-
-
project output 1
-
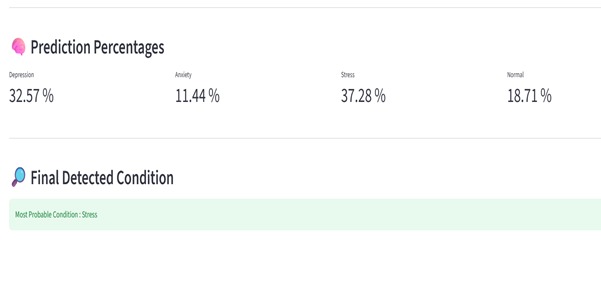
project output 3
-

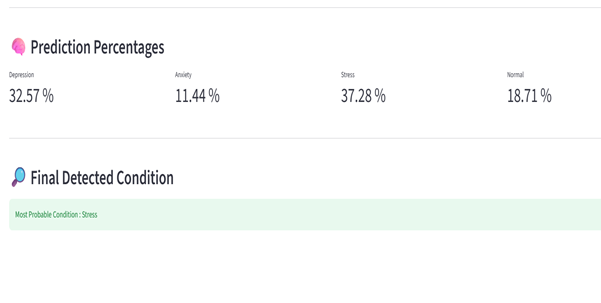
project output 2
-
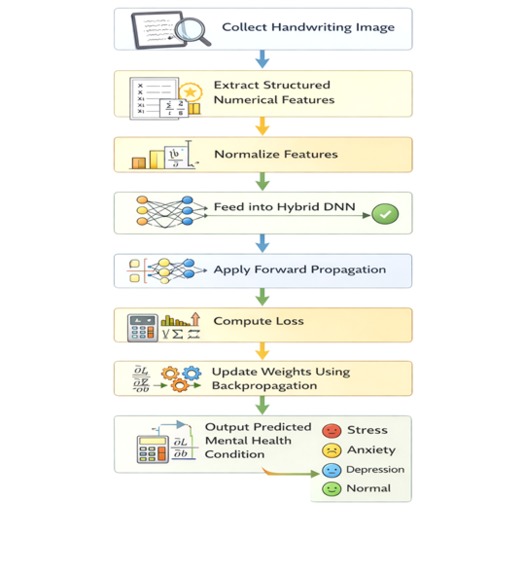
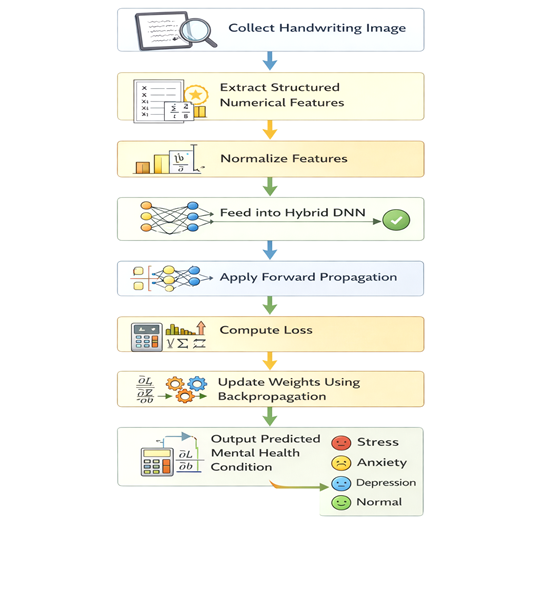
Project Workflow
-
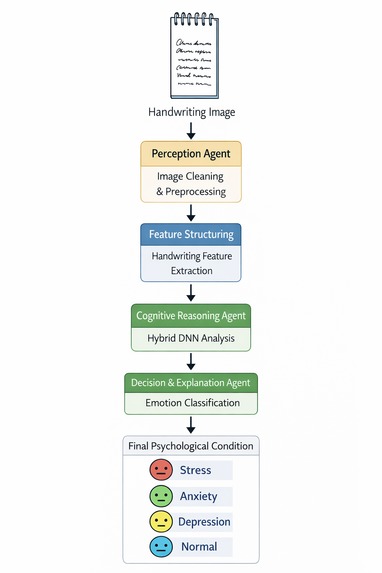
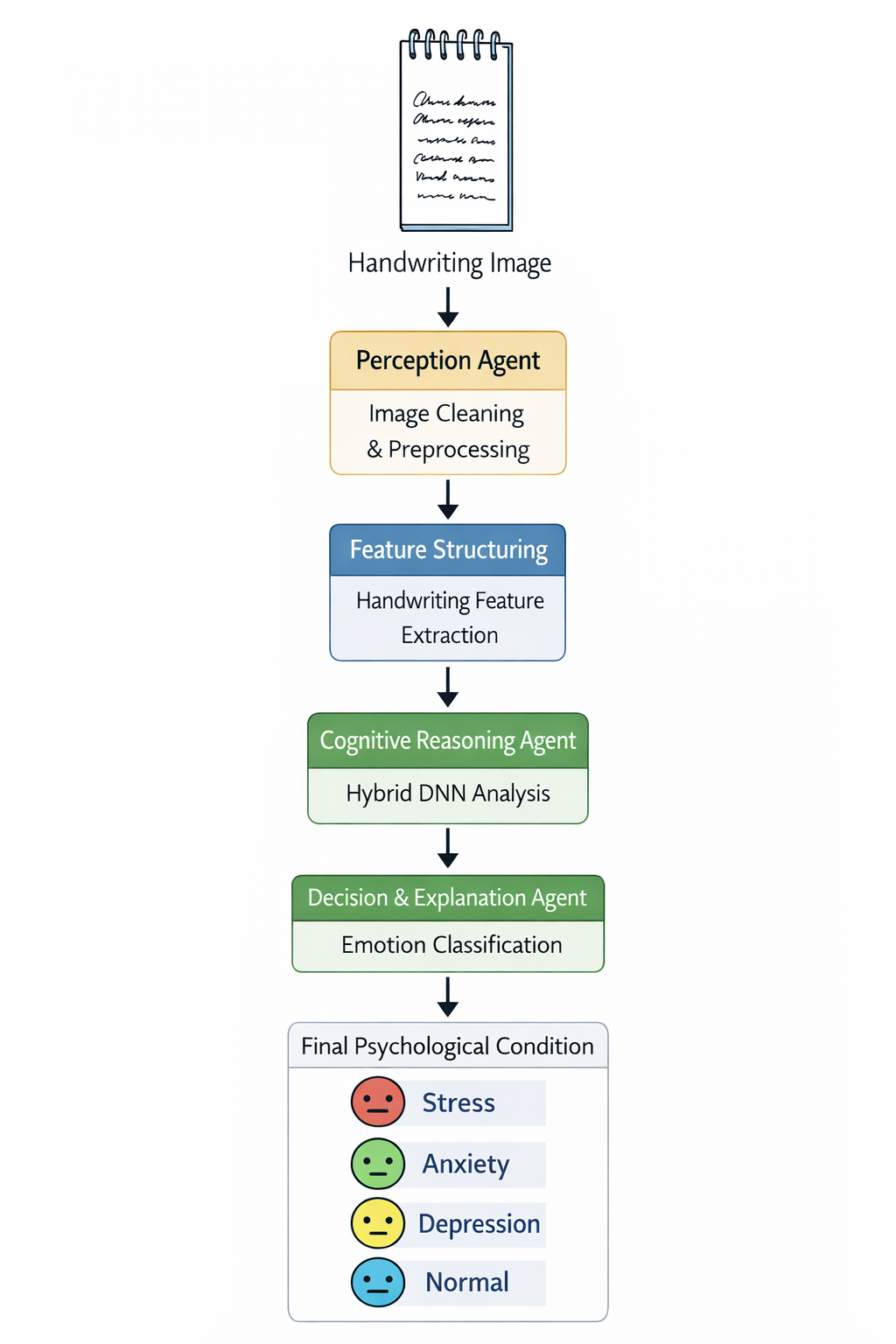
AI Agents

Inspiration
During exam season, one of our teammates noticed something strange — everyone around them looked exhausted, withdrawn, or on edge. But when asked "are you okay?", the answer was always the same: "Yeah, just tired."
That disconnect stuck with us. People weren't lying — they genuinely couldn't name what they were feeling. So we asked a different question: instead of making someone describe their mental state, what if we could observe it?
Turns out, your nervous system already leaves clues every time you write. We just needed an AI smart enough to notice them.
What it does
Our system takes a single handwriting image and predicts the writer's psychological state — Stress, Anxiety, Depression, or Normal — along with a plain-language explanation of what it found.
The pipeline runs through four purpose-built agents:
- Perception Agent — strips noise, sharpens strokes, prepares a clean image for analysis
- Feature Structuring Agent — measures letter size, word spacing, baseline drift, slant angle, and stroke pressure
- Cognitive Reasoning Agent — feeds features into a Hybrid DNN, then combines predictions using: $$P_{Final} = 0.7 \cdot P_{DNN} + 0.3 \cdot P_{Feature}$$
- Decision & Explanation Agent — delivers the final condition with a human-readable clinical reason, not just a label
Result: 93–95% accuracy in under 2 seconds, on a regular CPU.
How we built it
It started with data — 413,701 handwriting images, four classes, roughly balanced, all collected with informed consent and fully anonymised before we touched a single file.
Preprocessing was built in OpenCV. Training used a Hybrid Deep Neural Network — convolutional layers for visual pattern learning, dense layers (64 → 32 → 16 neurons) for decision-making, 30% dropout to keep it honest, and categorical cross-entropy as the loss function with Adam optimizer driving the updates.
The fusion weight $$\alpha$$ wasn't guessed — it was earned. We ran cross-validation across four candidates and the results were clear:
| $$\alpha$$ | Accuracy |
|---|---|
| 0.5 | 91.2% |
| 0.6 | 92.8% |
| 0.7 | 94.6% |
| 0.8 | 93.9% |
$$\alpha = 0.7$$ won. The whole system ships as a live Streamlit web app — upload an image or use the camera directly.
Stack: Python · TensorFlow · Keras · OpenCV · Streamlit · Scikit-learn
Challenges we ran into
The labeling problem — 413k images is only impressive if they're clean. Ours weren't, initially. Mislabeled batches, corrupted scans, inconsistent resolutions — we fixed them manually, one batch at a time
The 78-stroke incident — our feature extractor once reported 78 strokes in a single handwritten sentence. Real number: around 12. A single mishandled gap between characters was fragmenting every word into dozens of phantom strokes. Finding that bug took days
Anxiety meets Stress — these two conditions share so many handwriting characteristics that our early models kept swapping them. The multi-agent structure — evaluating rhythm and pressure separately rather than together — was the fix that finally worked
Trusting the DNN more — our instinct was to weight both sources equally. The data disagreed. Equal weighting at $$\alpha = 0.5$$ actually dropped accuracy. The neural network had earned more trust than the hand-engineered features
Accomplishments that we're proud of
- Pushed accuracy from an early ~70% to 93–95% through systematic architecture decisions — not luck
- Achieved F1 > 0.90 per class — every category, not just the macro average
- Built a 4-agent explainable pipeline where the reasoning behind every prediction is visible — because in mental health, "trust me" is not good enough
- Assembled and verified a 413,701-image dataset as a final year student team, with full ethical compliance from day one
- Shipped a working real-time web application that runs in under 2 seconds without any GPU requirement
What we learned
We learned that $$\alpha$$ is not a detail — it's a decision. Picking a fusion weight without testing it is just guessing with extra steps. Cross-validation turned an assumption into a fact, and that fact gave us a measurable accuracy boost.
We also learned something that surprised us: making the system explainable made it better. Forcing each agent to produce structured, interpretable output caught bugs earlier and made the whole pipeline easier to reason about.
But the lesson that stayed with us longest was simpler than any of that. When the domain involves mental health — when the wrong prediction could affect how someone perceives themselves or gets treated — you stop optimising for speed and start asking harder questions about what responsible AI actually looks like.
What's next for Handwriting Pattern Analysis for Mental Health Detection
Right now we see what handwriting looks like. We don't see how it happens — the velocity of each stroke, the pauses between words, the pressure building and releasing in real time. That temporal dimension lives in stylus data, not images.
The next version replaces static image input with .svc tablet recordings and swaps the CNN backbone for an LSTM or Vision Transformer — something that can model writing as a sequence of events rather than a frozen snapshot.
From there, we want a clinical validation study — real subjects, real psychologists, direct comparison against DASS-21 gold-standard assessments. That's the step that turns a prototype into something a counselor can actually trust.
And the end goal — the one that started this whole thing — is a mobile app. Open it. Write a sentence. Get a quiet signal that says: things might be harder than usual right now. Maybe talk to someone.
No forms. No appointments. No stigma. Just a sentence, and a system that actually listens.

Log in or sign up for Devpost to join the conversation.