-
-
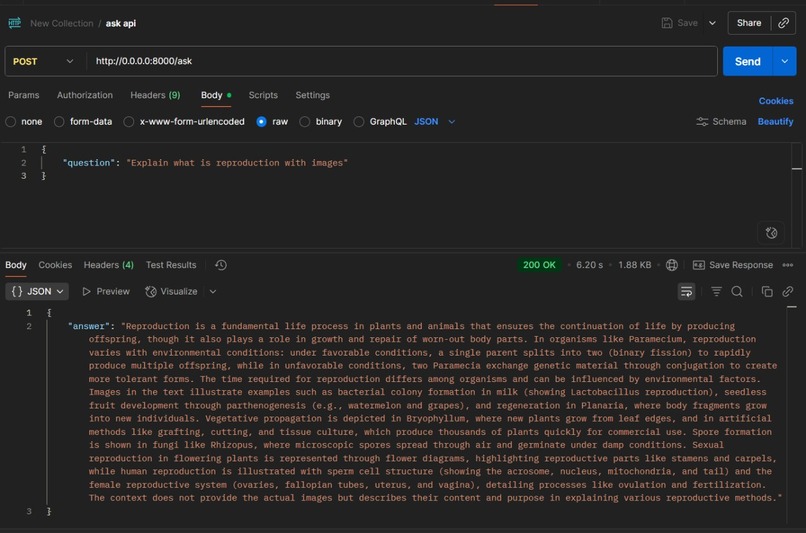
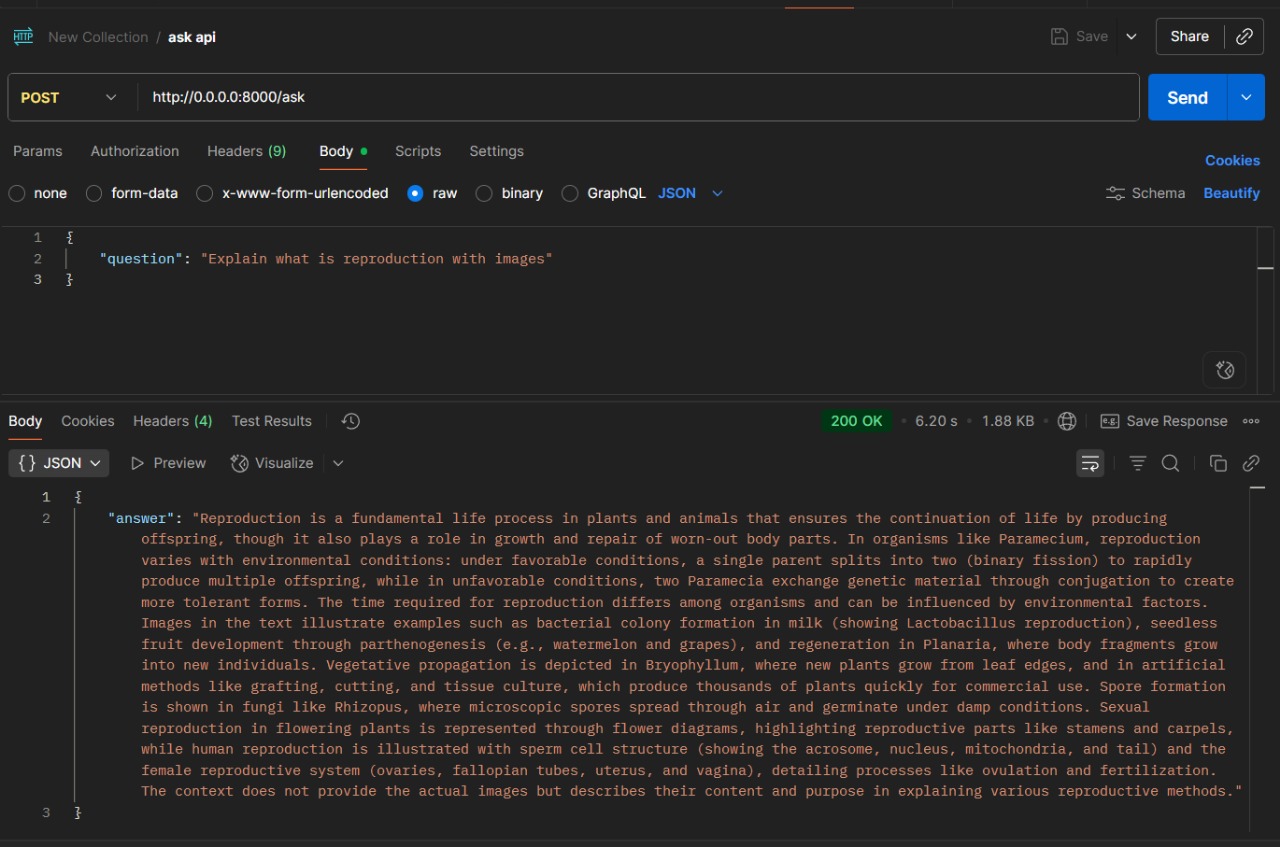
API working for human reproduction Textbook
-
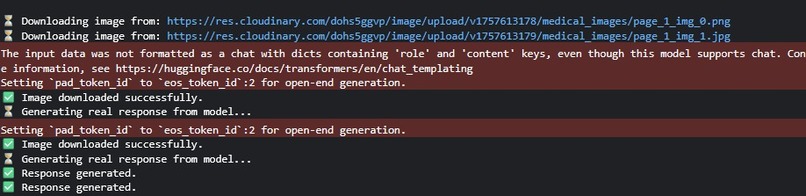
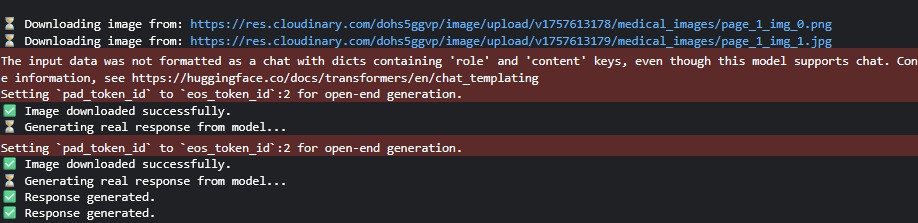
API Logs for building ngrok server in kaggle.
Inspiration
The inspiration for this project stemmed from the observation that current educational Q&A systems primarily focus on text retrieval, largely neglecting the rich visual information embedded in educational documents like diagrams, charts, and illustrations. This limitation is particularly significant in STEM subjects, where 30-40% of educational materials are visual. Existing AI-based tutoring systems struggle with structured constraints and providing clear, step-by-step explanations for logical reasoning problems, often failing visual learners due to a lack of contextual analysis and semantic connections between visual and textual content.
The emergence of Vision-Language Models (VLMs) provided a promising avenue to overcome these limitations, enabling machines to understand and analyze images. Our goal was to leverage these advancements to create an AI-driven framework that could not only retrieve relevant text but also integrate visual content with contextual image analysis and semantic linking, thereby providing comprehensive and pedagogically effective responses. What We Learned
Throughout the development of this multimodal document question-answering system, several key insights were gained:
Multimodality is Complex: Effectively representing and merging three modalities—text, spatial layout, and visual elements—is a significant challenge in visually-rich documents (VRDs).
VLM Capabilities and Limitations: Vision-Language Models are powerful for fusing visual and language information. However, we learned about critical challenges such as "visual hallucination" and the importance of proper alignment and benchmarking for VLMs.
Leveraging LLMs as Backbones: VLM architectures are shifting from being trained from scratch to leveraging the powerful reasoning capabilities of pre-trained Large Language Models (LLMs) as a backbone. This informed our approach of using LLMs like Mistral for answer generation.
Importance of Contextual Augmentation: Simply extracting text and images separately is insufficient. The ability to semantically link VLM-generated image descriptions with document text is crucial for creating comprehensive responses. This led to the development of our "multimodal chunks."
Efficient Retrieval and Reranking: For effective retrieval, a combination of embedding models (like BAAI/bge-large-en-v1.5) for similarity search and reranking models (BAAI/bge-reranker-large) for refining relevance is essential to achieve high accuracy.
How We Built the Project
Our project was built as an AI-driven framework with an integrated visual-textual retrieval system, featuring contextual image analysis and semantic linking. The core components and workflow are as follows:
PDF Ingestion and Parsing: We started by developing a robust PDF parsing mechanism to extract both raw textual content and visual elements (images) from educational documents like AP State High School Textbooks (Biology, Physics). The location of each image within the document was also recorded.
Image Analysis with LLaVA VLM: For each extracted image, we utilized a Vision-Language Model (LLaVA VLM via Kaggle ENV API server) to generate a detailed textual description or caption. This transformed visual information into a textual format that could be processed alongside the document's text.
Contextual Chunking and Semantic Linking: This was a crucial step in achieving multimodal integration. We designed a RecursiveSplit function to intelligently chunk the text. When an image was detected, we created "multimodal chunks" by combining the text immediately preceding and following the image with its VLM-generated description. This semantic linking ensured that the visual context was integrated directly into the textual chunks.
Embedding and Vector Database: All generated chunks (both text-only and multimodal) were then converted into vector embeddings using the BAAI/bge-large-en-v1.5 embedding model. These vectors, along with metadata (including image identifiers for multimodal chunks), were stored in a Vector DB (FAISS-DB/ChromaDB) for efficient retrieval.
Query Processing and Retrieval: When a user poses a question, it is first converted into a query vector using the same embedding model. A similarity search (Cosine Similarity) is performed on the Vector DB to retrieve the top k most relevant chunks.
Reranking for Accuracy: To further enhance the relevance of retrieved chunks, a reranking step was incorporated using the BAAI/bge-reranker-large model. This cross-encoder model takes the query and candidate chunks to output a highly accurate relevance score, reordering the chunks from highest to lowest score.
Answer Generation with Mistral AI: The top-ranked, most relevant chunks (containing both textual and, if applicable, semantically linked visual information) are fed as context to an LLM (Mistral AI, specifically Mistral-7b-large or mistral-small-latest via Mistral API). The LLM then synthesizes this information to generate a comprehensive text answer.
Multimodal Output: If the retrieved context included a multimodal chunk, the associated image file is retrieved using its identifier from the metadata and presented alongside the generated text answer, offering a truly multimodal response to the user.
Challenges Faced
Throughout the project, we encountered several challenges that pushed us to refine our approach:
Integrating Visual and Textual Context: The primary challenge was to seamlessly integrate visual information with textual content in a meaningful way. Existing systems often failed to establish contextual analysis and semantic connections. Our solution of creating "multimodal chunks" by embedding VLM-generated descriptions directly into text chunks was a significant step in overcoming this.
Handling Diverse Reasoning Questions: Developing a classification model to categorize different types of logical reasoning and aptitude questions (e.g., seating arrangements, puzzles, syllogisms) and assigning them to suitable AI models required careful design and diverse datasets (e.g., GMAT, GRE, CAT, SQUAD2.0).
Maintaining Information Retention: Traditional TextRAG pipelines often suffer from information loss during the parsing stage of multi-modality documents. Our vision-based RAG application aimed to maximize information retention by directly embedding documents as images and leveraging VLMs, bypassing some of the error-prone text-parsing stages.
Computational Resources: Processing large documents with numerous images and running VLMs and LLMs can be computationally intensive. Optimizing the efficiency of the streaming inference for Multimodal Large Language Models (MLLMs) on a single GPU was a relevant challenge, addressed by frameworks like Inf-MLLM.
"Visual Hallucination" in VLMs: A recognized challenge with VLMs is "visual hallucination," where models generate descriptions that do not accurately reflect the image content. While we used a pre-trained VLM, mitigating this required careful selection and potential fine-tuning, as well as robust semantic linking to ensure descriptions were contextually relevant.
Effective Chunking Strategies: Determining the optimal chunk_size and separators for the RecursiveSplit function was crucial to ensure chunks were semantically coherent yet small enough for efficient processing and retrieval.
Built With
- fastapi
- kaggle
- llava
- mistralai
- pipeline
- python
- rag


Log in or sign up for Devpost to join the conversation.