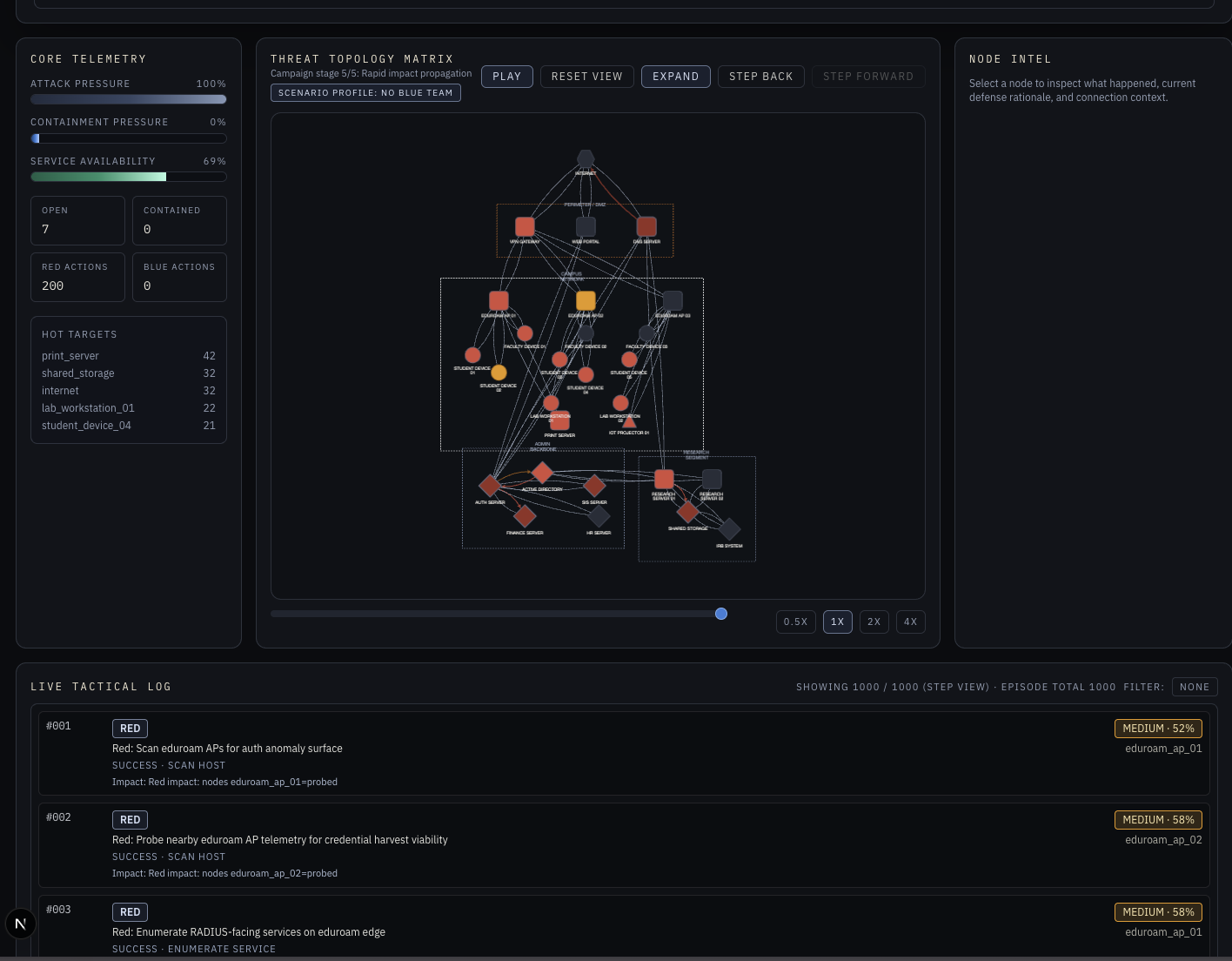
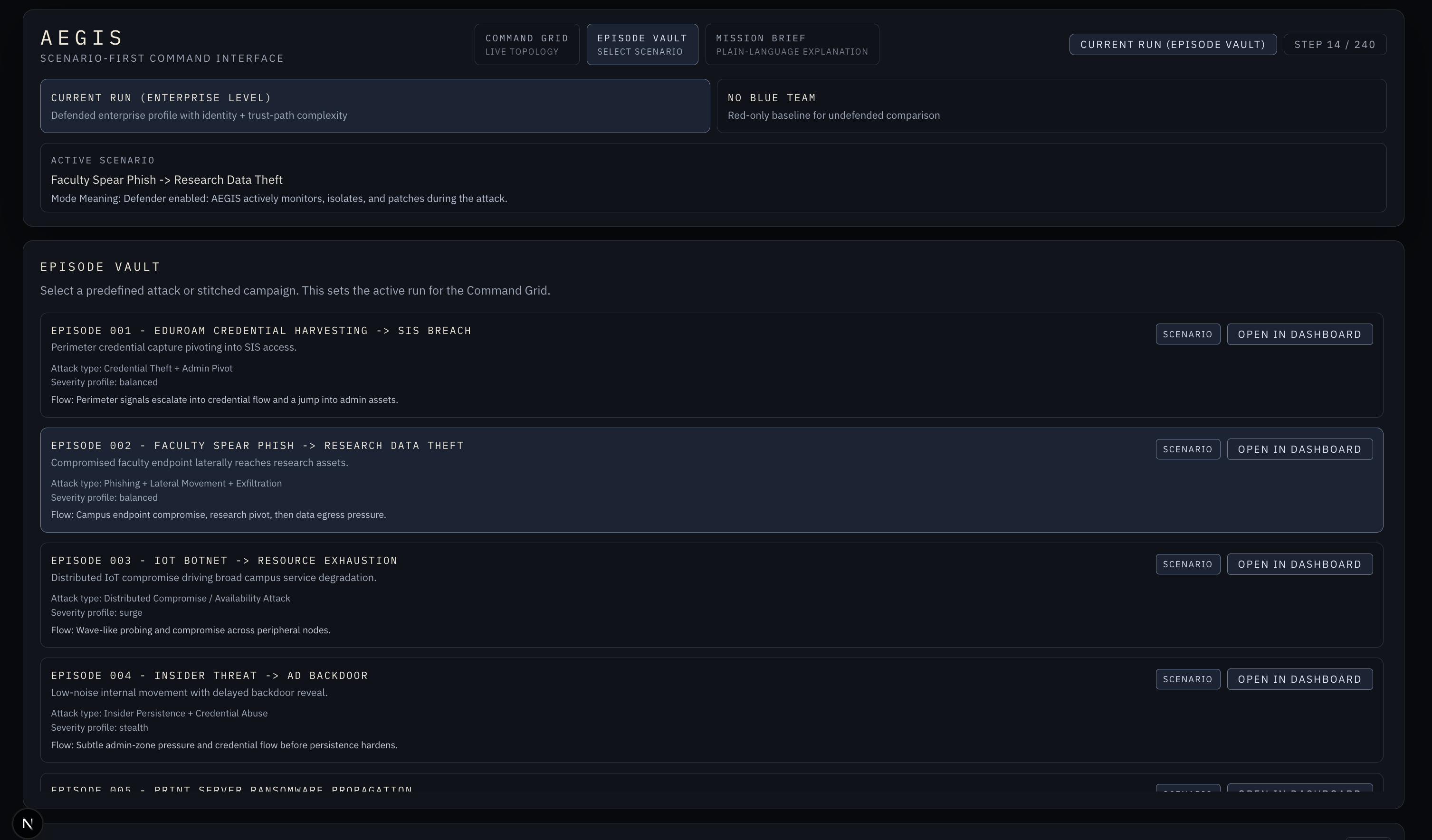
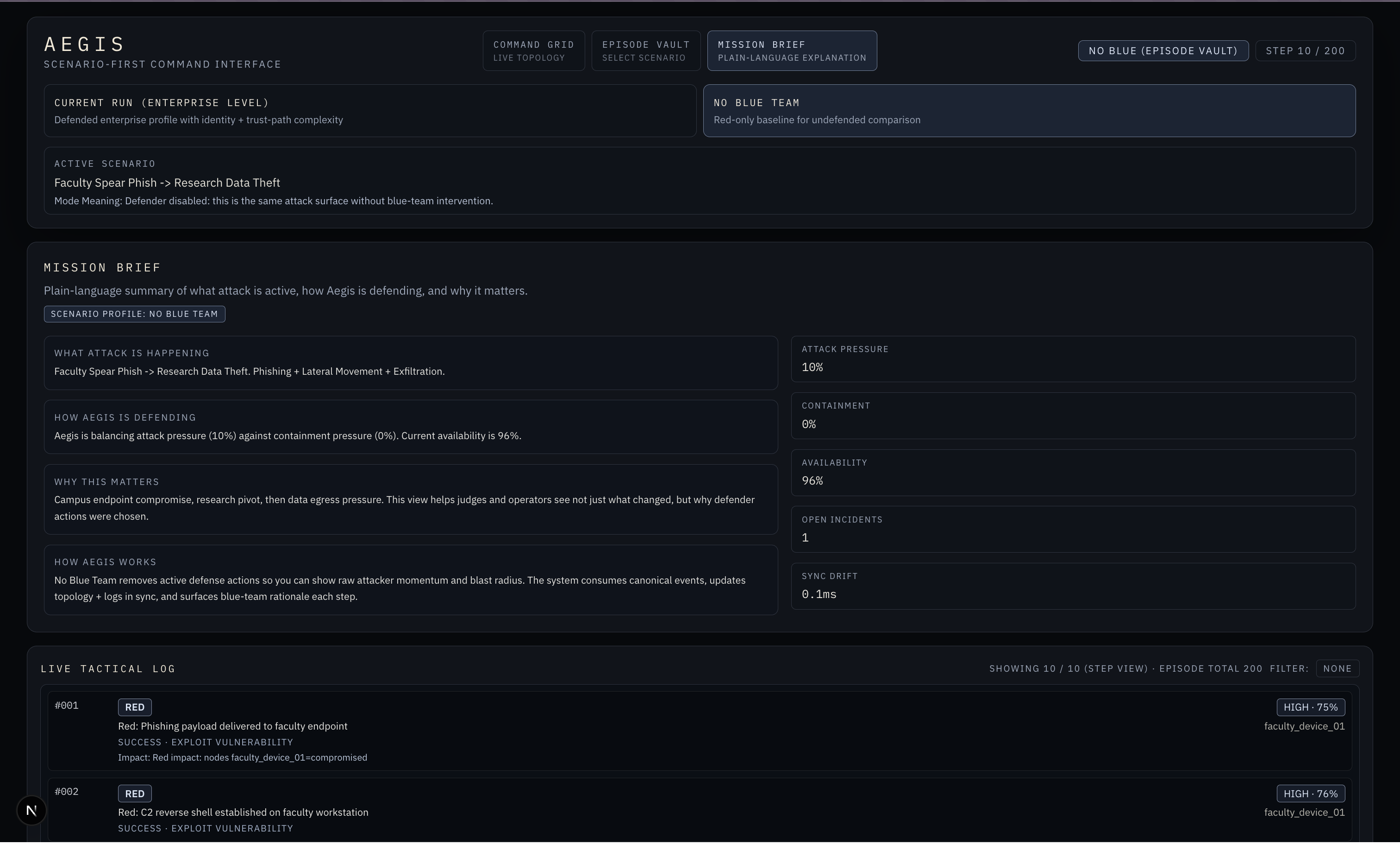
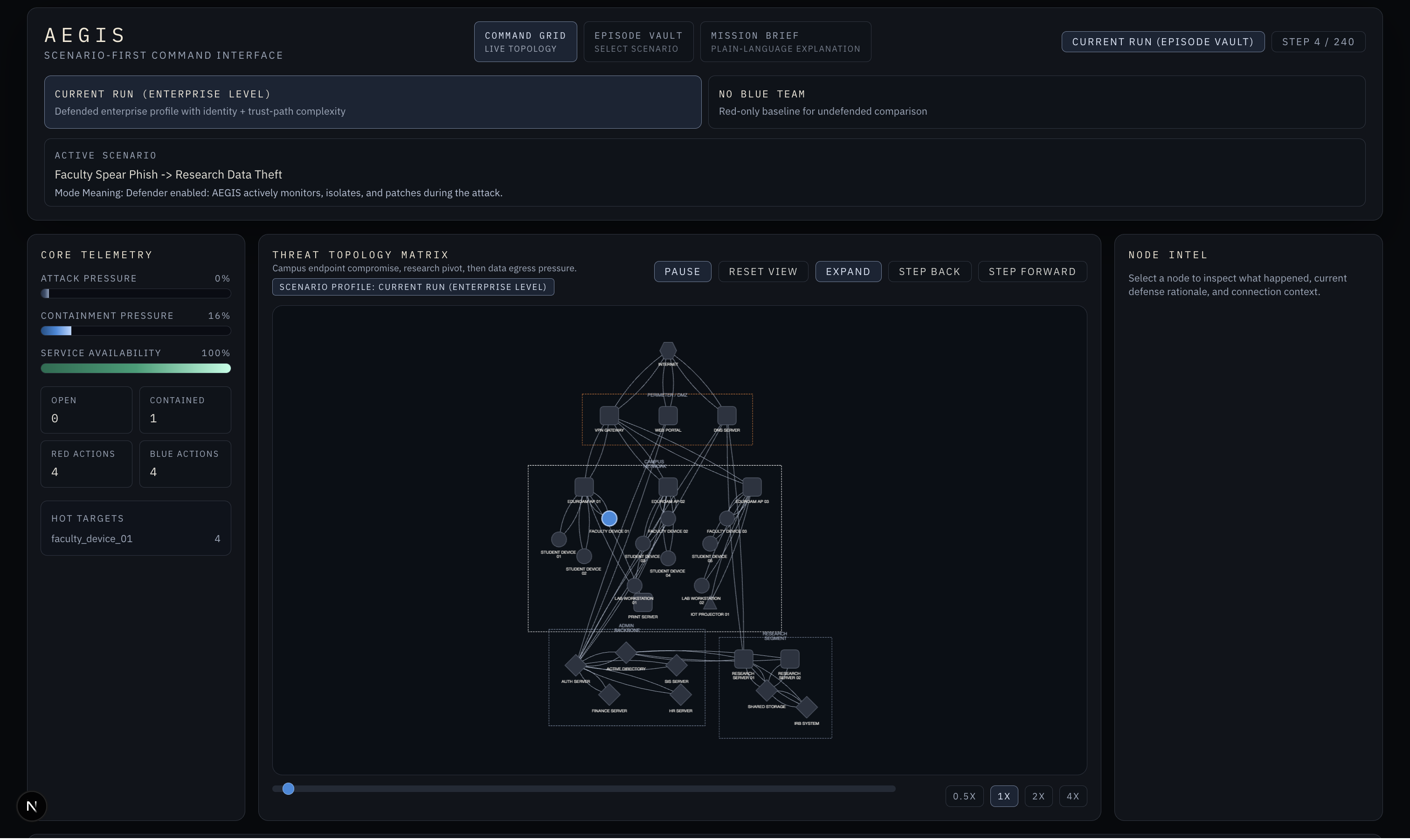
Aegis has three layers. The environment is a 28-node network simulation modeled after a university campus, with four zones, asymmetric trust relationships, and five attack scenario families ranging from credential harvesting to ransomware propagation. The model is two PPO training pipelines built with RLlib and PyTorch, with our deployed model adding preflight-gated training, cost-aware reward framing, and LSTM temporal context so the agent can recognize patterns that only become suspicious across time. Against a no-defense baseline it achieved 86% damage reduction, 44% better than a rule-based defender, with a 48% detection latency improvement, trained on 3 NVIDIA A100 GPUs. The frontend is a Next.js command interface that renders every training run as a replayable episode, driving four live panels: Core Telemetry, Threat Topology Matrix, Node Intel, and the Live Tactical Log, all scrubbable step by step.
The two biggest challenges were reward shaping and the replay pipeline. Early runs produced an agent that over-isolated. It learned that cutting nodes off the network reduced attack pressure, so it isolated everything indiscriminately and tanked service availability. Getting the balance right required several iterations of cost-aware reward framing. Getting training artifacts, environment state, and frontend rendering all on the same schema contract, so every step in the log matches exactly what the topology shows, took longer than expected and was the hardest pure engineering problem of the weekend.
Built With
- next.js
- nvidia-a100-gpus
- python
- pytorch
- rllib
- tailwind-css
- typescript









Log in or sign up for Devpost to join the conversation.