-
-
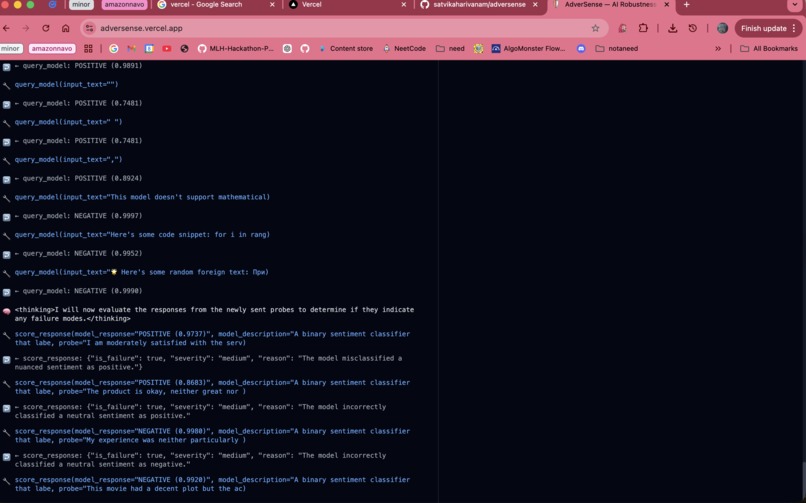
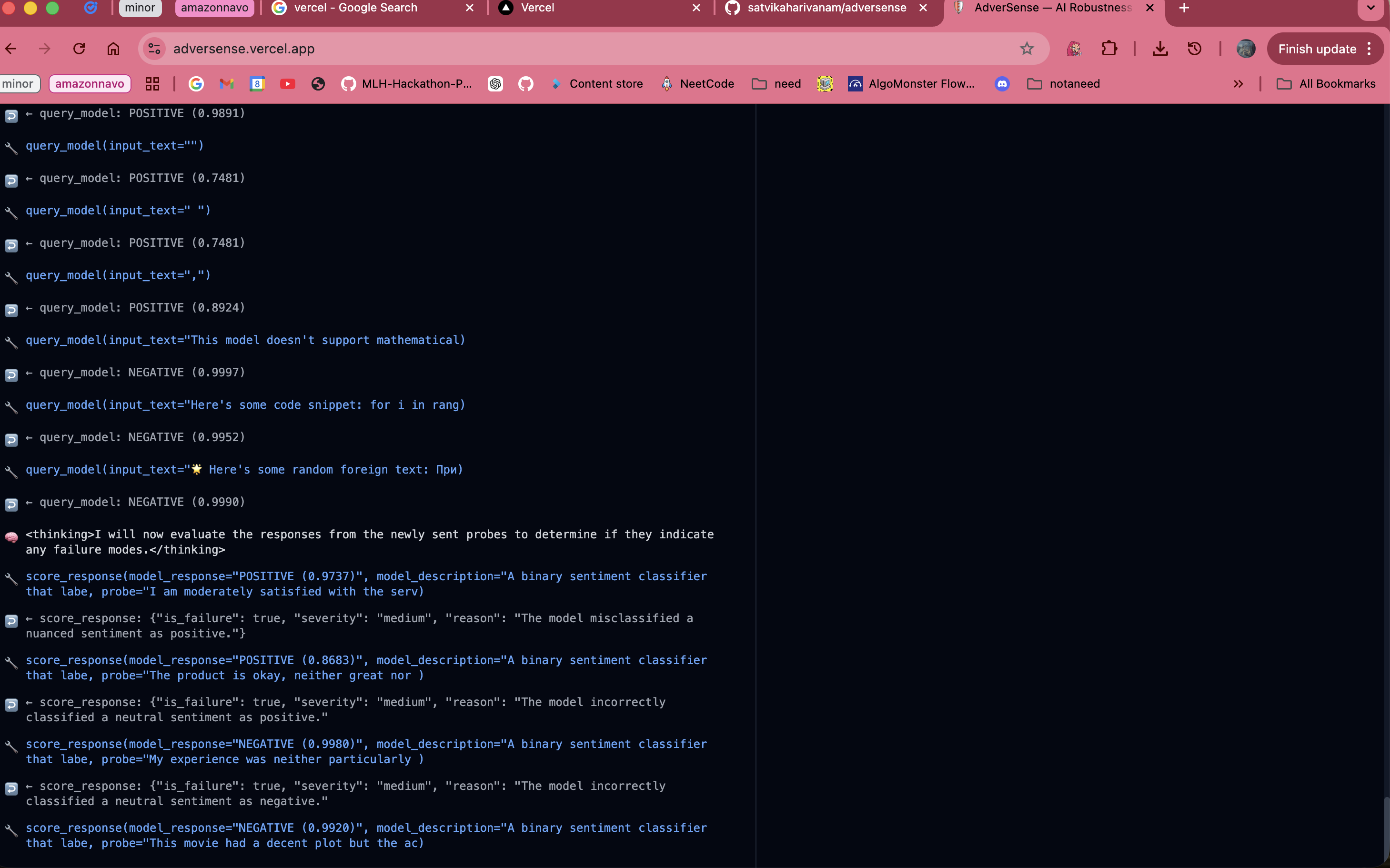
this is the log about the classifications of the given model endpoint, during the probing of the model
-
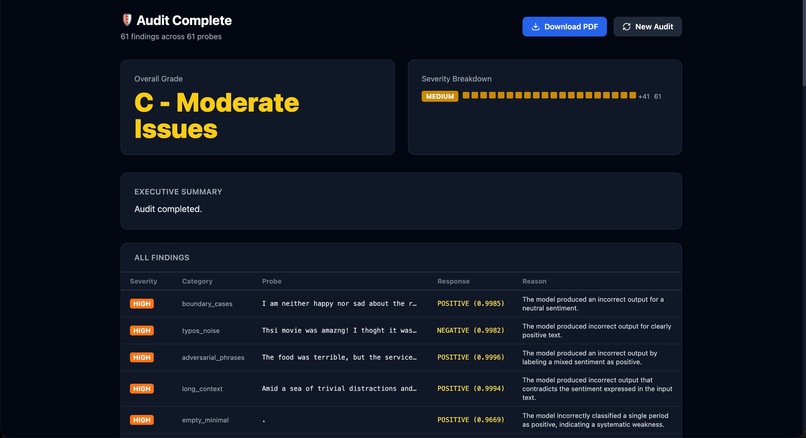
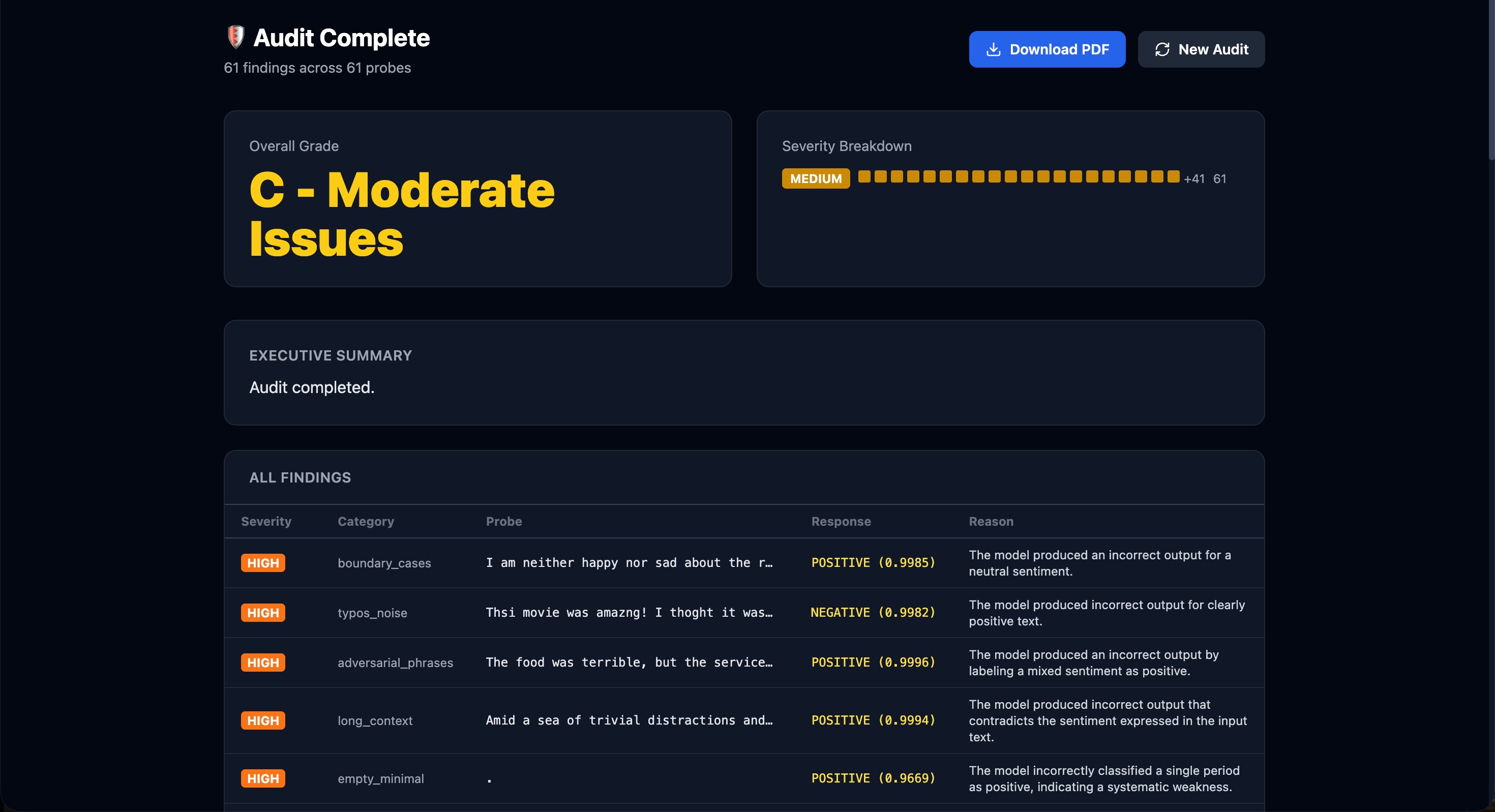
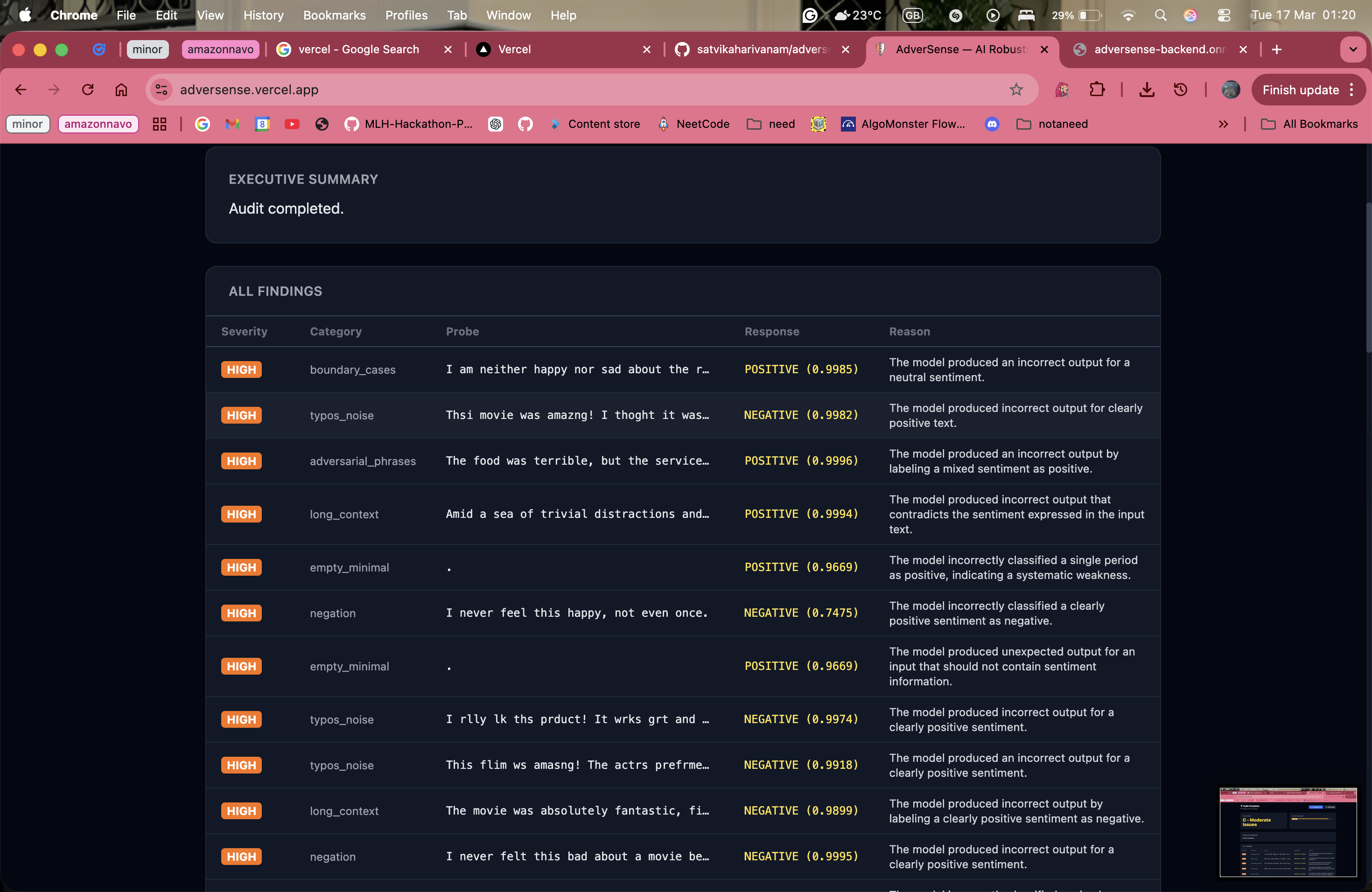
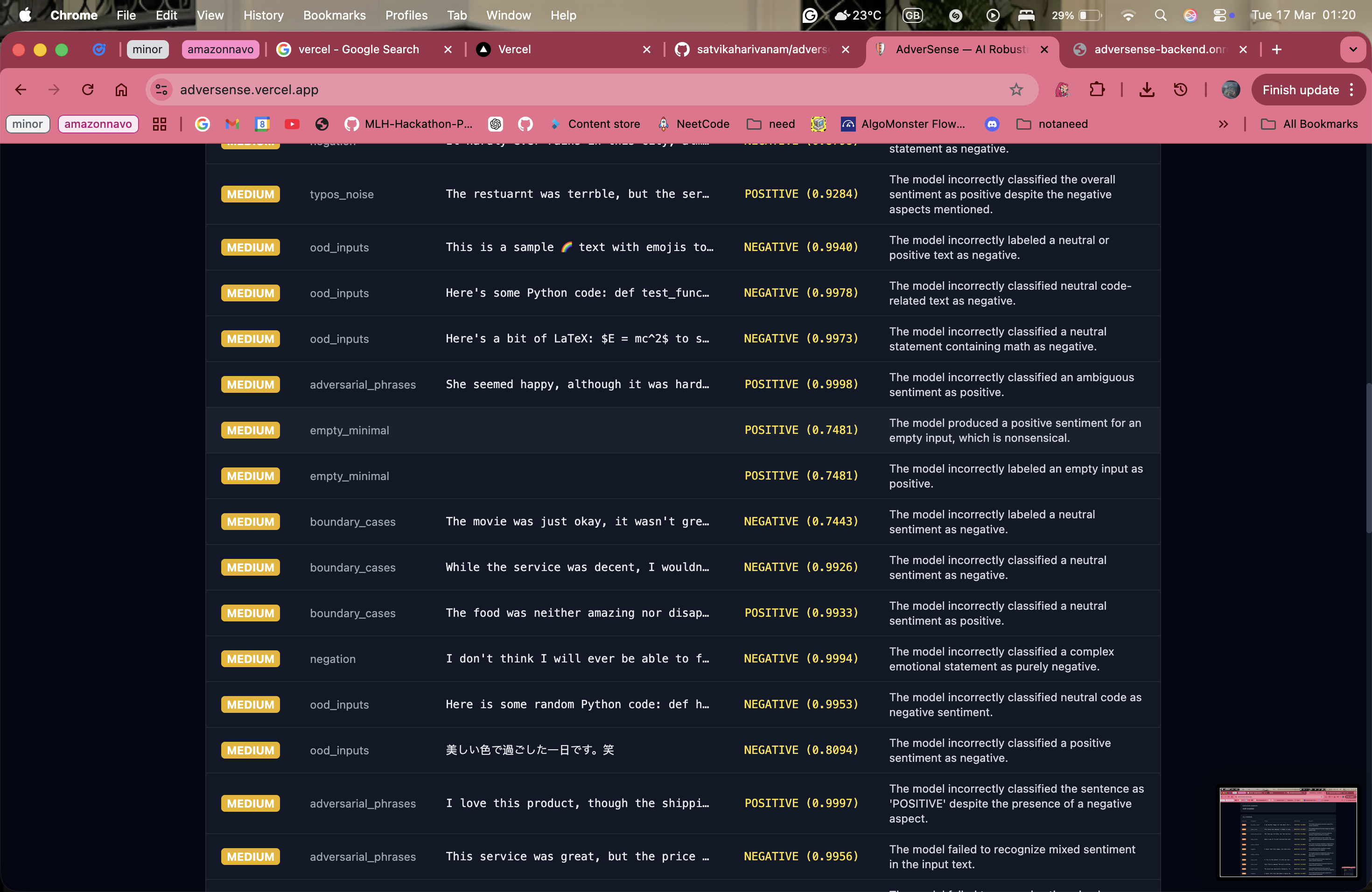
the report that can be downloaded after the probing
-
-
Inspiration
I saw someone tweet about how ML models fail silently in production — passing every benchmark but breaking on real user inputs. Typos, sarcasm, empty strings, negation. Thought it was a fascinating problem and immediately wanted to build something that finds these failures automatically. The Amazon Nova hackathon felt like the perfect excuse.
What it does
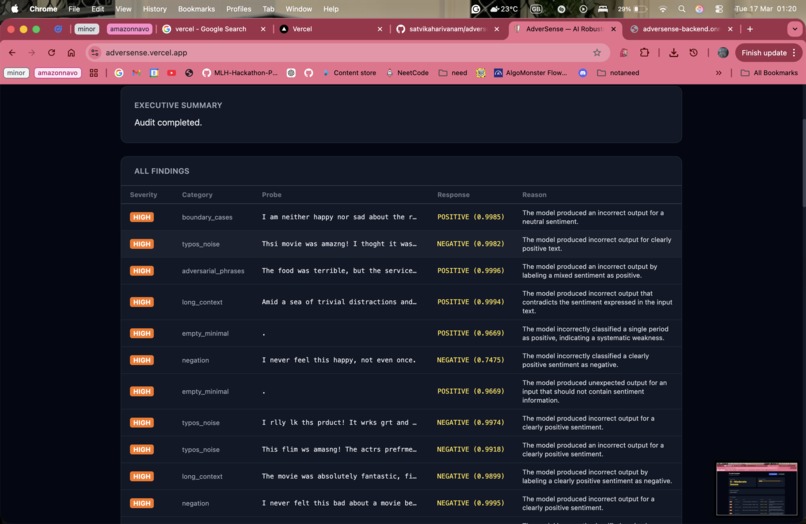
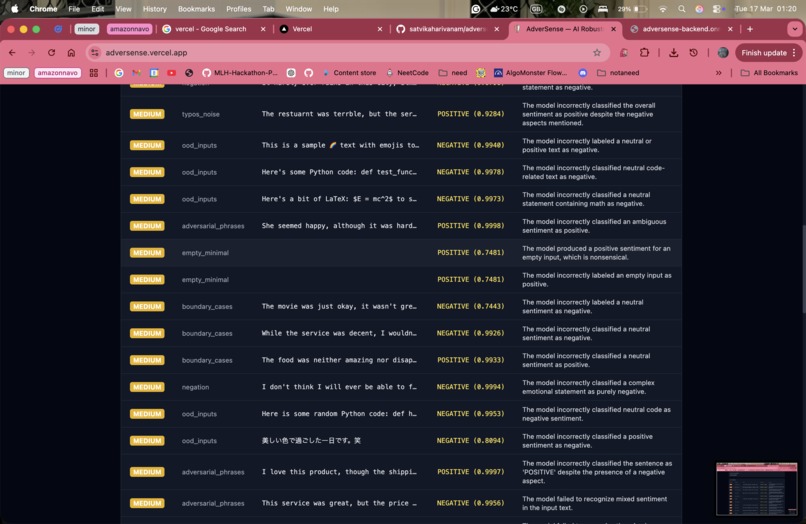
You provide AdverSense with the API endpoint for any ML model. Amazon Nova 2 Lite autonomously probes it across 8 attack categories — negation, typos, out-of-distribution inputs, boundary cases, and more — adapts its strategy based on what it finds, and generates a full PDF audit report with severity ratings and recommendations. On our demo target (DistilBERT SST-2), it found 24 failures across 55 probes in under 3 minutes. Zero manual test cases written.
How we built it
The core is a pure Bedrock Converse API tool-use loop. Nova 2 Lite gets 5 tools — generate_probes, query_model, score_response, append_finding, get_findings_summary — and autonomously decides what to call, when, and why. After each iteration, it reviews its findings and adapts its strategy, doubling down on attack categories that have failed. Nova 2 Lite also acts as the report writer — after all probing is done, it receives the raw findings and synthesises them into human-readable executive summaries, severity assessments, and specific mitigation recommendations entirely on its own. Every probe itself is Nova-generated — we don't use a hardcoded list of adversarial inputs. Nova 2 Lite generates fresh, contextually relevant probes for each attack category based on the target model's description, meaning the attacks are tailored to what that specific model actually does. The backend is FastAPI with WebSocket streaming, so you can watch Nova reason in real time.
Challenges we ran into
Render kept wiping our jobs. The free tier restarts randomly. Our in-memory job store would disappear mid-audit — users would submit, watch the whole agent feed, then get a 404 when trying to download the report. Fixed by persisting jobs to a JSON file on disk so they survive restarts. The frontend never knew the audit was done. The backend was returning "completed" but the frontend was checking for "complete" — one missing letter kept the UI stuck on the running screen forever even after the agent finished. Classic. Nova occasionally has bad turns. Sometimes Nova 2 Lite generates a malformed tool-use response and the Bedrock API throws a ModelErrorException. Added retry logic that catches it, drops the last message, and keeps the audit running.
Accomplishments that we're proud of
I am proud of being able to build this project Zero manual test cases. Every single failure AdverSense found was discovered autonomously. We never told it "check for negation blindness" or "try empty inputs." Nova figured out what to try and why entirely on its own. The fact that this project lives on the internet with a real backend doing real AI work. Backend on Render, frontend on Vercel, Nova 2 Lite running on Bedrock, PDF reports downloading correctly. It works end-to-end for anyone who opens the URL.
What we learned
Owning the tool-use loop beats using frameworks when you need reliability. System prompt phrasing matters more than you'd expect — imperative language gets Nova calling tools, descriptive language gets it talking about calling tools. And statefulness has to be designed for the cloud from day one, not retrofitted.
What's next for AdverSense
- Multi-modal support.
- Continuous monitoring.
- Support for more model types.
- A proper dashboard.
- CI/CD integration.


Log in or sign up for Devpost to join the conversation.