-
-

-
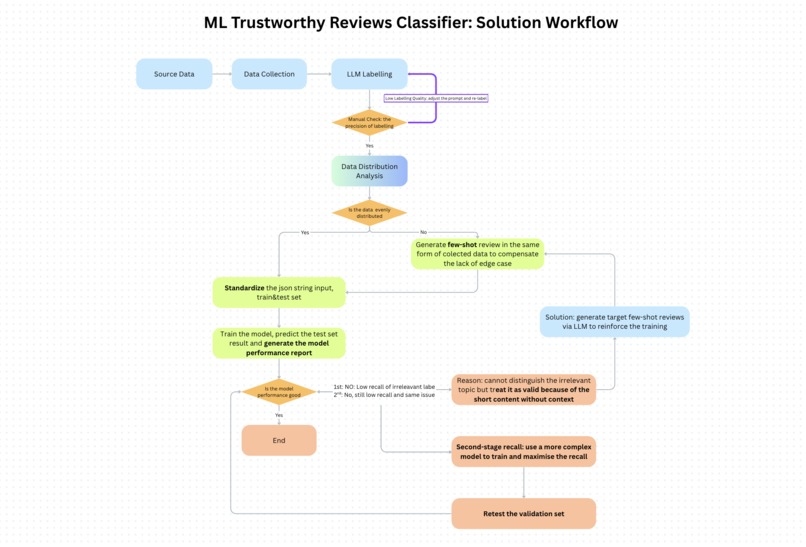
Workflow


Ads ML Classifier with LLM - Tiktok TechJam 2025
Inspiration
Online platforms such as Google Maps or TikTok often face the challenge of low-quality, irrelevant, or promotional reviews that degrade user trust. Manual moderation is time-consuming and error-prone, while traditional classifiers struggle with short, vague, or minority-class reviews (e.g., advertisements or hearsay-based rants).
We wanted to design a solution that leverages the power of Large Language Models (LLMs) to assist moderation, reduce human workload, and build a cleaner ecosystem for user feedback.
What it does
Our solution is an AI-powered Ads ML Classifier that categorizes reviews into four classes:
- Valid – genuine user experience
- Advertisement – promotional content with links or marketing keywords
- Irrelevant – off-topic or unrelated comments
- Rant_Without_Visit – negative complaints without evidence of visiting the location
The system combines LLM-driven labeling with fine-tuned transformer models to achieve both scalability and high accuracy. It also integrates metadata context (business name, category, description) to disambiguate short or vague reviews.
How we built it
- Data Collection: We sampled reviews from Google Local Review dataset (UCSD) and Kaggle. To address extreme class imbalance, we generated synthetic data with LLMs (Claude Sonnet-4) for Advertisement and Rant_Without_Visit categories, and later added 200 short-text Irrelevant samples.
- Prompt Design: Crafted a structured prompt with clear role definition, label policies, and few-shot examples to guide LLM labeling consistently.
- Model Development:
- Baseline model:
nlptown/bert-base-multilingual-uncased-sentimentfine-tuned with Hugging Face Trainer. - Introduced two-stage recall strategy: second-stage model prioritizes recall to minimize overlooked negative samples.
- Incorporated metadata (category, description, name) as contextual input to improve classification of short reviews.
- Baseline model:
- Libraries & Frameworks: Pandas, scikit-learn, NumPy, PyTorch, Hugging Face Transformers/Datasets, Google Colab.
Challenges we ran into
- Data imbalance: 97% of reviews were Valid, while Advertisement and Rant_Without_Visit accounted for less than 1%.
- Short reviews: One-word or vague comments like “nice” or “bad” lacked context, making them hard to classify.
- Model trade-offs: Improving recall for minority classes often reduced precision.
- Resource constraints: Training advanced models on limited Colab GPU required efficiency-focused choices like DistilBERT.
Accomplishments that we're proud of
- Achieved overall high accuracy** and strong precision across classes.
- Successfully integrated LLM-based labeling with transformer fine-tuning, implementing the second-stage modelling strategy and creating a scalable annotation pipeline.
- Designed a two-stage recall strategy that explicitly targets false negatives.
- Extended context by embedding business metadata, improving classification of ambiguous short reviews.
What we learned
- The importance of prompt engineering in obtaining high-quality LLM annotations.
- How to balance precision vs. recall in multi-class classification with imbalanced data.
- That context (metadata + review text) is crucial for reliable classification, especially for short and vague samples.
- Synthetic data generation, when carefully controlled, can significantly boost minority-class performance.
What's next
- Introduce quality score: Add a quality rating variable during LLM labeling so that low-quality reviews (short, vague) can be systematically flagged as Irrelevant.
- Model improvements: Experiment with larger backbones (RoBERTa, DeBERTa) and ensemble approaches.
- Deployment optimization: Use model distillation and quantization to enable scalable real-time moderation.
- Continuous monitoring: Implement error analysis pipelines and distribution-shift detection to maintain robustness in production.









Log in or sign up for Devpost to join the conversation.