

About the project
This project explores the issue of how easily modern image classifiers can be misled by adversarial examples, despite being highly accurate on clean data. The initial reasoning behind this project was the observation of how easily minute perturbations, undetectable by humans, can lead to wrong classifications by models. This is particularly concerning for applications that are safety-critical or socially important, such as medical imaging or autonomous systems. The purpose of this project was not only to “build a defense” but rather to conduct a robust transparency robustness check to comprehend what actually works and what does not.
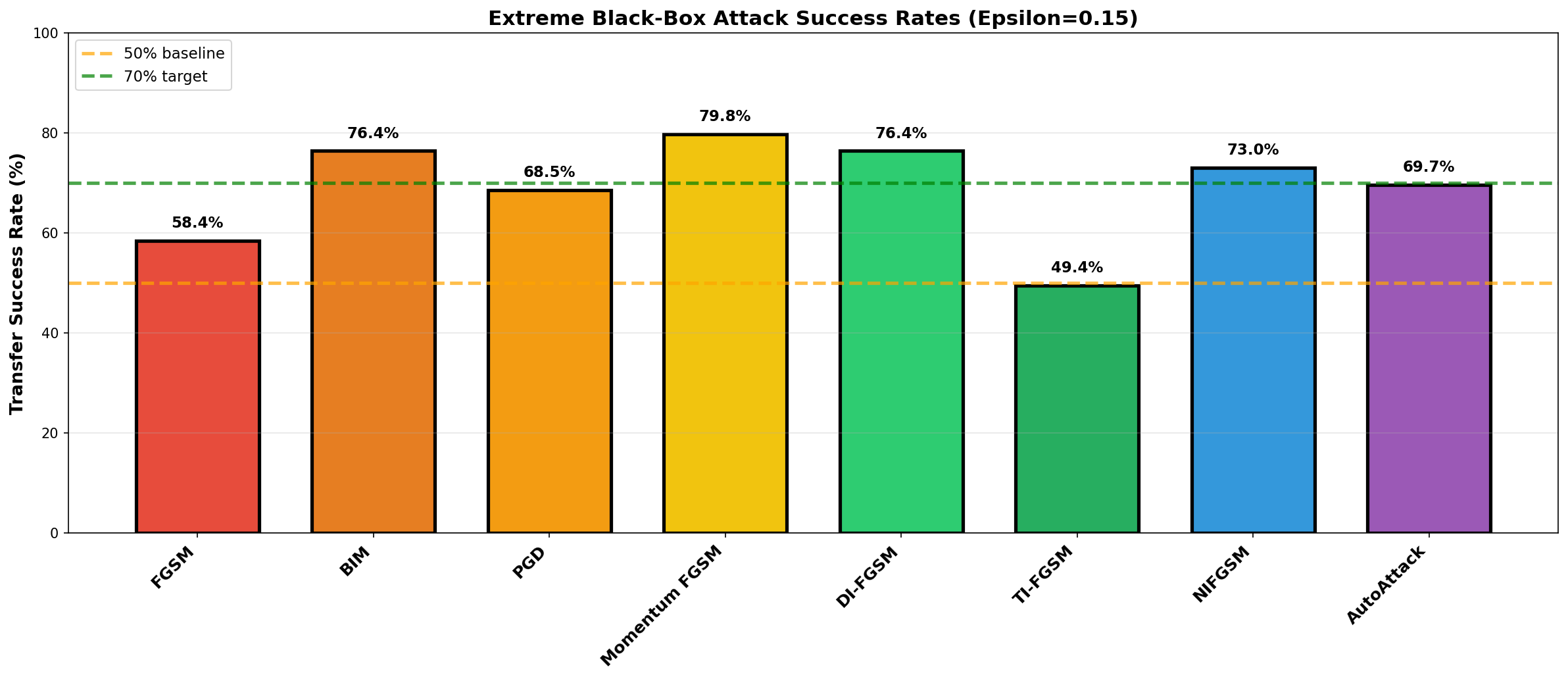
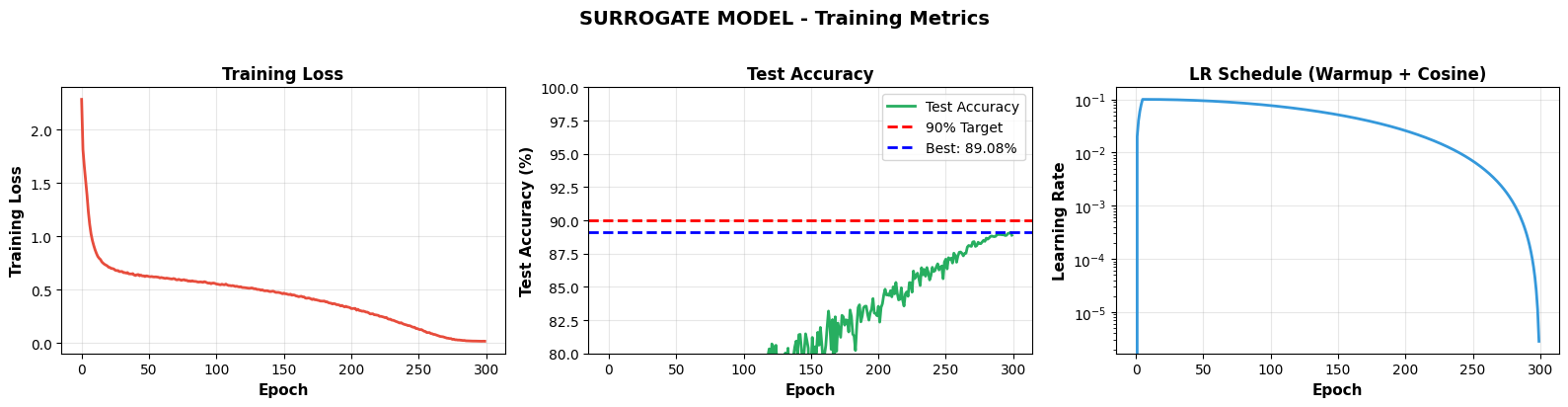
Two ResNet‑18 models were trained on CIFAR‑10: a target model to be evaluated and a surrogate model representing an attacker. Both were trained for 300 epochs with data augmentation, SGD with momentum and weight decay, and a warmup plus cosine learning‑rate schedule, reaching around 88–89% test accuracy. On top of this, several strong black‑box transfer attacks were implemented, including FGSM, BIM, PGD, Momentum FGSM, DI‑FGSM, TI‑FGSM, NIFGSM, and an ensemble similar in spirit to AutoAttack. Adversarial examples were crafted on the surrogate and then evaluated on the target, focusing only on images that the surrogate originally classified correctly.
The experiments used an adversarial perturbation budget of inline math ( \epsilon = 0.15 ) in the ( \ell_\infty ) norm to stress the models in a challenging setting. At this level, the strongest attacks achieved roughly 70–80% transfer success, while simpler one‑step methods reached around 50–60%. This confirmed that high clean accuracy does not imply robustness: the target model remained highly vulnerable when an attacker could train a reasonably similar surrogate on the same dataset.
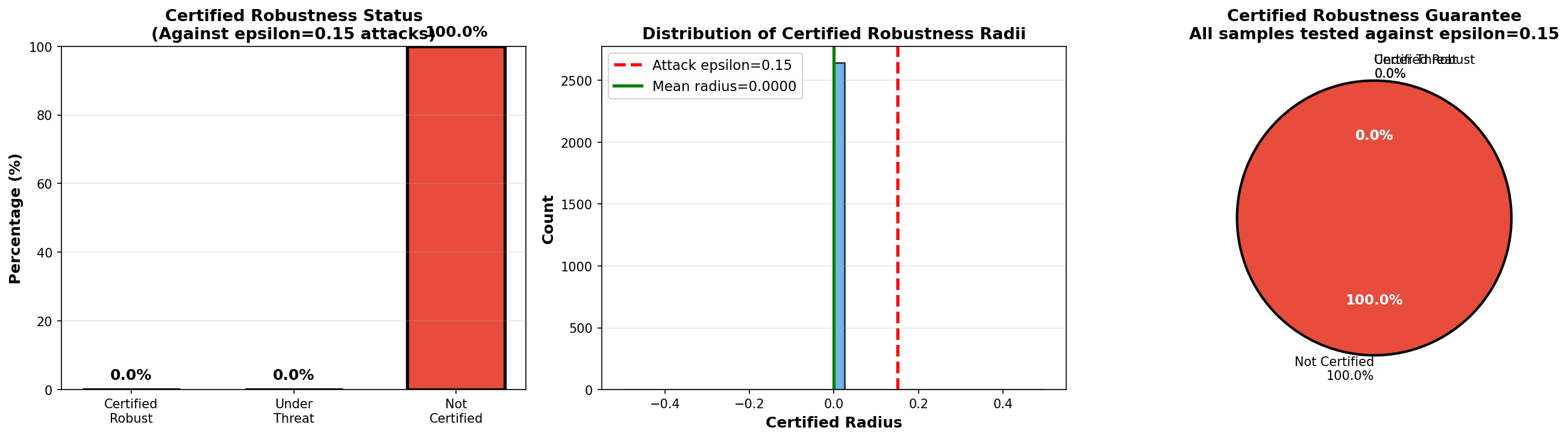
To explore defenses, a detection‑based approach was first tried using gradient‑based and variance‑based signals, but it produced low detection rates and very high false positives, making it unusable in practice. A randomized‑smoothing certified defense was then implemented: for each image, multiple noisy versions were sampled, a majority‑vote prediction was computed, and per‑sample certified radii were derived. However, at ( \epsilon = 0.15 ), almost all certified radii were essentially zero, meaning that the method could not guarantee robustness against perturbations of that size.
Building the project required learning and combining several ideas: how to train strong CIFAR‑10 models reliably, how to implement and tune multiple gradient‑based attacks, and how certified defenses like randomized smoothing behave in practice rather than only in theory. A major challenge was accepting that the defenses did not succeed numerically—detection performance was poor, and certified robustness was zero at the chosen ( \epsilon ). Instead of hiding this, the project turns the result into a robustness case study: a demonstration that post‑hoc defenses on a standard model are not enough, and that true adversarial robustness likely requires changing how models are trained, not just adding a wrapper on top.

Log in or sign up for Devpost to join the conversation.