-
-
Diagram
Inspiration
What it does
🏠 Smart Property Search
An event-driven, serverless data pipeline on AWS for advanced real estate property searches. This project, built with Terraform, enables semantic and visual similarity searches on property images, moving beyond traditional metadata-based queries.
💡 Inspiration
In the real estate industry, search capabilities are fundamental. Traditionally, searches rely on structured, manually tagged metadata like the number of rooms, city, or price. This process is not only slow and prone to human error, but it also fails to capture the subjective essence and ambiance of a property. The challenge is to overcome these limitations and allow users to perform more human-like and visual searches, such as:
- Semantic Search: Finding properties based on conceptual descriptions. For example, instead of just filtering for "4 rooms," a user can search for "a rustic kitchen with plenty of natural light," "a backyard safe for kids and pets," or "a living room with a cozy fireplace perfect for winter nights."
- Visual Similarity Search: Discovering properties that look like an image the user likes. A potential buyer might upload a photo from an interior design magazine or a Pinterest board, wanting to find homes with a similar architectural style, color palette, or overall aesthetic.
To achieve this, a system is needed that not only stores images but also "understands" their content and context, cataloging them automatically, scalably, and cost-effectively.
🚀 What it does
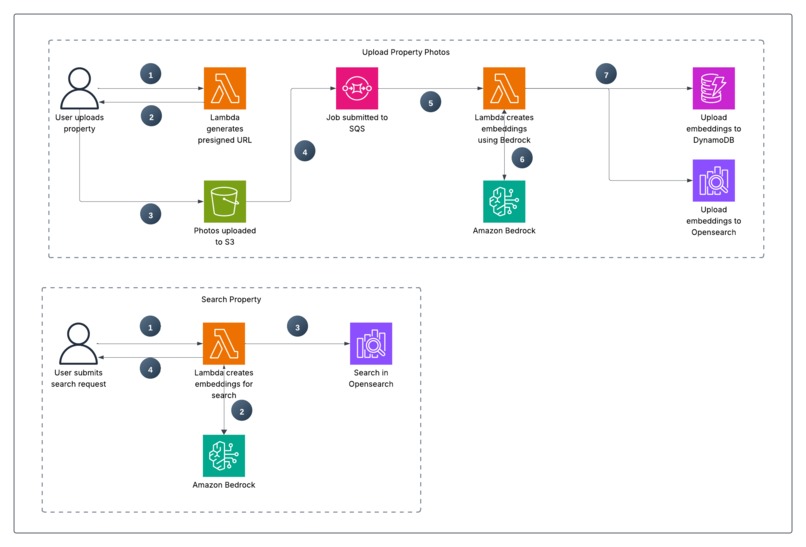
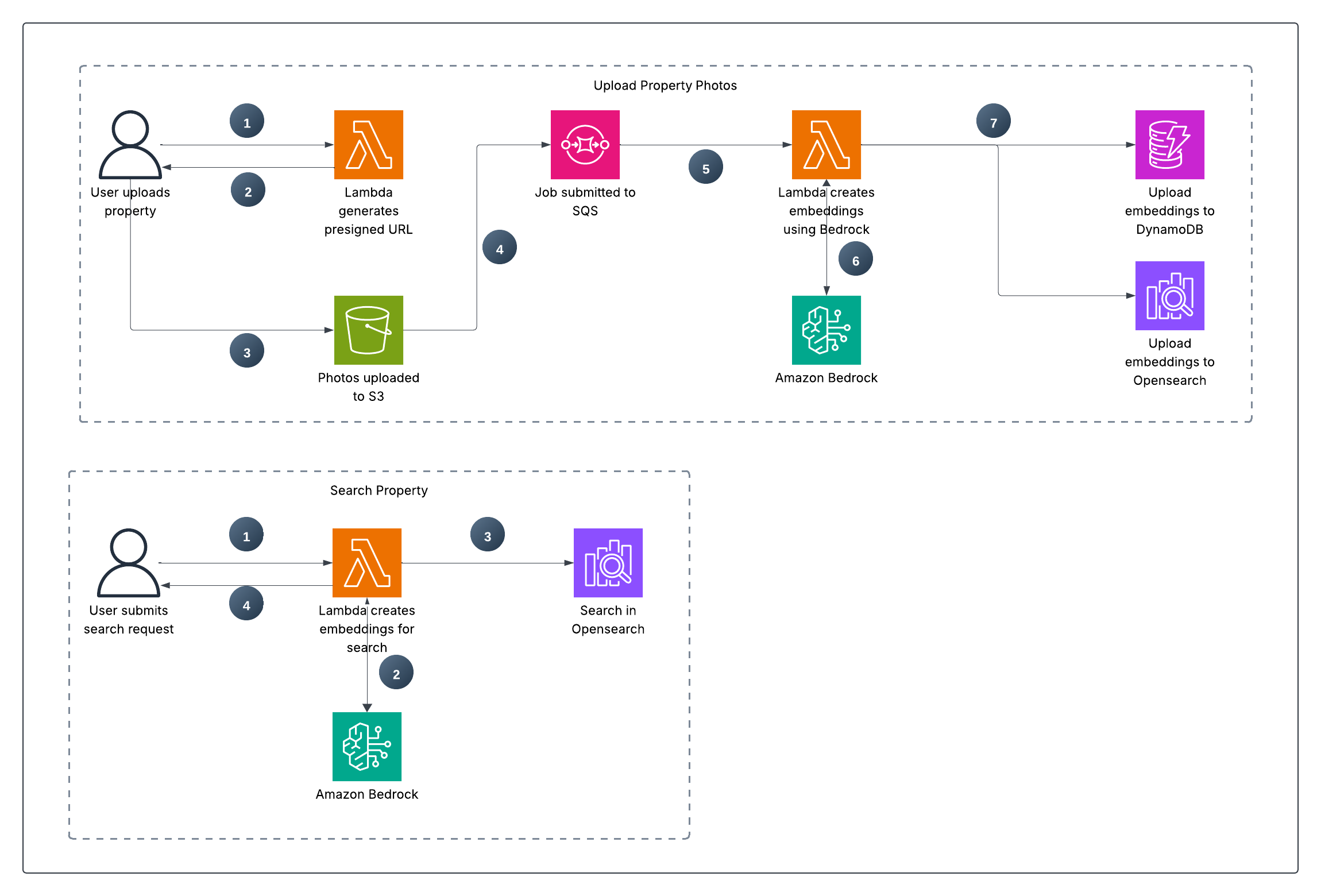
This project solves the challenge by implementing a serverless, event-driven architecture on AWS. AWS Lambda is the core of this solution, acting as the compute engine that runs the business logic without the need to manage servers.
The process is as follows:
- Image Upload: A real estate agent uploads a property image to a dedicated S3 bucket.
- Event Trigger & Decoupling: The upload triggers an event, which is sent to an SQS queue. This decouples the upload from the processing, ensuring that even if the processing function fails temporarily, the request isn't lost. It can be retried automatically, making the entire data ingestion pipeline highly robust and fault-tolerant.
- Intelligent Processing: An AWS Lambda function is triggered by the SQS message. This function orchestrates the intelligence pipeline:
- It uses Amazon Bedrock to analyze the image, generating both a rich, multi-dimensional vector embedding (a numerical representation of its features) and a human-readable descriptive text.
- It stores the original image metadata, the generated description, and the vector embedding in Amazon DynamoDB for persistent, fast-access storage.
- It indexes the vector embedding in an Amazon OpenSearch Serverless collection. This specialized index allows for incredibly fast k-Nearest Neighbors (k-NN) queries, finding the 'closest' images in the database in milliseconds.
- Advanced Search API: A separate Lambda function, exposed via a Lambda Function URL, provides a simple and secure API endpoint. Users can submit search queries with either text (for semantic search) or another image (for visual similarity search), and the function retrieves the most relevant results from OpenSearch and DynamoDB.
🏗️ How I built it
The entire infrastructure is defined as code using Terraform, making it reproducible, versionable, and easy to manage across different environments. The architecture is designed around loosely coupled, fully managed AWS services to maximize scalability, resilience, and cost-efficiency.
- AWS Lambda: The heart of the compute layer. It's the serverless 'glue' that connects services, executing code in response to events without any server management, automatically scaling from zero to thousands of requests as needed.
- Amazon S3: Used for scalable, durable, and cost-effective storage of the original property images.
- Amazon SQS: Acts as a vital shock absorber and buffer between the image upload and the processing logic. This ensures system stability during traffic spikes and guarantees that every uploaded image will be processed.
- Amazon Bedrock: Provides on-demand access to powerful foundation models, abstracting away the complexity of hosting and scaling AI/ML infrastructure.
- Amazon DynamoDB: A NoSQL database chosen for its single-digit millisecond performance and flexible schema, which easily accommodates the varied metadata associated with different properties without requiring a rigid, predefined structure.
- Amazon OpenSearch Serverless: The powerhouse behind the advanced search. Its k-NN search capability is what translates a complex vector into a simple, ranked list of visually similar properties, making the core feature of this project possible.
- IAM (Identity and Access Management): Fine-grained IAM roles are used for each Lambda function, strictly following the principle of least privilege to ensure a robust security posture.
Architecture Diagram
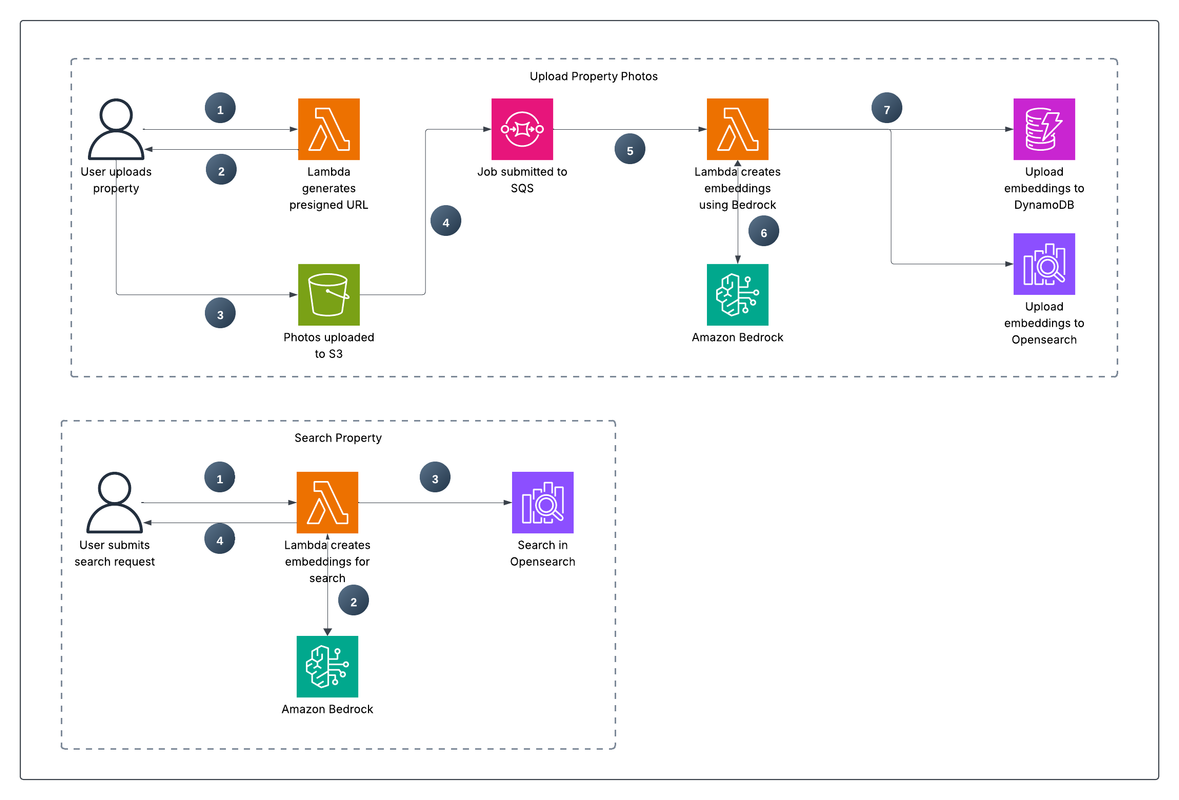
[Alt info: Image of Architecture Diagram: S3 -> SQS -> Lambda -> (Bedrock, DynamoDB, OpenSearch) | API (Lambda Function URL) -> OpenSearch/DynamoDB]
✨ Key AWS Lambda Features Used
This solution leverages several key features of AWS Lambda to build an efficient and modern serverless application:
- Event-Driven Triggers: The main processing
lambda_functionis configured with SQS as its event source. This is the fundamental mechanism that allows the architecture to be reactive, automatically initiating the processing pipeline as soon as a new image is ready. - Function-Specific IAM Roles: Each Lambda function has a unique execution role with permissions scoped down to only what is necessary. This granular approach is a cornerstone of a secure cloud architecture. By ensuring a function can only access specific resources (e.g., a single DynamoDB table), the potential impact of a security vulnerability is drastically minimized.
- Environment Variables: Critical configuration—such as the OpenSearch collection endpoint, DynamoDB table name, or logging levels—is passed to the Lambdas via environment variables. This practice separates configuration from code, preventing sensitive data from being hardcoded and making the application portable across different stages (dev, test, prod).
- Lambda Function URLs: The
search_lambdauses a Lambda Function URL to provide a dedicated HTTPS endpoint. This feature simplifies the architecture by eliminating the need for an API Gateway for simple use cases, reducing both cost and configuration overhead. It's ideal for single-function microservices. - AWS SDK Integration: The Lambda functions (written in Node.js) use the AWS SDK to programmatically interact with other services. The SDK handles authentication, retries, and serialization, acting as the "glue" that enables the Lambda to seamlessly orchestrate the workflow between S3, Bedrock, DynamoDB, and OpenSearch.
🚀 Deployment
Prerequisites
- AWS CLI configured with appropriate permissions.
- Terraform CLI (v1.0 or later) installed.
Quick Deploy
- Clone the repository.
- Create a
terraform.tfvarsfile from theterraform.tfvars.exampleand populate it with your desired values. - Initialize the Terraform working directory:
bash $ terraform init - Apply the configuration to deploy the resources to your AWS account:
bash $ terraform apply - When prompted, review the plan and confirm the deployment by typing
yes. The API endpoint will be displayed in the outputs upon completion.
🏆 Accomplishments that I'm proud of
I am proud of designing and building a fully event-driven, scalable, and cost-efficient serverless architecture from the ground up. The decoupling of components using SQS not only makes the system resilient but also allows each part to scale independently. I'm particularly proud of creating a seamless data flow where each managed service performs its role efficiently, demonstrating the power of a well-architected, composable serverless system to solve complex, real-world problems.
🧠 What I learned
This project was a deep dive into event-driven architecture and the practical application of AI/ML services in a data pipeline. Integrating multiple AWS services using Terraform and defining precise IAM permissions was a key learning experience. A major takeaway was the importance of data modeling for vector search—understanding how the quality of the generated embeddings from Bedrock directly impacts the relevance of search results. It highlighted that a successful AI application is as much about data architecture as it is about the model itself.
⏭️ What's next
- User-Facing Web Interface: Build a simple front-end application (e.g., using React or Vue) that allows users to easily upload images and perform searches in a visual, interactive way.
- Advanced Filtering: Enhance the search API to combine vector search with traditional metadata filters. This would allow for powerful hybrid queries like "a rustic kitchen in San Francisco under $2M," combining the results from OpenSearch with a filtered query on DynamoDB.
- Batch Processing: Implement a mechanism, possibly using another Lambda function triggered on a schedule, to process a large backlog of existing property images that were in the system before this pipeline was created.
How we built it
Challenges we ran into
Accomplishments that we're proud of
What we learned
What's next for Advanced IA real estate property searches
Built With
- bedrock
- ia
- lambda
- node.js
- s3

Log in or sign up for Devpost to join the conversation.