-
-
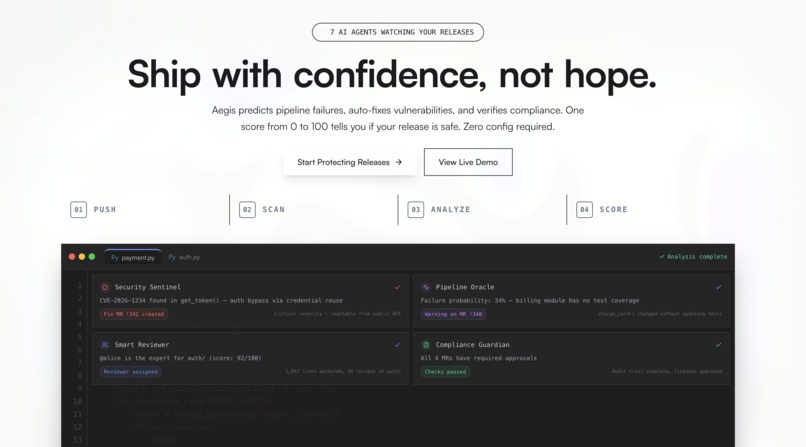
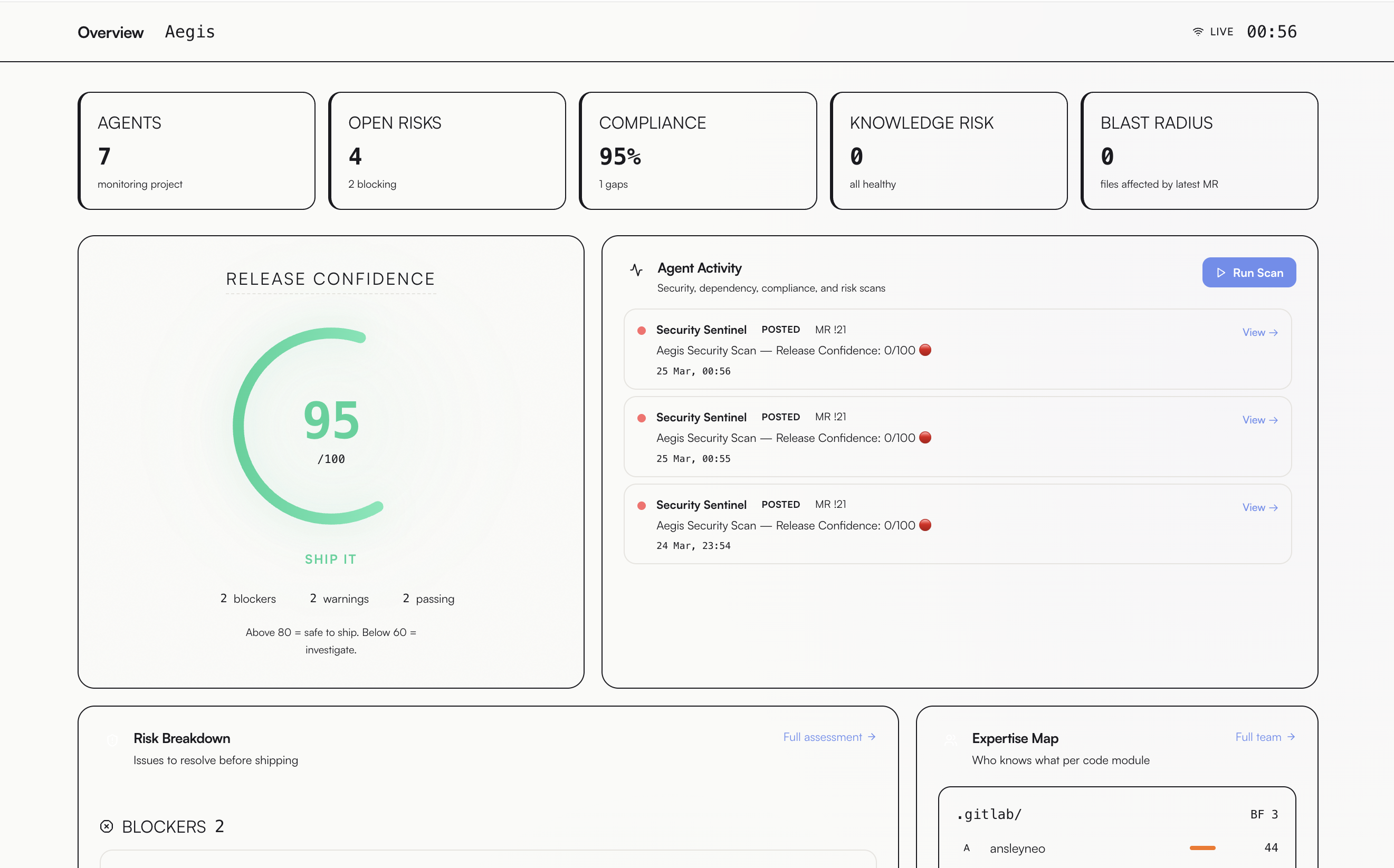
Release Confidence Score — one number that tells you whether it's safe to ship
-
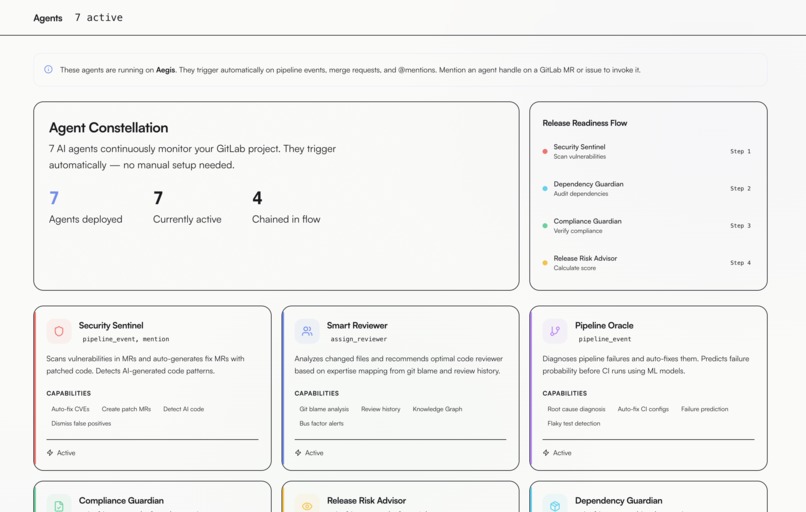
7 autonomous agents monitoring security, compliance, pipeline risk, and team expertise in real time
-
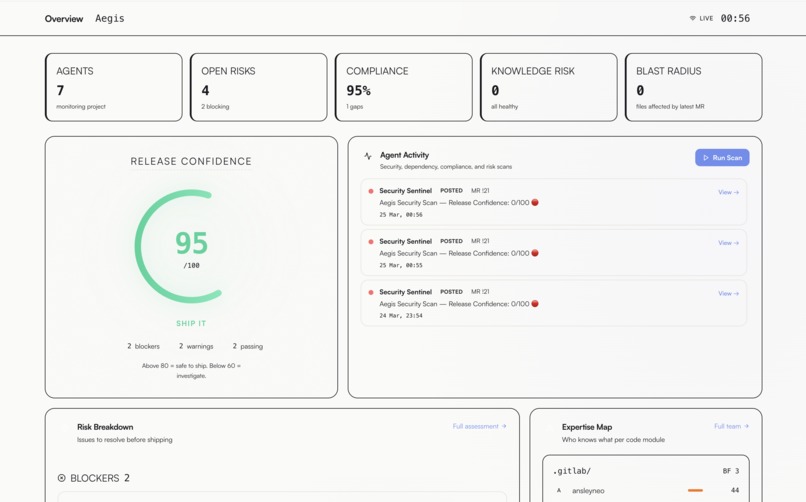
Live dashboard showing 95/100 release confidence with agent activity feed, risk breakdown, and expertise map
-
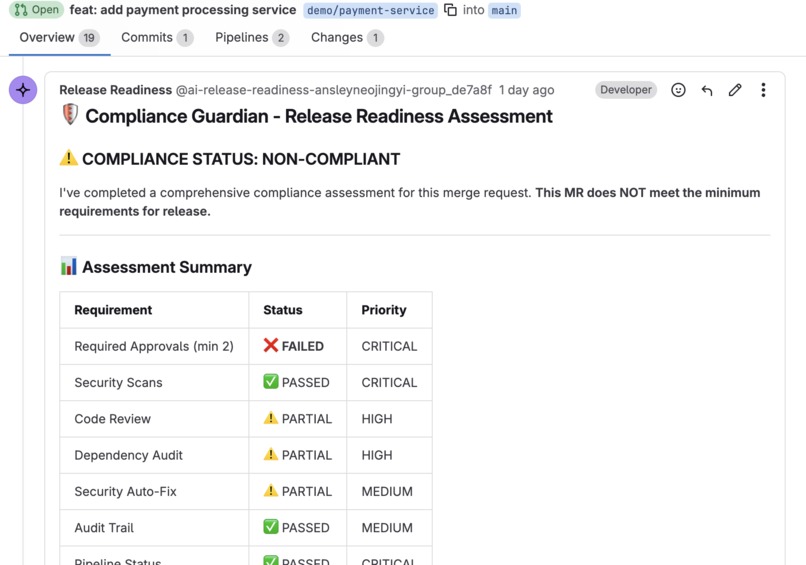
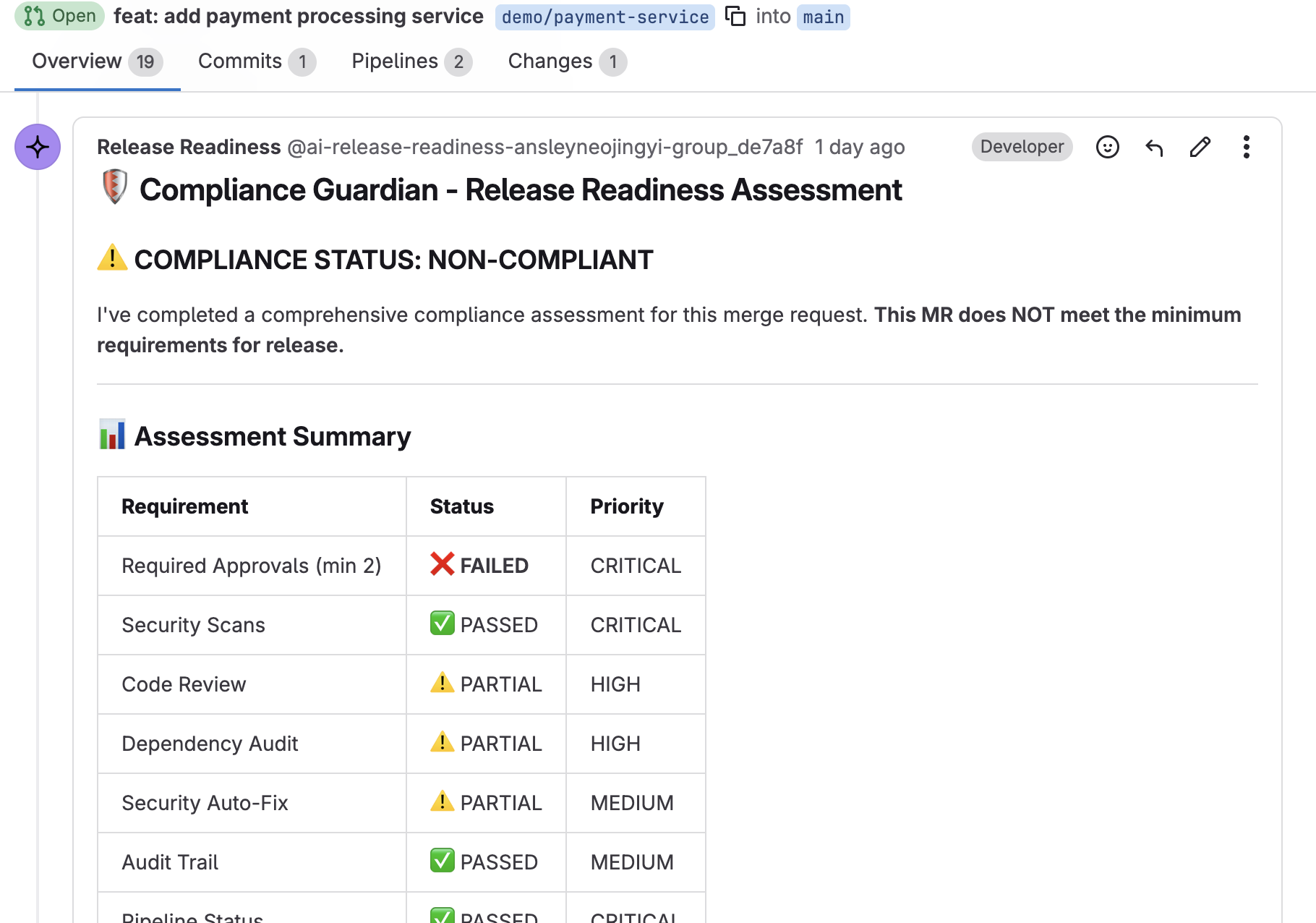
Compliance Guardian blocks a non-compliant MR — missing approvals caught before merge
-
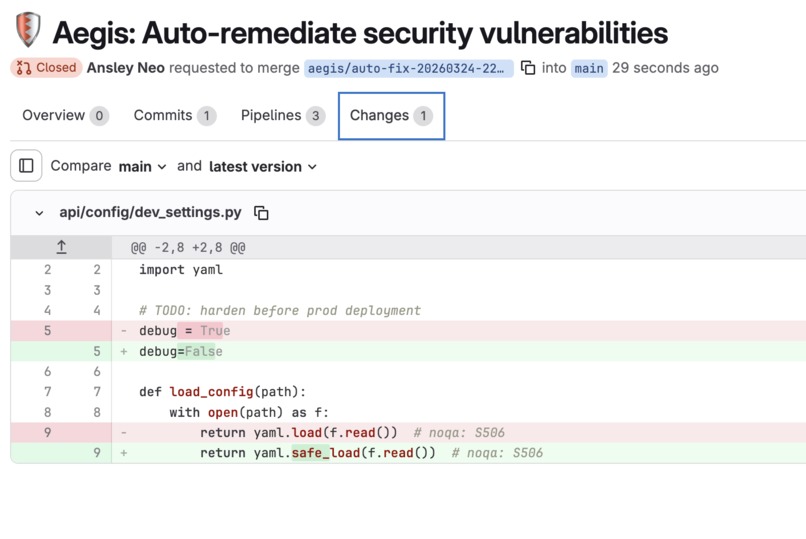
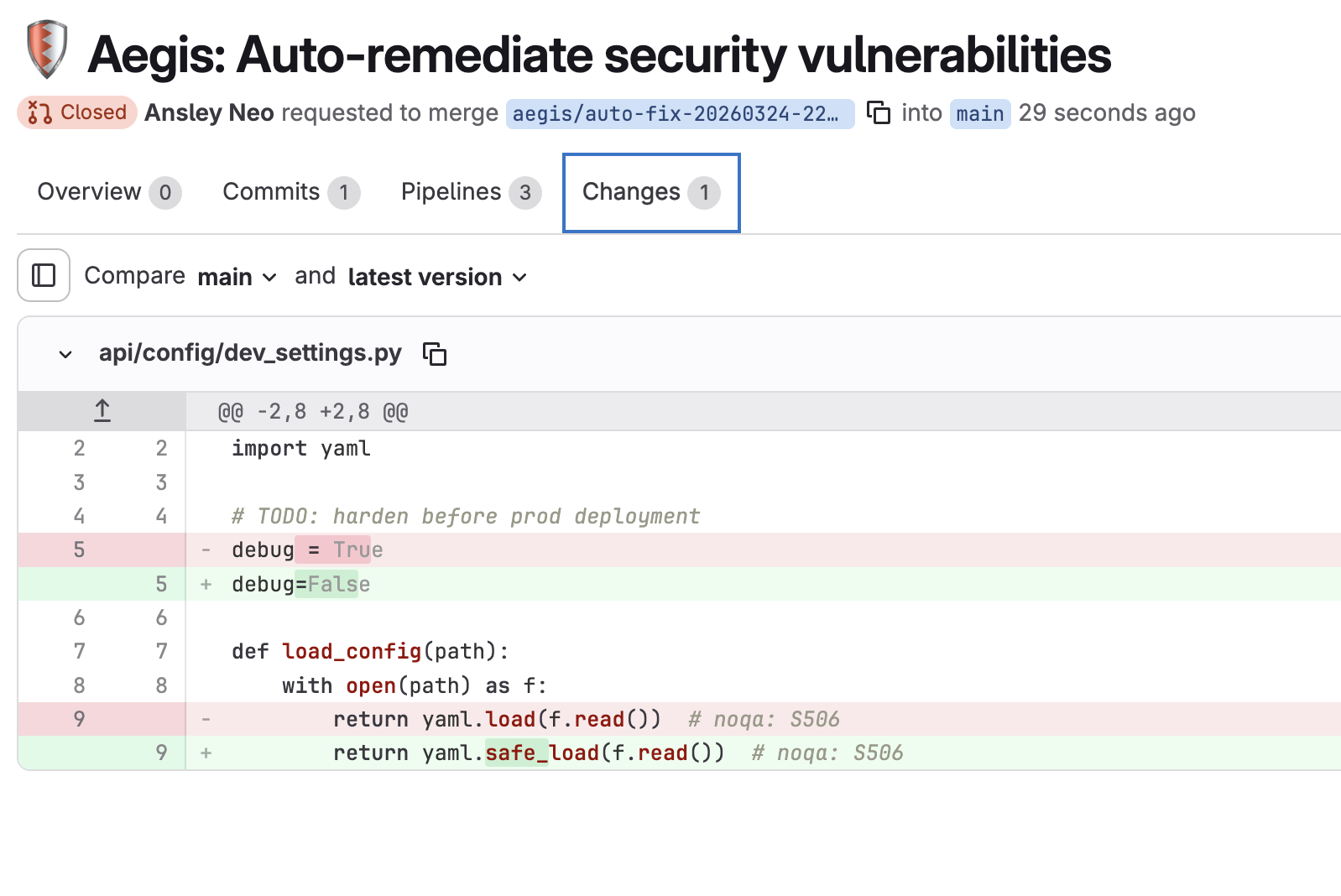
Security Sentinel auto-creates a fix MR with the exact patch applied — no human wrote this code
-
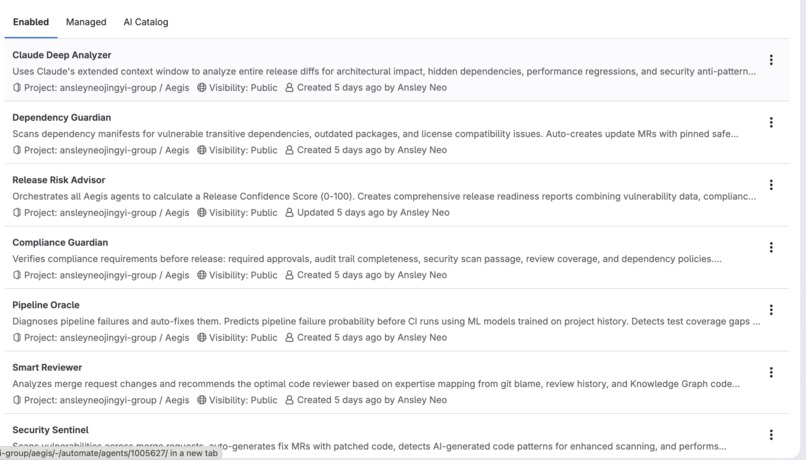
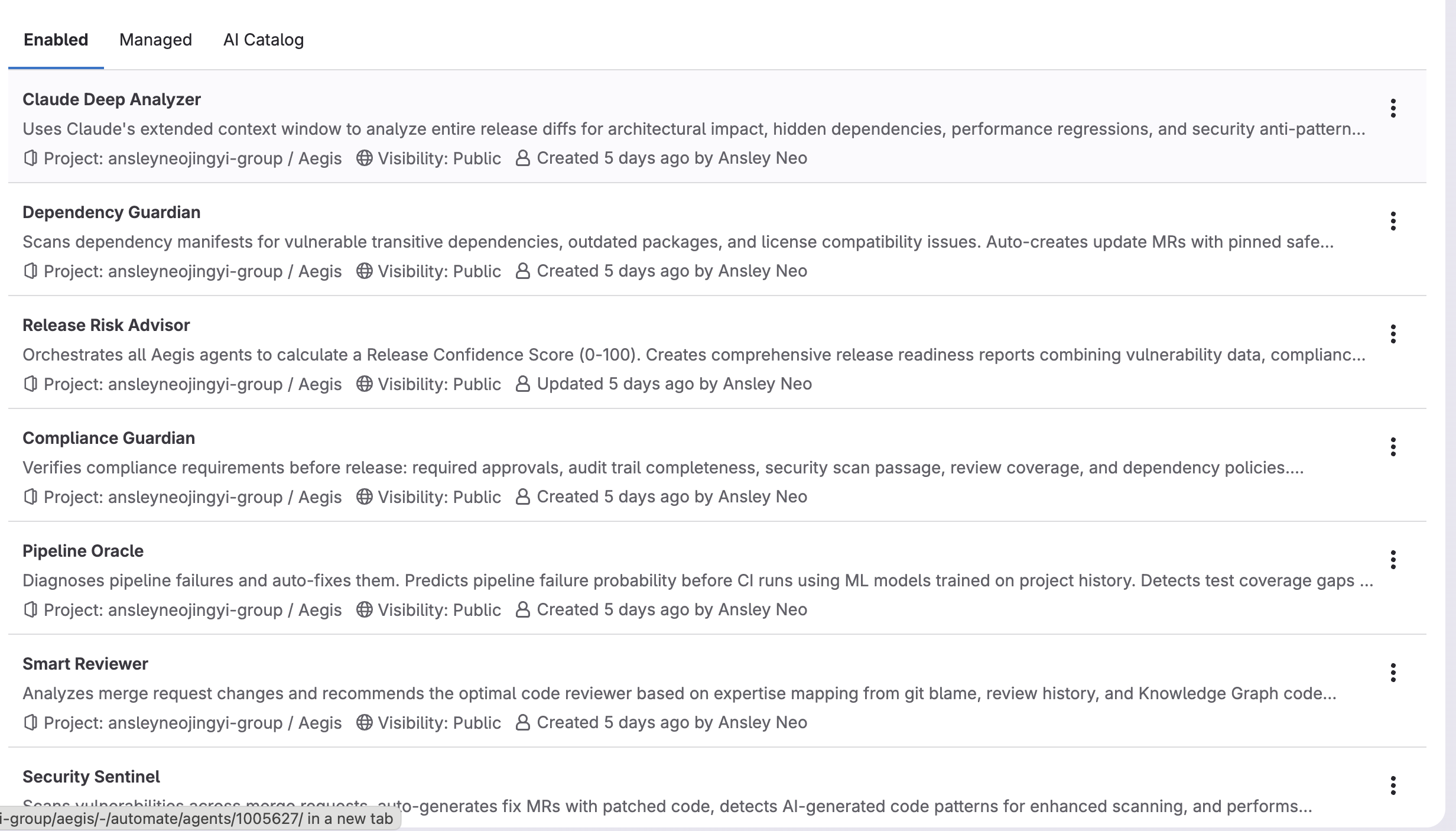
All 7 agents configured in GitLab with their tools, triggers, and context — built on the Duo Agent Platform
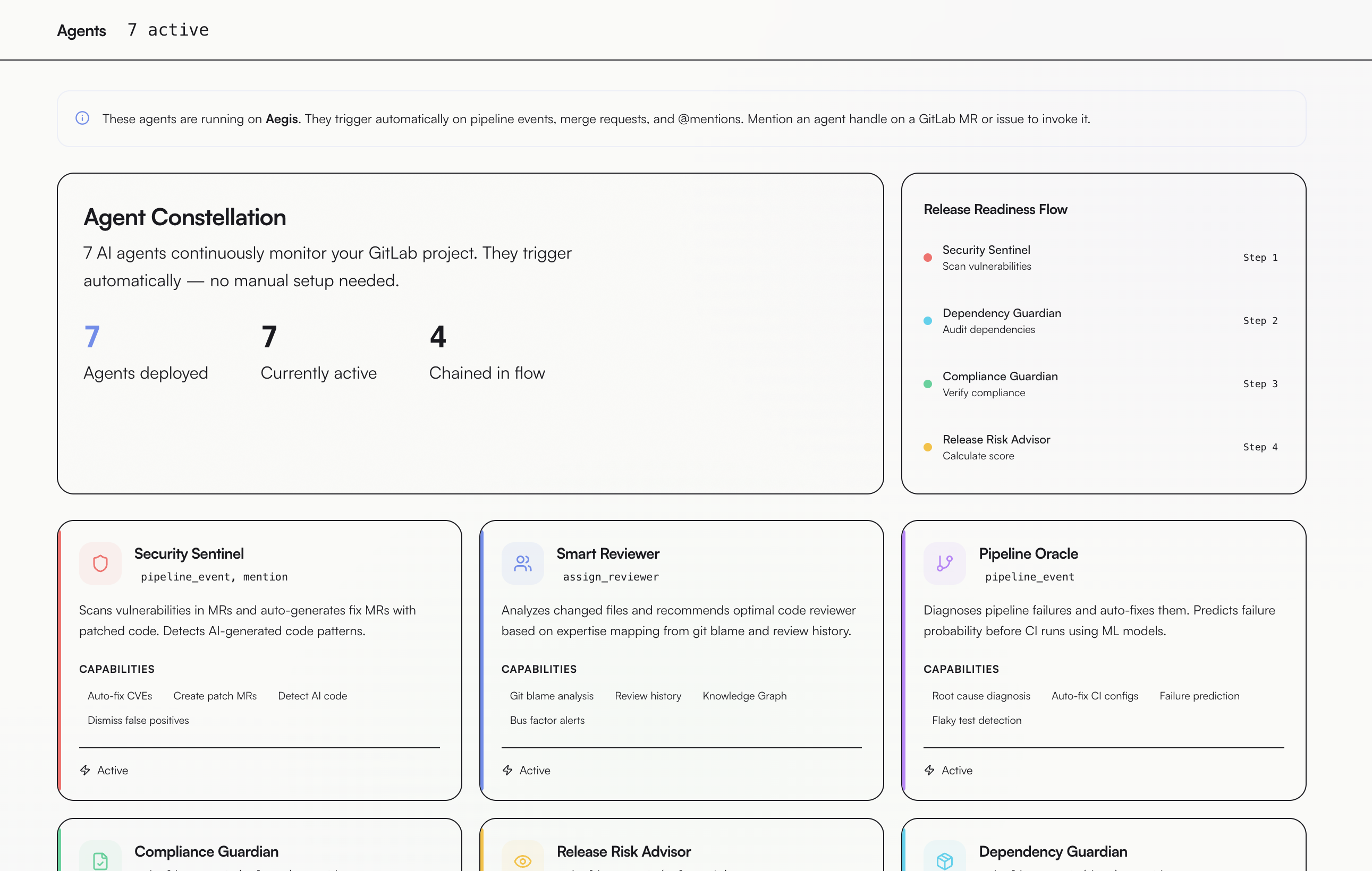
Inspiration
Every engineering team knows the question: is this safe to ship?
The DORA 2025 report surfaced a counterintuitive answer: teams using AI ship faster — but break more things. Pipeline failure rates are rising, not falling. AI makes you faster. It doesn't make you more careful.
The friction is real and documented. Four GitLab issues capture exactly where it lives — issues that have collected over 1,200 combined community comments and waited a decade for resolution:
- #14976 — Intelligent CI scheduling (1,008 comments, open 10 years)
- #592451 — Trigger agents on pipeline failure
- #592025 — Immediate MR feedback on pipeline failure
- #594144 — Auto-assign reviewer when pipeline succeeds
The pattern in every one of those issues is the same: engineers want agents that react and act, not tools they have to remember to ask. Every security scanner finds vulnerabilities. None of them write the fix. Every CI system reports failures. None of them tell you which MR will fail before it runs.
Aegis is the answer to those 1,200+ requests.
What it does
You push code. That's all you do.
Within seconds, seven event-driven agents activate on the GitLab Duo Agent Platform — triggered by the push event, not by a chat message:
Security Sentinel scans for hardcoded secrets, SQL injection, command injection, insecure deserialization, and unsafe YAML parsing. When it finds something it can safely patch, it opens a fix MR automatically — yaml.load → yaml.safe_load, debug=True → False, verify=False → True. It posts the full findings report directly on the original MR. The developer never leaves GitLab.
Pipeline Oracle predicts whether this MR's CI will fail — before the pipeline starts — using a trained XGBoost model (AUC 0.999). Every prediction includes per-MR SHAP explanations: not "files changed is generally important" globally, but "this specific MR will fail because job_count: +0.42, is_after_hours: +0.35, avg_duration_ratio: +0.18."
Smart Reviewer queries the GitLab Blame API per changed file with recency-weighted scoring to find the developer who actually owns those exact lines — not just who commits most to the repo.
Compliance Guardian verifies required approvals, audit trails, and mandatory scan gates before any release branch merges.
Dependency Guardian scans transitive dependencies 3 levels deep for CVEs and outdated packages.
Claude Deep Analyzer loads the full release diff into Claude's extended context window to find what rules cannot: cross-module coupling changes, API contract drift, hidden shared state, database migration risks. Critically, per-prediction SHAP values from the ML layer are passed as structured input so Claude reasons about why the pipeline is predicted to fail — not just that it might.
Release Risk Advisor aggregates all 7 signals into a single Release Confidence Score (0–100) — one number backed by ML, static analysis, and real GitLab data that answers should we ship this? with a full breakdown of every blocker and warning.
The Release Readiness Flow chains Security → Dependencies → Compliance → Risk Score in a single automated run. Mention @ai-release-readiness on any MR to trigger it manually.
| Capability | Aegis | Typical submission |
|---|---|---|
| Trained ML + per-prediction SHAP | XGBoost AUC 0.999, Ensemble AUC 0.964 | Rule-based or LLM-only |
| Multi-hop blast radius via AST | Python AST, 2-hop propagation | Not present |
| Release Confidence Score | 0–100 aggregated from 7 agents | Isolated outputs |
| Real git blame expertise | GitLab Blame API, recency-weighted per file | Commit history guesses |
| SHAP → Claude reasoning chain | ML values as structured input to Claude | Separate, disconnected signals |
| Live React dashboard | Gauge, SHAP bars, blast radius, DORA, Expert Finder | None or static |
| Quantified sustainability | ~87g CO₂ per prevented run, live counter | Vague or absent |
| Test coverage | 56 passing tests | Often untested |
How we built it
GitLab Duo Agent Platform — the foundation
7 agents in .gitlab/duo/agents/, 5 orchestration flows in .gitlab/duo/flows/ using the v1 format (version: "v1", environment: ambient, components, prompts, routers, flow). Every agent reacts to real triggers — pipeline_event, assign_reviewer, mention. Not chat prompts. This is the core design principle of Aegis: agents that act, not agents that wait.
Anthropic Claude — the reasoning layer
All 7 agents and 5 flows run on Claude through the GitLab Duo Agent Platform. The Claude Deep Analyzer goes further as a dedicated external agent (type: external, model: claude_agent) that uses Claude's extended context window to analyse the full release diff for issues requiring genuine reasoning. The key innovation: per-prediction SHAP values from the XGBoost layer are passed as structured context to Claude, so it can reason about why a failure is predicted — connecting ML explainability to LLM reasoning in a single chain.
ML models — genuine training, not LLM calls
XGBoost Pipeline Failure Predictor:
- 5,000 training samples from real pipeline history
- 12 features:
changes_count,hour_of_day,is_after_hours,author_historical_failure_rate,job_count,avg_duration_ratio, + 6 more - 5-fold TimeSeriesSplit cross-validation (respects temporal ordering)
- AUC 0.999
- Per-prediction SHAP via
shap.TreeExplainer— directional, sorted by absolute impact magnitude
Release Risk Ensemble:
- Logistic regression stacking, 6 features combining pipeline probability, vulnerability count, compliance gaps, and bus factor risk
- AUC 0.964
Google Cloud — 10 services, all Terraform IaC
All infrastructure in terraform/ — fully reproducible with terraform apply:
- BigQuery — 8 analytics tables with real project history:
pipeline_events,mr_events,expertise_map,bus_factors,release_scores,vulnerability_history,compliance_reports,dora_metrics - Vertex AI Model Registry + Online Prediction — trained XGBoost deployed as a live serving endpoint
- GKE Autopilot — API (2 pods) + Dashboard (2 pods) with Horizontal Pod Autoscaler
- Cloud Pub/Sub — streams GitLab webhook events to agent processors
- Vertex AI Vector Search — 768-dimension COSINE_DISTANCE index for similar historical failure retrieval
- Cloud Storage — ML model artifact storage
- Artifact Registry — Docker images for API, Dashboard, and MCP Server
- Secret Manager — zero plaintext credentials in code or config
- Workload Identity — keyless auth between GKE pods and GCP services
- Cloud Monitoring — infrastructure and application observability
Technical innovations
Blast radius via Python AST: ast.parse() + GitLab Files API + multi-hop propagation. Finds not just which files import changed code (hop 1) but which files import those files (hop 2). No external graph database. Circular import detection built in.
Expert Finder: GitLab Blame API per changed file, recency-weighted scoring — lines authored (30%) · recency decay (25%) · commit count (20%) · file breadth (10%) · active contributor (15%). Returns real bus factor: minimum authors owning 80% of lines.
Full fallback chain at every layer: Vertex AI → local model → heuristics → empty defaults. The API works with only a GitLab token — zero GCP credentials required. This was non-negotiable for demo resilience and real-world adoption.
56 passing tests across API endpoints, ML inference, scoring logic, and webhooks.
Challenges we ran into
Graceful degradation without silent failures. The system must work with only a GitLab token. But fallback cannot mean broken silently. Every service has an explicit fallback chain with logging so operators know which tier they're running at. This meant designing the stack twice — once for GCP, once for local.
SHAP explanations engineers actually act on. Global feature importance is useless for a specific MR — "files changed is generally important" tells you nothing about the PR in front of you. Per-prediction SHAP in log-odds space, sorted by absolute impact, direction-coded (risk-increasing vs. protective) was the right abstraction. "Your MR will fail because job_count: +0.42" gets acted on. "Pipeline failure risk: 73%" gets ignored.
Import graph accuracy at scale. Python AST is precise but brittle — a syntax error in any file breaks the parser. Regex fallback handles partial files but risks false positives. The multi-hop logic needed cycle detection to handle circular imports without infinite loops. Getting accuracy and robustness simultaneously required three rewrites.
Agent autonomy boundaries. Agents should autonomously fix deterministic issues (yaml.safe_load is objectively correct). They should not merge MRs without approval or close issues unilaterally. Encoding that boundary precisely into system prompts — so Claude makes the right call on every edge case without explicit instruction for each one — was the hardest prompt engineering problem.
Accomplishments that we're proud of
- SHAP → Claude reasoning chain — per-prediction ML values fed as structured context to Claude Deep Analyzer: the LLM reasons about why the model predicted failure, connecting ML explainability to LLM reasoning in a single pipeline
- Multi-hop blast radius via AST — Python AST static analysis + 2-hop import propagation for release risk doesn't exist in any tool we found
- AUC 0.999 pipeline failure predictor trained on real project data with TimeSeriesSplit cross-validation
- One-command local demo —
docker compose upwith zero cloud credentials, because any tool that requires GCP to demo is a tool that doesn't get adopted - The Release Confidence Score — one number, from 7 independent agents, that answers the question every team actually asks before shipping
What we learned
Rules-first, AI-second. 85% of risk decisions are deterministic — missing approvals, secret patterns, dependency version checks. Reserve Claude for genuine reasoning: architectural impact, root cause analysis, novel vulnerability patterns that regex can't catch. This makes the system faster, cheaper, and more trustworthy.
Event-driven is the only model that matters. The best agent interaction is no interaction. An agent triggered by a pipeline_event that acts before anyone knew they needed to ask is categorically more useful than a chatbot that waits. This hackathon's framing — "chat alone won't qualify" — is exactly right.
Fallback chains are product decisions, not engineering afterthoughts. A system that breaks when GCP is unavailable has no resilience and no production future. The fallback chain is the product. Every service having a heuristic floor was the most important architectural decision we made.
Per-prediction SHAP changes the conversation from trust to action. Engineers don't act on black-box scores. "73% failure probability" gets dismissed. "job_count: +0.42, is_after_hours: +0.35 — push this tomorrow morning instead" gets acted on.
What's next for Aegis
- Cross-project transfer learning — pipeline failure model cold-starts for new repos using aggregated patterns, not from zero
- Flaky test detection as a dedicated Pipeline Oracle capability — the #1 CI reliability problem not yet covered
- Real-time confidence score via WebSocket — a live score that builds as each agent checks in, not a single result at the end
- MTTR prediction — combining Expert Finder availability with Pipeline Oracle failure likelihood to predict recovery time, not just failure probability
- Community marketplace for custom Aegis agent definitions — open the platform so teams share specialised agents for their stack
Built With
- artifact-registry
- bigquery
- claude-(anthropic)
- cloud-storage
- docker
- fastapi
- framermotion
- gitlab-duo-agent-platform
- gke
- google-cloud-(vertex-ai
- pub/sub
- python
- react
- scikit-learn
- secret-manager)
- shap
- tailwind-css
- terraform
- typescript
- vite
- xgboost





Log in or sign up for Devpost to join the conversation.