Inspiration
The inspiration came from real-world ad recommendation systems like AppLovin’s Axon, which rely on large datasets of ad creatives to predict performance. We wanted to explore how far we could push multimodal intelligence by building a system that understands ad content visually, textually, and acoustically. Our goal was to make ad data more insightful and useful for smarter recommendation models.
What it does
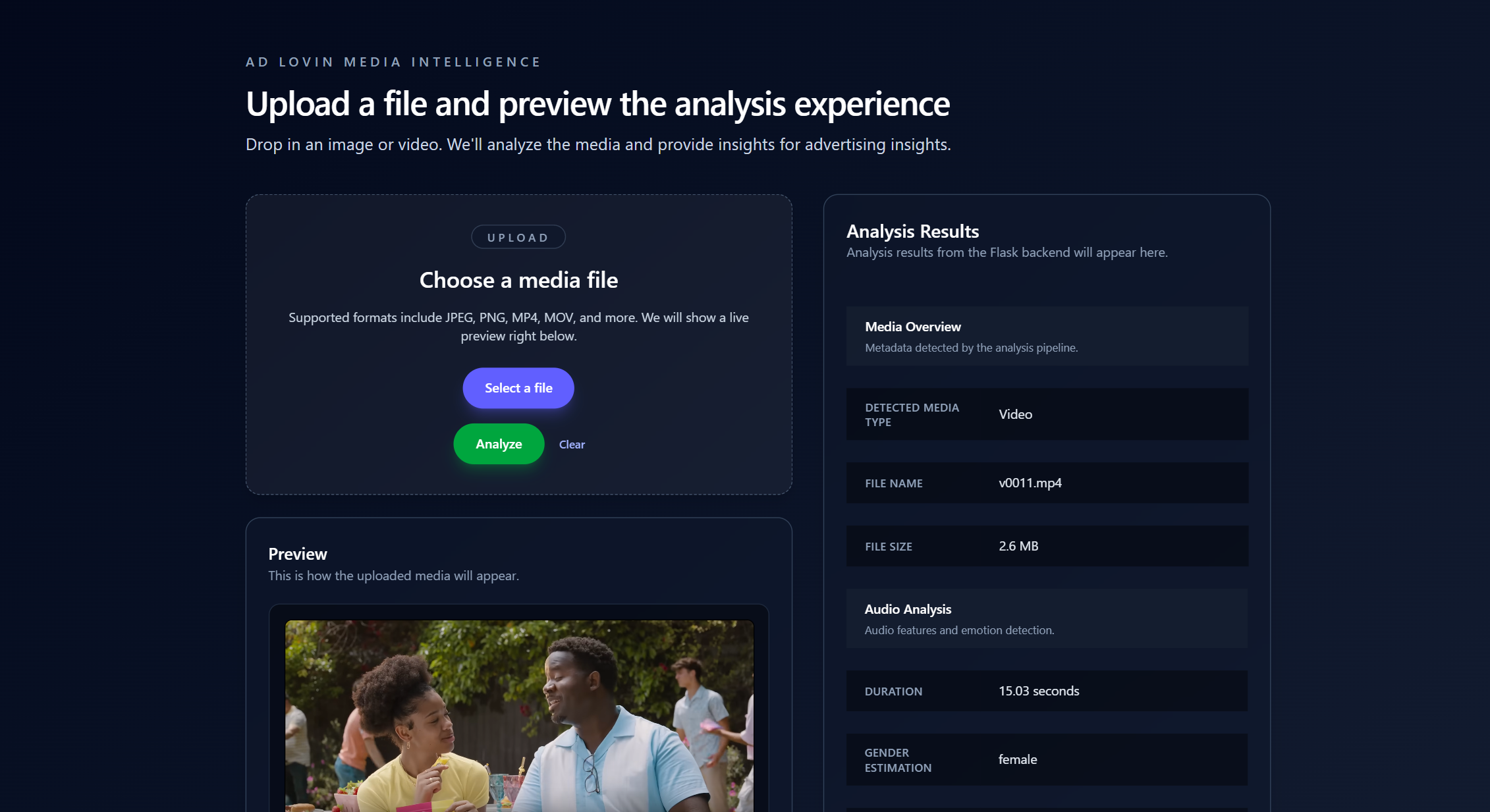
ADLOVIN Media Intelligence processes ad creatives, both images and videos, and extracts high-value multimodal features such as visual composition, text sentiment, and audio mood. These embeddings can then be used to generate creative performance insights or power downstream machine learning models for recommendation and ranking.
How we built it
We built a modular feature extraction pipeline in Python. For video ads, we used FFmpeg to extract keyframes and Librosa for audio signal analysis. Each frame was embedded using a pretrained vision transformer, and text elements were captured through EasyOCR and language models. We used ChromaDB to store and query embeddings at scale, and FastAPI to provide an interface for experimentation and testing.
Challenges we ran into
One major challenge was optimizing feature extraction for large videos while maintaining temporal coherence between visual and audio signals. Another was ensuring meaningful clustering in the vector database without redundant representations, especially after removing the deduplication algorithm. Balancing efficiency and fidelity across multiple modalities required careful design and parameter tuning. One of the major issues faced was the wifi. It made our life really hard. We had to find place to work outside of the venue.
Accomplishments that we're proud of
We successfully built an end-to-end multimodal intelligence pipeline that can process a wide range of ad creatives and output interpretable embeddings. The system achieved reliable text and sentiment extraction from frames and robust feature representation using transformer-based models.
What we learned
We learned how to align multimodal embeddings for recommendation tasks, fine-tune vector similarity searches for creative clustering, and manage large-scale ad processing efficiently. We also gained experience combining computer vision, audio analysis, and natural language understanding into one cohesive system.
What's next for ADLOVIN Media Intelligence
Next, we plan to add a lightweight deduplication model, connect the embeddings to a performance dataset for supervised learning, and build an interactive dashboard to visualize ad intelligence insights in real time. We also aim to explore generative tools that can use embeddings to suggest creative improvements.
Built With
- chromadb
- claude
- clip
- easyocr
- hugging-face
- numpy
- python
- react
- scikit-learn
- tailwind
- typescript


Log in or sign up for Devpost to join the conversation.