-
-
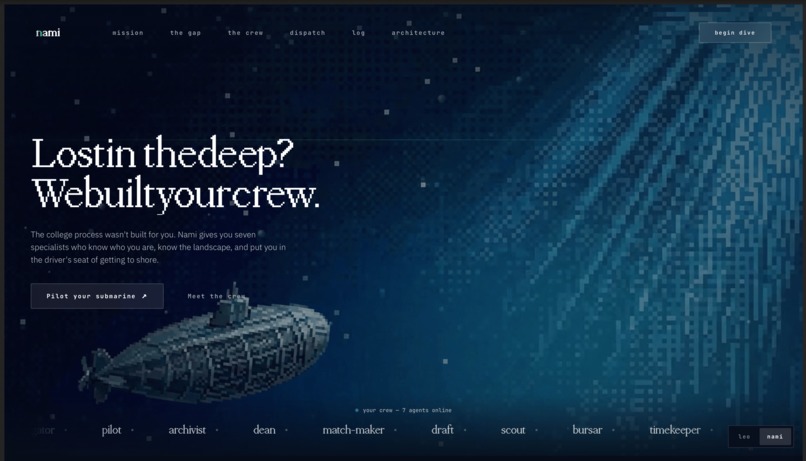
landing page
-
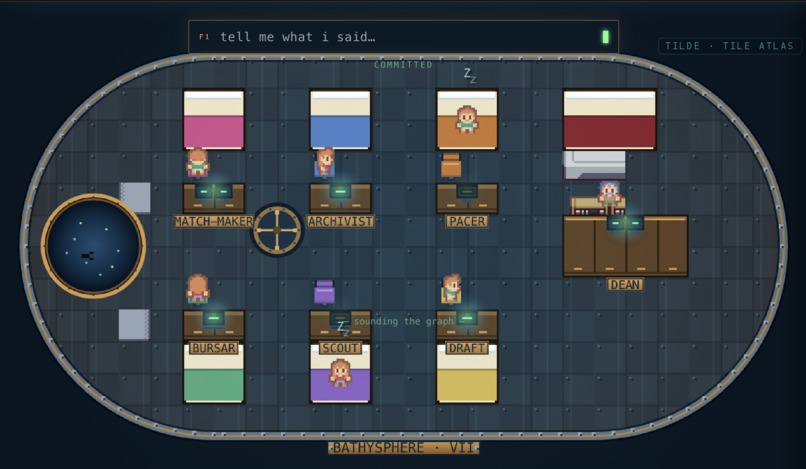
pixel agents
-
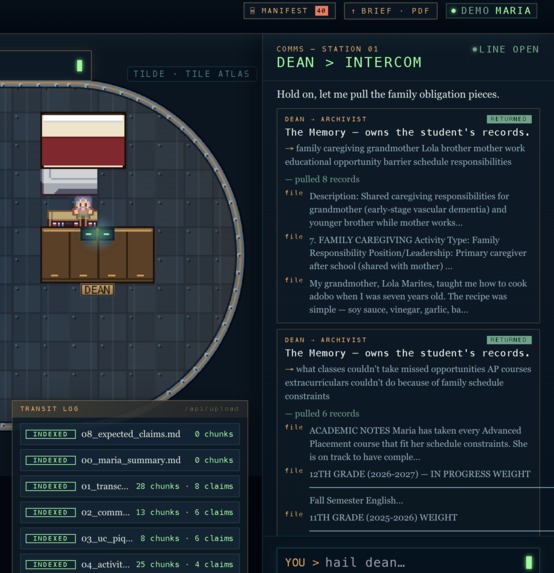
context library being called

Nami
Inspiration
Private college counseling costs tens of thousands of dollars. First-gen students usually get the opposite: a generic chatbot that sounds confident and still invents aid numbers, deadlines, and "facts" about schools. That's worse than nothing, because it costs trust.
We wanted to flip the shape of the help. Not one chatbot pretending to know everything, but a crew of specialists behaving like a real office — warm, specific, and forced to show their work. An admissions counselor who can point at the line of the transcript they're reading. A financial-aid specialist who can link to the exact aid page a number came from. A Dean at the front of the room who keeps them coordinated on your story.
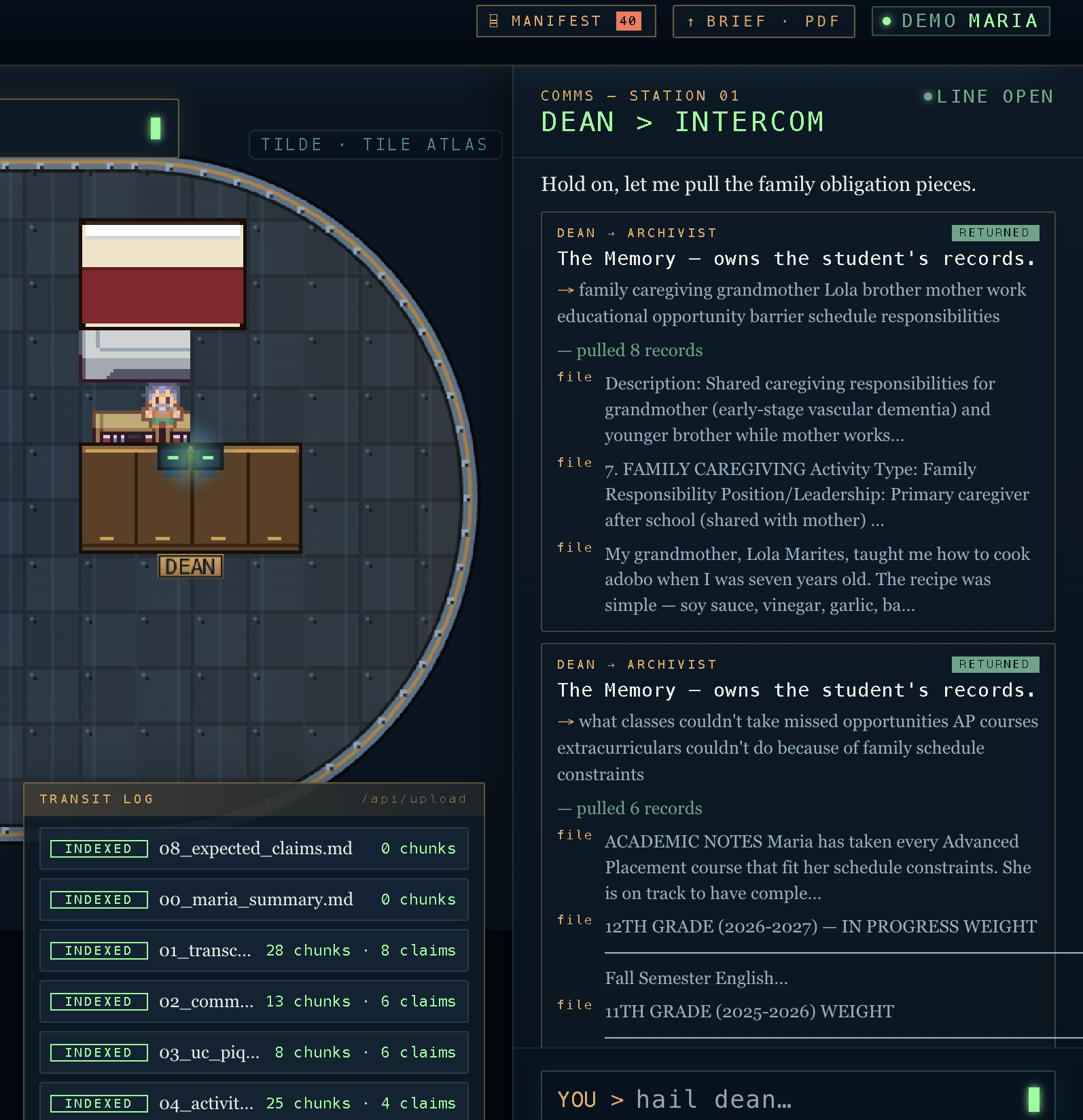
Nami is that office. One orchestrator (Dean) and six specialists (the Tsunami) share a single grounded memory. When an agent remembers something about you or the world, it traces back to a chunk you can inspect — not a vague "trust me."
What it does
Nami is a pixel-art bathysphere where a student talks to Dean, who coordinates six specialists across the full college-search surface:
| Agent | Station |
|---|---|
| Dean | Head counselor — orchestrates the crew, asks follow-ups, opens callbacks |
| Archivist | Reads uploads, proposes structured claims about the student |
| Match-Maker | Finds schools that actually fit — academics, fit, money |
| Bursar | Computes real net price after aid; won't fabricate numbers |
| Scout | Hunts scholarships from curated world-scope sources |
| Draft | Reads essays; gives receipts-based feedback, not vibes |
| Pacer | Builds the deadline calendar and nudges when something slips |
The through-line is Human Delta. Student uploads (transcripts, essays, voice-memo text, financial notes) and a curated world library (aid pages, college facts, scholarships) live in one knowledge graph. Specialists query that graph with domain-scoped search, so every answer is tied to a real source. Students drop a file, Archivist proposes claims, the student confirms them, and the profile starts powering every conversation — with citations hoverable inline in the chat transcript.
The UX story we're driving toward: receipts everywhere. Click any [chunk:…] in Dean's reply and you see the exact line of the exact document he's reading.
How we built it
Stack
advisr/
├── frontend/ # Vite + React marketing landing (port 3000)
│ └── src/lib/routes.ts # cross-origin "Begin Dive" → /office
├── web/ # Next.js 15 product app (port 2847) ← the submarine
│ ├── app/office # pixel office + chat + constellation
│ ├── app/api/{chat,chunks,proposals,upload,profile/*}
│ ├── lib/agents/{dean,runtime,archivist/workers/*,callback}
│ ├── lib/graph/claims.ts # propose / confirm / reject
│ ├── lib/events/{bus,client}.ts # dual-path SSE + Supabase Realtime
│ ├── lib/humandelta/{client,search}.ts
│ └── components/office/{Canvas,PixelWorld,KnowledgeConstellation,DropZone,ProposalDrawer}
├── supabase/migrations/ # schema + RLS + storage bucket + demo seed
└── about/ # Maria Delgado Santos fixture files
- Next.js 15 App Router with server-only agent runtime, streaming AI-SDK responses, and client components for the pixel office, chat, and constellation.
- Supabase for Postgres + storage + realtime. Drizzle ORM owns the schema; RLS is tight so student data is scoped to auth, with a deliberate service-role bypass for demo mode.
- Anthropic Claude Sonnet 4.5 for Dean and specialists, Haiku for lightweight routing.
- Human Delta as the shared memory substrate under
web/lib/humandelta/— client, search, document upload, crawl helpers, and per-specialist seed manifests. - Canvas 2D for the pixel office render loop,
react-force-graph-2dfor the knowledge constellation,@react-pdf/rendererserver-side for the student brief.
Grounding pipeline
upload → /api/upload
├─ Supabase Storage (source-files bucket)
├─ source_files row
├─ chunk text server-side
├─ chunks[] rows
├─ Archivist worker (kind-specific: transcript / essay / financial / activity)
├─ propose claim[] → claims table (status: pending)
└─ emit ingestion_started / ingestion_finished / claim_proposed events
chat → /api/chat (streamText + tools)
├─ Dean (Sonnet 4.5) calls archivistTool
│ └─ searchGraph(scopes: ['student']) → real Postgres chunks + UUIDs
├─ Dean cites [chunk:<uuid>] inline
└─ <Citation/> hovers resolve UUID → filename + offset preview
events → <dual-path>
├─ in-memory SSE (same process, instant)
└─ Supabase Realtime (cross-process, survives Vercel cold starts)
Every tool call, every claim, every ingestion event flows through the same bus. The UI reacts in real time: the constellation pulses when a file indexes, the ProposalDrawer slides in when Archivist proposes a new claim, and the DeanInterjectionLayer drops an intercom bubble when a callback agent has something unprompted to say.
Operator-grade tooling
Because the memory layer is the product, we invested in making it observable:
npm run hd:status— snapshot of every specialist's library (counts, last seed, health).npm run hd:seed:{match-maker,bursar,scout,all}— idempotent corpus rebuilds.npm run seed/npm run seed:dry/npm run seed:reset— Maria fixture hydration.npm run bootstrap— one-shot: schema probe → env check → seed. Clear remediation if schema is missing.npm run eval:archivist— recall-with-provenance eval against fixture ground truth.
Challenges we ran into
Grounding vs. latency. Retrieval has to be strict enough to stop fabrication and fast enough to feel like a conversation. We tightened HD search with domain scopes per specialist, added explicit empty-library behavior ("I don't have a seeded source for that — I won't guess"), and shipped a client-side prefix index via /api/chunks so optimistic search fires before the server round-trip.
API / SDK mismatch. Human Delta's search results were wrapped differently than the SDK expected — we spent a frustrating block of the hackathon debugging "always zero hits" before hitting the REST shape directly and unwrapping results by hand. Learnings landed in HUMAN_DELTA.md.
Indexing reality. Crawler concurrency limits, static-HTML bias, and noisy metadata on some source pages meant we had to batch seeds, probe queries iteratively, and prefer dense server-rendered sources over JS-heavy college sites that underperform headless.
The full ingest loop. A believable office needs upload → extract → human confirmation → profile injection. That's the loop that turns Nami from "chat with RAG" into a memory product, and it's the hardest one to get right. RLS vs. demo mode, Supabase Realtime vs. in-memory SSE, and keeping chat citations tied to actual Postgres UUIDs (not synthetic HD ids) were all sub-problems we had to solve to make the receipts real.
Two identities, one citation. Early on the Archivist searched Human Delta's library and returned HD chunk IDs that couldn't resolve back to the student's Postgres rows. Citations hovered into nothing. We refactored the Archivist tool to primarily search the student's own chunks (searchGraph with scopes: ['student']), returning actual DB UUIDs — and only fall back to HD for world-scope questions. Now every [chunk:…] hover shows the real filename and line range.
Accomplishments we're proud of
- A clear HD story. One API key, one graph, post-filtered by specialist — simple to reason about, simple to demo.
- Honest failure modes. When a library isn't seeded or search returns nothing, the system is explicitly steered to say so. No aid-number hallucinations.
- Receipts that actually resolve. Every
[chunk:<uuid>]Dean emits points at a real row inchunks, with filename + byte offsets for the hover. - A live office, not a static mock. Drop a file, the constellation lights up. Confirm a claim, the knowledge graph re-renders. The pixel crew isn't decoration — each sprite maps to a real agent that can be invoked.
- Operator-grade tooling. Seed scripts and probes make the knowledge layer inspectable without opening a DB GUI.
- A metaphor that lands. The office / bathysphere / crew framing makes a multi-agent system legible in seconds. Nobody has ever asked us "what's the Dean supposed to do?"
What we learned
The product is the memory layer. Chat is easy. Provable memory — what we know, why we know it, what the human approved — is the moat.
Curated beats chaotic crawl on hackathon timelines. A smaller, vetted corpus outperformed "index the whole web" for trust every single time.
Human Delta shines when it's structural. It's not just a search() call. It's a design where scopes, sources, and receipts are first-class in the UX — not surfaced through a debug panel.
Dual-path eventing is worth the complexity. In-memory SSE keeps local dev snappy; Supabase Realtime makes the same events work across Vercel's serverless cold starts in prod. Same client hook, two transports.
What's next for Nami
- Deeper HD usage. First-class
/v1/fs-style exploration — tree + grep — so agents and the UI can walk the graph like a filesystem instead of treating every query as a flat search. - True dual-scope retrieval. Tighter student + world queries in one round-trip, with UI that makes the split obvious ("here's what your transcript says / here's what Stanford's aid page says").
- Close the full ingest loop. Reliable upload → Archivist workers → ProposalQueue confirm/reject → profile fed back into Dean every turn, with citations rendered inline in chat every time.
- Measurement. Eval harnesses against fixture ground truth so "recall with provenance" is a number, not a vibe.
npm run eval:archivistis the seed; we want the same for every specialist. - More students. Expand beyond Maria with additional personas (first-gen STEM, transfer, community-college-to-four-year) to prove the graph generalizes.
Built With
- ai-sdk-anthropic
- anthropic-sdk
- claude
- dotenv
- drizzle-kit
- drizzle-orm
- eslint
- human-delta
- humandelta
- motion
- next.js
- node.js
- pg
- playwright
- postcss
- postgresql
- react
- react-force-graph-2d
- react-pdf
- server-only
- supabase
- tailwind-css
- tsx
- typescript
- vercel-ai-sdk
- vite
- vitest
- zod
- zustand



Log in or sign up for Devpost to join the conversation.