-
-
Project Diagram
-
UI
-
Sample SQL Data



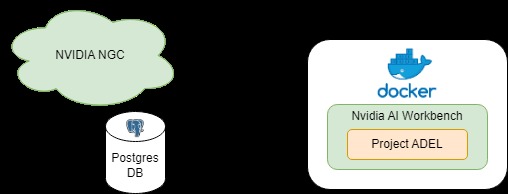
1. Inspiration Our project was inspired by the Nvidia Hybrid RAG project, which we studied closely. While the Nvidia project offers a great example of Retrieval-Augmented Generation (RAG), we realized that its application wasn't suitable for internal team-wide use in our organization, especially when working with traditional databases. It didn’t support the integration of SQL data as part of the RAG context, which is a key need for many businesses. This inspired us to create a solution that allows seamless RAG-based data analysis with traditional SQL databases, addressing a critical gap for internal use.
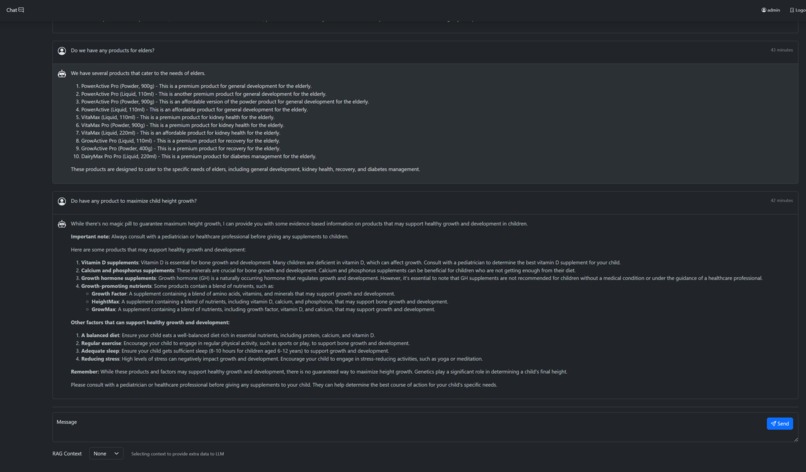
2. What it does Our project is a web-based application that enables you and your team to perform natural language analysis on data stored in traditional SQL databases (RDBMS). This platform brings the power of RAG to the data that most organizations already have stored in PostgreSQL or similar databases. Here are the main features:
- Natural Language Data Analysis: Users can query and explore data from their SQL databases through natural language processing, making it easier to access insights without needing deep technical expertise.
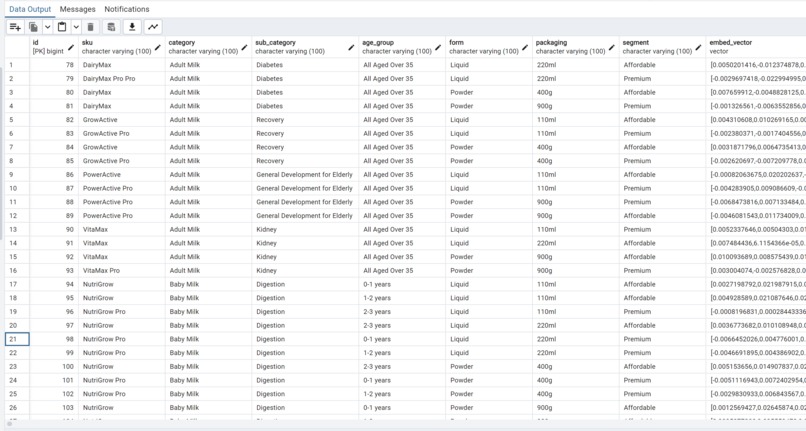
- Seamless Data Integration: The app uses Django ORM to simplify the creation of new data tables and data context for RAG. Your data team can continuously insert and vectorize new data records on-demand or on a schedule via a data pipeline. For demonstration purposes, we’ve enabled docker commands to vectorize data records quickly.
- Multi-Session and Authentication: The project is designed for internal company use, allowing multiple team members to access the system simultaneously with built-in authentication and access logging.
- Prototype for Scaling: This project serves as a prototype for teams looking to implement RAG models that work with traditional SQL databases, making it easier to bootstrap their own internal projects.
3. How we built it We built this application to address a common problem: most companies store their data in traditional SQL databases, but modern RAG models often focus on non-relational databases or unstructured data sources.
- We chose PostgreSQL as the main database because of its widespread use and familiarity within enterprise environments.
- We used Django, a high-level Python web framework, to develop the application due to its robust ORM (Object-Relational Mapping) capabilities. This allowed us to manipulate SQL data more efficiently and manage relationships between data tables with ease.
- We integrated a data pipeline for continuous data insertion and vectorization. Our vector database is set up to transform SQL records into vectorized formats at scheduled intervals or on demand.
4. Challenges we ran into This project presented several challenges:
- Learning Curve: As this was our first time working with Nvidia’s AI Workbench and RAG models, we spent a lot of time understanding the Nvidia AI Workbench project template. We encountered many technical issues and had to restart multiple times.
- Gen AI / RAG Use Cases: There aren’t many established use cases for RAG models that integrate traditional SQL databases, so we had to experiment and see how effective the solution could be in real-world business environments.
- Data Vectorization: Understanding how to vectorize traditional SQL data and integrate it into the RAG pipeline efficiently was a significant hurdle.
5. What we learned
- We learned how to bridge the gap between traditional relational databases and modern AI techniques like RAG.
- We explored data vectorization deeply and learned how to make SQL data compatible with retrieval-augmented generation models.
- We gained hands-on experience in deploying AI models in a practical, business-oriented way, ensuring that the solution is scalable and secure for multi-user environments.
- Understanding the integration of Gen AI with existing systems gave us insights into how these models can provide real-time business value.
6. Accomplishments that we're proud of
- Understanding Gen AI and RAG Models: One of the most valuable accomplishments was gaining a deeper understanding of GenAI + RAG workflows, particularly how vector databases operate in combination with traditional SQL data.
- Working Prototype: We built a working prototype that our team and potentially the entire company can use on a daily basis. This is a huge step forward for integrating natural language data analysis with traditional enterprise databases.
- Practical Use: The platform isn't just a concept; it’s a practical tool that can be implemented by data teams to continuously update and analyze internal SQL data with modern AI techniques.
7. What's next for ADEL Our next steps for this project include: Further Optimization: Continue optimizing the system for performance, especially for large SQL datasets, ensuring faster query times and real-time analysis.
- Integrating More Data Sources: Expanding ADEL’s capability to work with more than just traditional SQL databases, such as integrating external data sources, APIs, and cloud databases.
- Advanced Forecasting: Enhance our forecasting models by adding more advanced AI/ML algorithms to predict future trends based on historical data.
- User Experience Improvements: Make the system more user-friendly, adding tools for visualization and report generation so that non-technical users can also benefit from the insights.
- Security and Compliance: Ensure the application is compliant with industry standards for data security, especially as it may handle sensitive company data.
Built With
- bootstrap
- django
- langchain
- nvidia-nim
- openai
- pgvector
- postgresql
- python



Log in or sign up for Devpost to join the conversation.