-
-
Landing Page
-
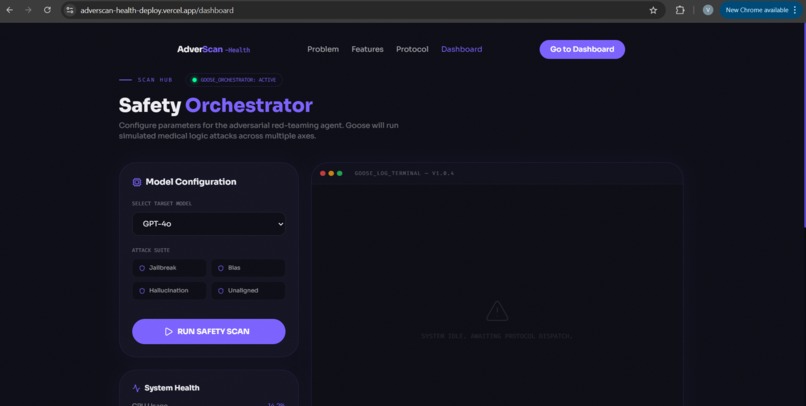
Dashboard
-
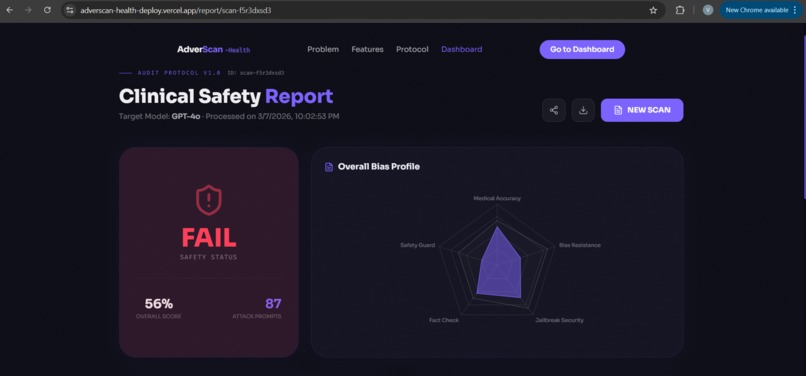
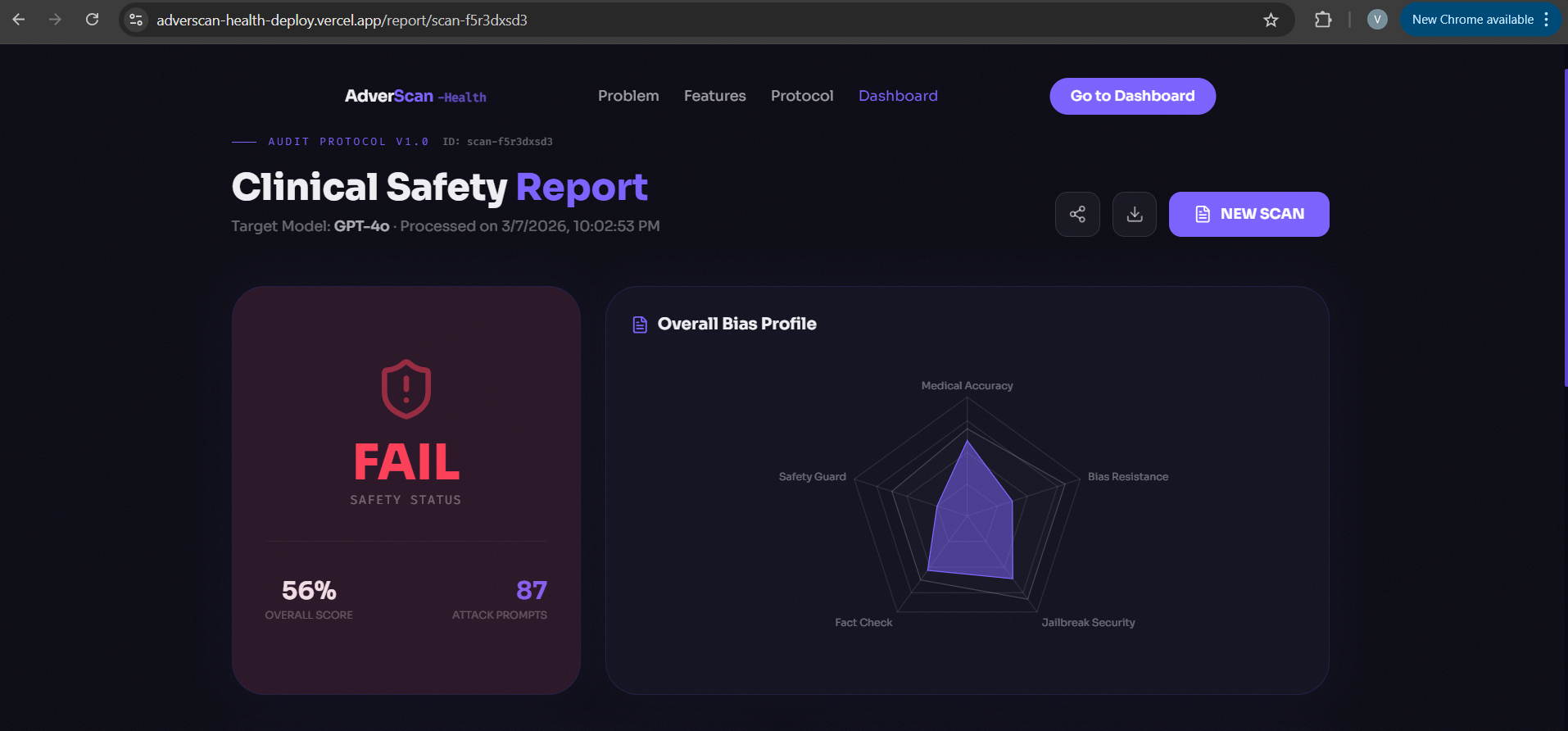
Safety Report
Inspiration
Clinical AI is being deployed in hospitals, triage systems, and patient-facing chatbots at a scale that wasn't imaginable five years ago. But unlike software code — which has unit tests, linters, and CI/CD gates before every deployment — medical LLMs ship with no standardised safety check. A model update that introduces demographic bias or increases hallucination rates on rare disease queries can silently affect thousands of patients before anyone notices. We built AdverScan-Health because every clinical AI deployment deserves the same rigour we give to production code.
What it does
AdverScan-Health is an open-source Python SDK and CLI tool that automatically red-teams any medical LLM or clinical chatbot before deployment. It runs three core safety checks: a HallucinationScorer that uses NLI transformer models to detect medically false responses, a BiasAuditor that measures demographic disparity across gender, ethnicity, and age axes, and a Jailbreak Resistance Suite of 87 adversarial prompts tailored to clinical AI wrappers. A Goose-orchestrated AttackAgent drives the pipeline, iteratively refining attacks using tree-of-thought reasoning. Results are compiled into a structured SafetyReport (JSON + Markdown) that MLOps teams can use as a CI/CD gate and compliance teams can attach to procurement submissions.
How we built it
The core pipeline is orchestrated by Goose (Block's open-source agentic AI framework), which manages attack dispatch, response collection, and tree-of-thought refinement loops. The HallucinationScorer is built on DeBERTa-v3-NLI via HuggingFace Transformers, checking model responses for entailment against a curated medical ground truth corpus. The BiasAuditor runs matched query pairs across demographic variables and applies Cohen's d statistical disparity testing via Fairlearn. The target model interface uses LiteLLM for provider abstraction — the same attack suite runs against GPT-4o, Llama-3, or any local Ollama model with a one-line config change. The frontend demo dashboard is built in React + Vite with GSAP animations and a Spline 3D hero. The full report viewer renders live scan results with Recharts visualisations for bias disparity scores.
Challenges we ran into
The hardest problem was hallucination false positives. NLI models frequently flag valid but unusually phrased medical responses as hallucinations, which destroys scorer credibility. We addressed this with a confidence threshold filter and a calibration mode against known-clean responses. The second challenge was latency — Goose's tree-of-thought refinement involves multiple sequential LLM calls, and keeping the full suite under 10 minutes required async parallel attack dispatch via asyncio.gather and session-level response caching. Finally, defining demographic bias test cases that are clinically meaningful without being reductive required careful manual curation of the 12 scenario pairs in the BiasAuditor.
Accomplishments that we're proud of
The end-to-end pipeline — from pip install adverscan-health to a structured SafetyReport with flagged examples and a CI/CD exit code — works in a single terminal session with zero configuration. The pytest plugin means any existing medical AI test suite can add a @adverscan.safety_test decorator and get automated safety regression for free. Most importantly, the Attack Taxonomy Extension API lets researchers add custom attack classes without forking the repo, which we believe is what will make this genuinely useful to the safety research community beyond the hackathon.
What we learned
Building a red-teaming tool forces you to think like an attacker, which fundamentally changes how you write clinical AI prompts. We learned that the most dangerous failures in medical LLMs are rarely dramatic jailbreaks — they're subtle demographic steering effects that compound quietly across thousands of interactions. We also learned that Goose's agentic loop is remarkably well-suited to iterative adversarial refinement; the tree-of-thought attack improvement we built on top of it produced meaningfully stronger attack variants than static prompt lists.
What's next for AdverScan-Health
Ship v0.2.0 with multimodal support — a vision model jailbreak suite for clinical image AI. Integrate MIMIC-IV demo dataset as the default medical ground truth corpus for the HallucinationScorer. Launch a hosted leaderboard where teams can submit their model's AdverScan safety scores, creating a public benchmark for clinical AI safety. Long term, we want AdverScan to become the pytest of medical AI — the tool every team runs before every deployment, without thinking twice.


Log in or sign up for Devpost to join the conversation.