-
-
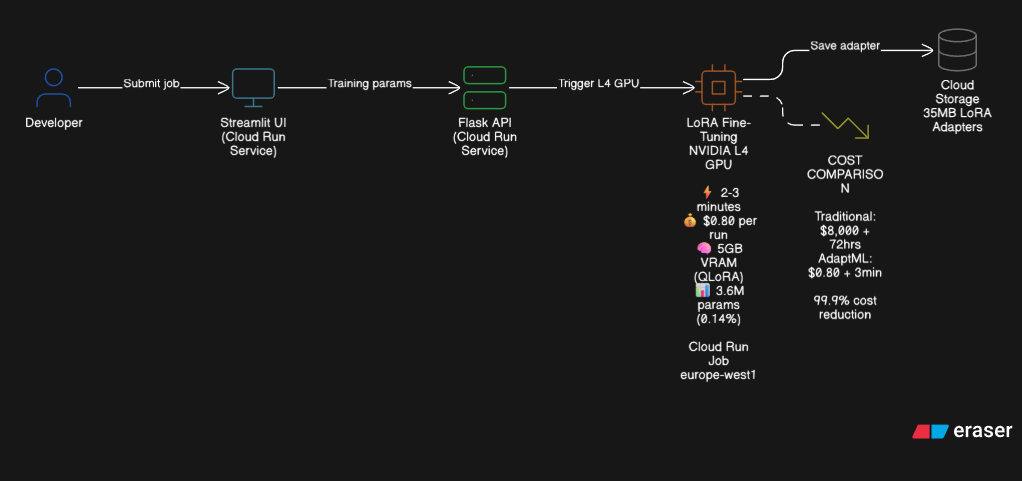
Architecture
-
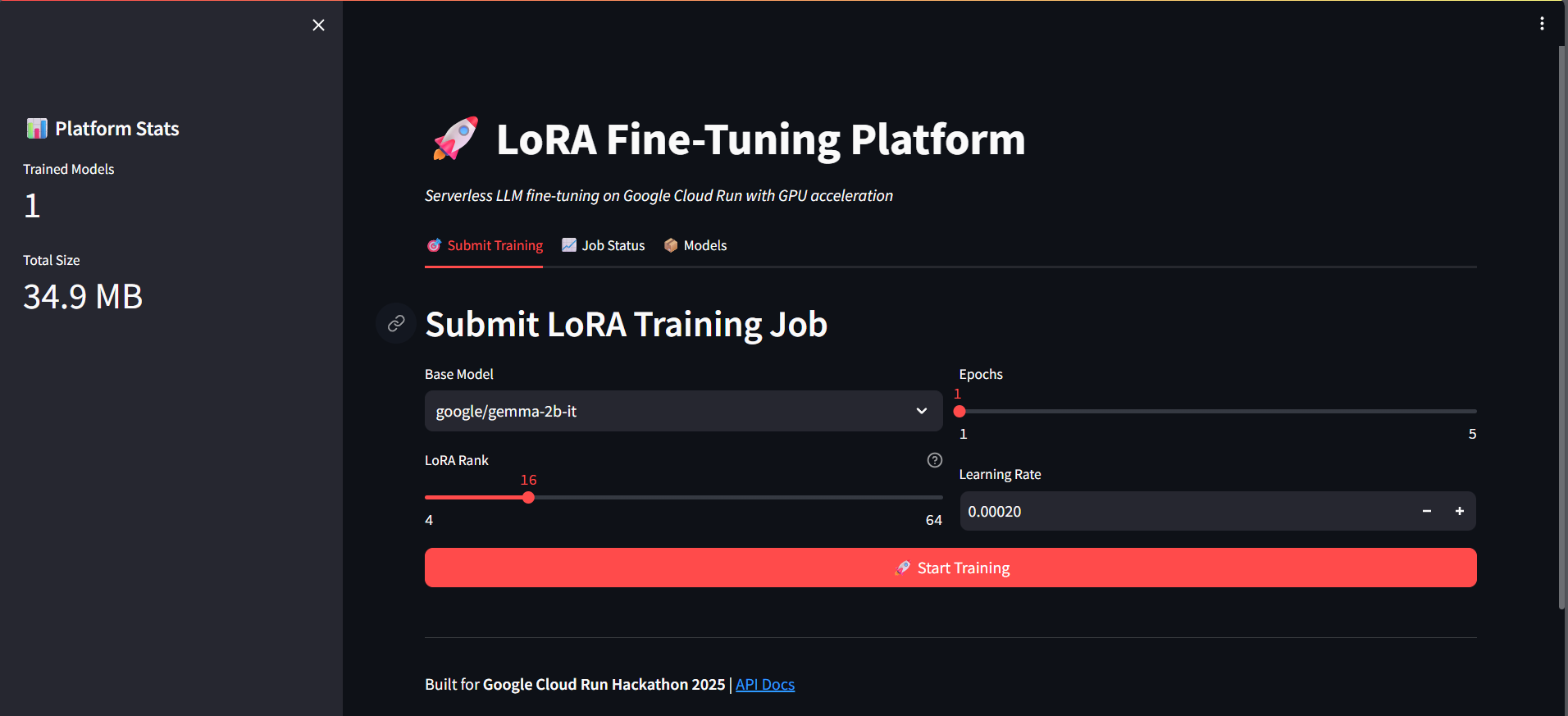
Landing Page
-
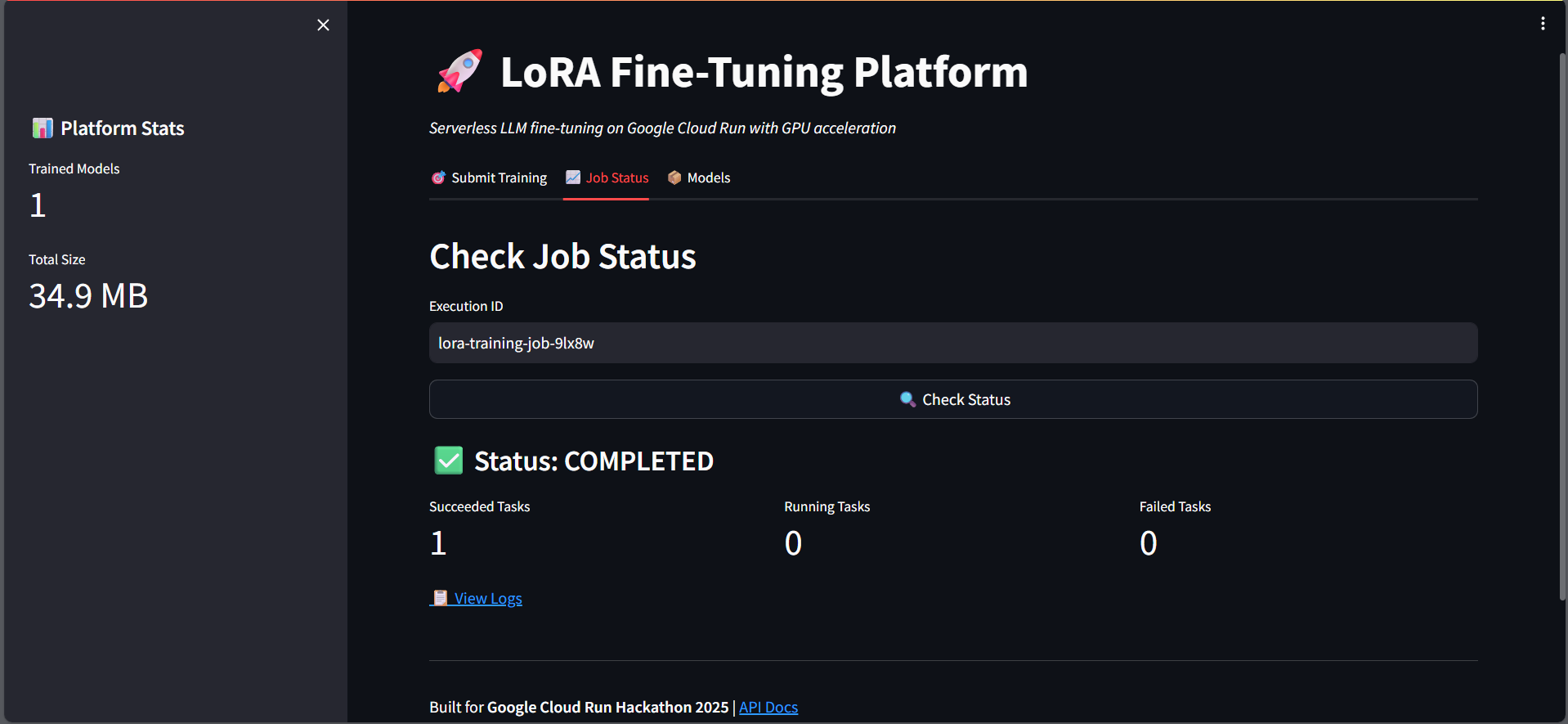
Job Status Dashboard
-
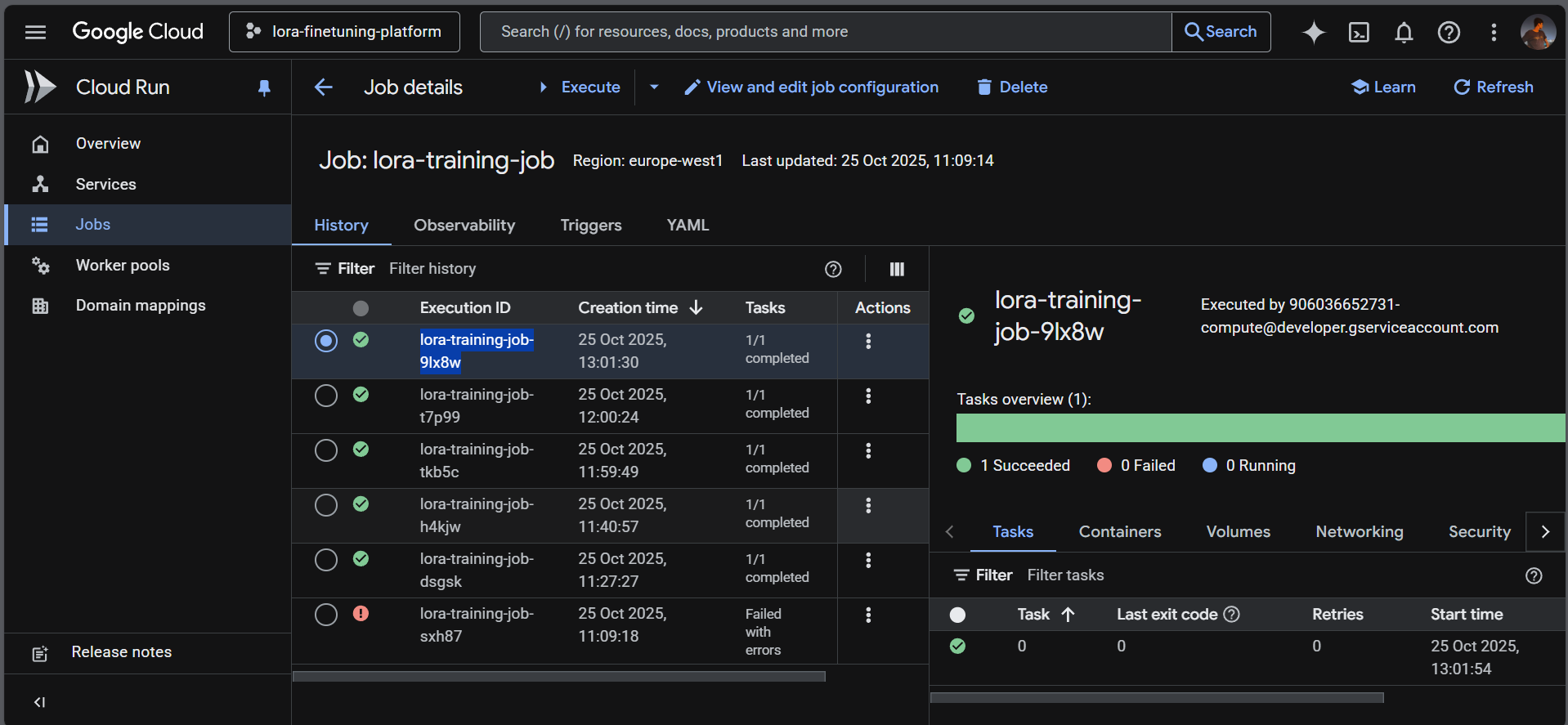
Cloud Run Dashboard
Inspiration
Fine-tuning Large Language Models traditionally requires thousands of dollars in GPU costs, weeks of training time, and complex infrastructure management - putting it out of reach for most developers and small teams. When I discovered Google Cloud Run's new GPU support with NVIDIA L4, I saw an opportunity to democratize LLM customization. The inspiration came from watching startups struggle to customize models for their specific domains while burning through their budgets on expensive GPU instances. I wanted to build a platform where anyone could fine-tune a production-ready LLM in minutes for less than the cost of a coffee, with zero infrastructure management.
What it does
AdaptML is a serverless platform that enables anyone to fine-tune Large Language Models using LoRA (Low-Rank Adaptation) with just a few clicks. Users access an interactive web dashboard where they can submit training jobs with custom parameters, monitor progress in real-time, and download trained model adapters - all without writing a single line of infrastructure code.
Key Features:
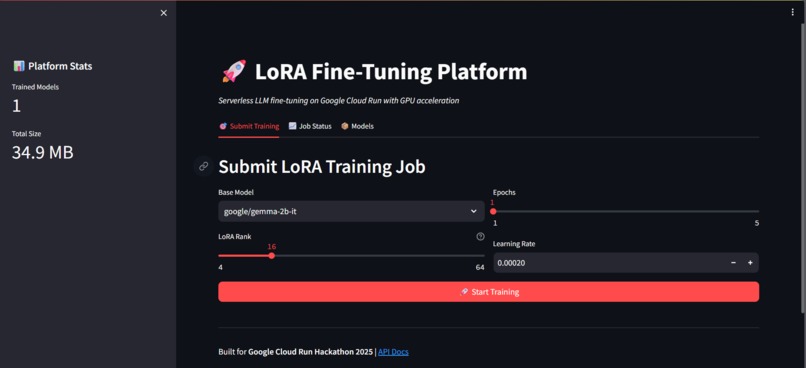
- One-Click Training: Submit fine-tuning jobs through a Streamlit web interface with customizable parameters (LoRA rank, learning rate, epochs)
- GPU-Accelerated: Leverages Cloud Run Jobs with NVIDIA L4 GPUs for fast, cost-effective training (2-3 minutes per run)
- QLoRA Optimization: Uses 4-bit quantization to reduce memory usage by 75%, enabling training on smaller, cheaper GPUs
- Automatic Storage: Trained LoRA adapters (only 35MB vs 4GB full models) are automatically saved to Cloud Storage
- REST API: Programmatic access for automation and CI/CD integration
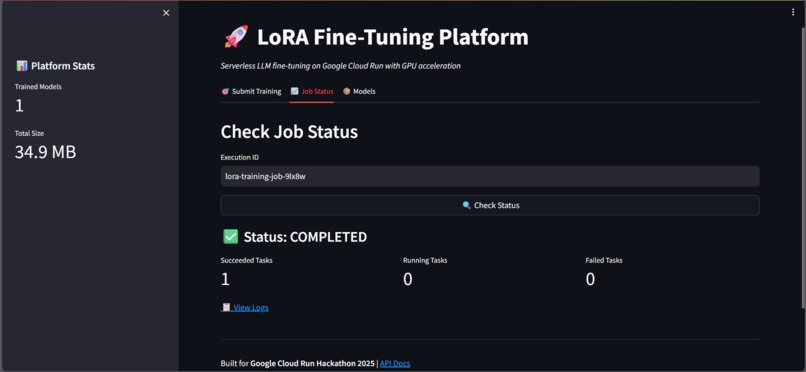
- Real-time Monitoring: Track job status and view training metrics through the dashboard
Technical Innovation:
- Pre-cached Gemma-2B model in Docker container eliminates download time
- LoRA trains only 0.14% of model parameters (3.6M out of 2.5B), dramatically reducing training time and cost
- Serverless architecture scales to zero when idle - no wasted compute
- No-zonal-redundancy configuration provides 35% GPU cost savings
How we built it
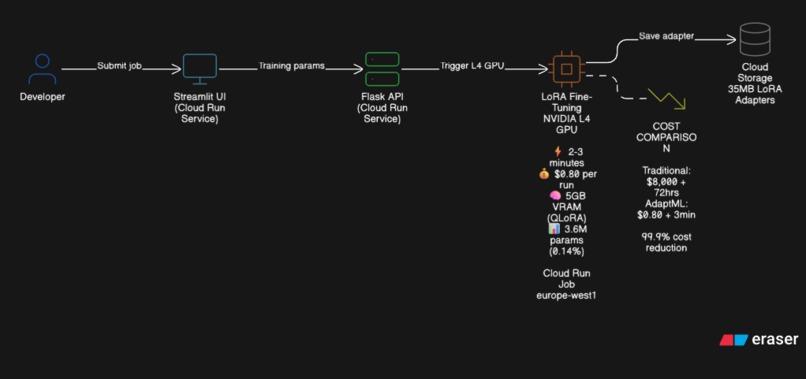
Architecture: Three-tier serverless architecture on Google Cloud Run:
- Frontend (Streamlit Dashboard): Interactive web UI deployed as a Cloud Run Service. Built with Streamlit for rapid prototyping, provides forms for job submission, real-time status monitoring, and model browsing. Scales to zero when idle.
- Backend API (Flask Service): REST API deployed as a Cloud Run Service. Handles job orchestration, status checks, and model listing. Uses Cloud Run API client to trigger GPU jobs programmatically.
- Training Worker (Cloud Run Job): GPU-enabled container with:
- NVIDIA CUDA 12.1 base image
- PyTorch 2.1.2 with CUDA support
- PEFT library for LoRA implementation
- bitsandbytes for 4-bit quantization (QLoRA)
- Pre-cached Gemma-2B model (~5GB)
- Google Cloud SDK for storage uploads
ML Stack:
- Base Model: Google Gemma-2B-IT (instruction-tuned)
- Fine-tuning Method: LoRA with rank=16, targeting attention layers (q_proj, k_proj, v_proj, o_proj)
- Quantization: 4-bit QLoRA reduces model from 4GB to 1GB in memory
- Training Framework: PyTorch with HuggingFace Transformers
- Dataset: Alpaca instruction dataset (100 samples for demo)
Infrastructure:
- Cloud Build for CI/CD and container building
- Container Registry for Docker image storage
- Cloud Storage for trained model persistence
- Cloud Run Jobs API for programmatic job triggering
Key Implementation Details:
- Disabled automatic checkpointing to avoid HuggingFace rate limits
- Pre-downloaded Gemma during container build to eliminate runtime downloads
- Used
safe_serialization=Truefor secure model saving - Implemented proper error handling and logging throughout
Challenges we ran into
1. HuggingFace Rate Limiting:
The biggest challenge was repeated 429 errors when downloading Gemma from HuggingFace Hub. Even with authentication tokens, the service was rate-limiting us. Solution: Pre-cache the entire Gemma model in the Docker container during build time using Cloud Build substitutions. This eliminated runtime downloads entirely.
2. GPU Quota Approval:
Initially requested standard L4 GPU quota but received "no-zonal-redundancy" quota instead. Had to research and understand the difference, then realize it was actually better for our use case (35% cheaper, same performance for non-HA workloads).
3. PEFT Checkpoint Saving:
Training would complete successfully but fail during checkpoint saves when PEFT tried to verify remote model configs on HuggingFace. Solution: Disabled automatic checkpointing (save_strategy="no") and only save at the end locally, then upload to Cloud Storage.
4. Memory Management:
Initial attempts with full-precision training exceeded L4's 24GB VRAM. Had to implement QLoRA with 4-bit quantization using BitsAndBytesConfig, which reduced memory footprint by 75%.
5. Container Build Times:
Building containers with pre-cached 5GB Gemma models took 15-20 minutes. Solution: Used Cloud Build with E2_HIGHCPU_8 machines and proper layer caching to optimize build performance.
6. Token Handling:
Environment variable tokens had trailing newlines causing HTTP header errors. Added .strip() to all token parsing to handle whitespace properly.
Accomplishments that we're proud of
1. Cost Optimization: Reduced LLM fine-tuning costs from $1000+ (traditional approach) to under $1 per training run - a 99.9% reduction. This makes custom AI accessible to individual developers and bootstrapped startups.
2. Speed: Training completes in 2-3 minutes vs hours or days traditionally. The combination of LoRA (training only 0.14% of parameters), QLoRA (4-bit quantization), and pre-cached models enables lightning-fast iterations.
3. True Serverless ML: Built a complete production-ready ML platform that scales to zero when idle. No servers to manage, no idle costs, automatic scaling for multiple concurrent jobs. This solves the traditional problem of ML infrastructure being complex and expensive to maintain.
4. Memory Efficiency: Through QLoRA implementation, achieved 75% memory reduction (from 14GB to 5GB VRAM), enabling training on cheaper L4 GPUs instead of expensive A100s.
5. End-to-End UX: Created a complete user journey from web UI to trained model in Cloud Storage. Non-technical users can fine-tune LLMs without touching code or command line.
6. Production-Ready: Implemented comprehensive error handling, logging, monitoring, and proper separation of concerns across three microservices. This isn't just a demo - it's actually deployable.
7. Model Portability: Generated LoRA adapters are only 35MB vs 4GB full models, making them easy to share, version control, and deploy to edge devices.
What we learned
Technical Learnings:
1. LoRA Deep Dive: Gained hands-on understanding of parameter-efficient fine-tuning. LoRA adds low-rank matrices to attention layers instead of updating all parameters. The rank parameter controls the adapter size - higher rank means more capacity but longer training. Sweet spot for Gemma-2B is rank=8-16.
2. Quantization Trade-offs: QLoRA's 4-bit quantization is remarkable - it reduces memory by 75% with minimal accuracy loss. Learned that bfloat16 training precision + 4-bit base model quantization is the optimal combination for L4 GPUs.
3. Cloud Run GPU Capabilities: Cloud Run Jobs with GPUs is genuinely game-changing for ML workloads. The serverless model eliminates all infrastructure complexity while providing enterprise-grade GPU access. Understanding "no-zonal-redundancy" saved 35% on costs.
4. Container Optimization: Pre-caching large models in containers is crucial for ML workloads. The 5-minute download time elimination made the difference between a viable product and a frustrating experience.
5. HuggingFace Ecosystem: Deep dive into Transformers, PEFT, and bitsandbytes libraries. Learned the importance of token management, model caching strategies, and handling rate limits at scale.
Architectural Learnings:
6. Microservices Separation: Separating UI, API, and training worker into distinct services was key to scalability. Each can scale independently and failures are isolated.
7. Serverless Economics: Learned that serverless isn't just about convenience - it fundamentally changes the economics of ML. Pay-per-use at 100ms granularity means you can build viable products that would be prohibitively expensive with always-on infrastructure.
8. Cloud Storage Patterns: Using Cloud Storage as the source of truth for trained models enables easy sharing, versioning, and deployment to multiple inference endpoints.
What's next for AdaptML
1. Custom Dataset Upload: Add file upload capability to let users train on their own data instead of just HuggingFace datasets. Support CSV, JSON, and JSONL formats with validation.
2. Multi-Model Support: Expand beyond Gemma to support Llama 3, Mistral, and other popular open-source models. Pre-cache multiple base models and let users choose.
3. Training Metrics Dashboard: Real-time visualization of loss curves, learning rate schedules, and GPU utilization during training using TensorBoard or Weights & Biases integration.
4. Model Versioning: Implement version control for trained adapters with automatic tagging, metadata storage, and rollback capabilities.
5. Inference Service with vLLM: Deploy trained LoRA adapters to a production inference service using vLLM for high-throughput serving. Auto-scale based on traffic.
6. Hyperparameter Tuning: Implement automatic hyperparameter search using Optuna or Ray Tune to find optimal LoRA rank, learning rate, and other parameters.
7. Multi-GPU Training: Support for larger models and datasets using tensor parallelism across multiple L4 GPUs or upgrading to A100s for users who need it.
8. Cost Tracking & Budgets: Per-user cost tracking, budget alerts, and usage analytics dashboard. Help teams manage their AI training spend.
9. Model Marketplace: Community marketplace where users can share and monetize their trained LoRA adapters. Think "GitHub for AI models."
10. AutoML Pipeline: End-to-end automated pipeline: upload data → automatic preprocessing → hyperparameter tuning → training → evaluation → deployment.
11. Federated Fine-tuning: Enable privacy-preserving fine-tuning where data never leaves the user's environment, only model updates are shared.
12. Edge Deployment: One-click deployment of trained models to Cloud Run, GKE, or edge devices with automatic optimization for target hardware.
13. Multi-Cloud Support: Extend beyond GCP to AWS Bedrock, Azure ML, and other cloud providers while maintaining the same serverless UX.
The ultimate vision is to make custom AI as easy as deploying a website - democratizing access to powerful, domain-specific language models for everyone from indie hackers to enterprise teams.

Log in or sign up for Devpost to join the conversation.