Inspiration
I am an AI research engineer working on AI safety and white-box uncertainty. ActMap Voice applies my ActMap research to the ElevenLabs voice-agent pipeline.
The core problem is cost and latency in voice agents. Verifying every user turn with RAG, tools, or external calls is expensive and slow. Answering everything directly is cheaper, but increases the risk of hallucinations or unsafe responses. ActMap Voice helps ElevenLabs agents choose the cheaper, faster, and safer route before the agent speaks.
What it does
ActMap Voice is a pre-speech routing layer for ElevenLabs agents. After speech-to-text, it decides whether the workflow should:
ANSWERdirectly from the modelVERIFYwith RAG, tools, or account dataESCALATEto a human
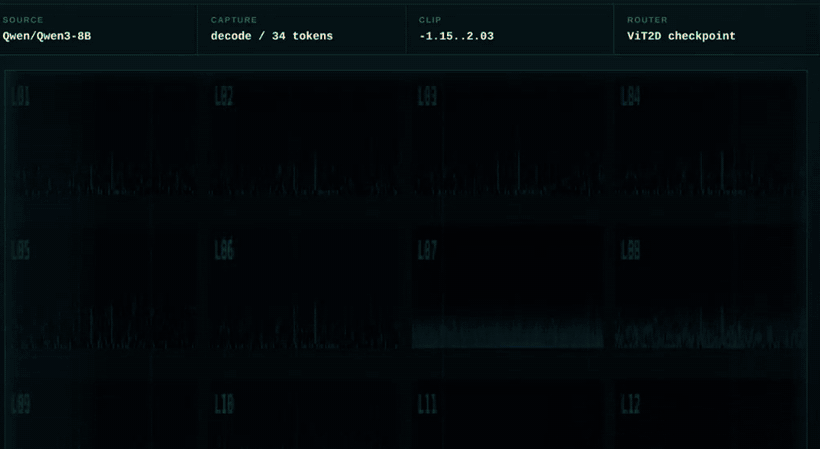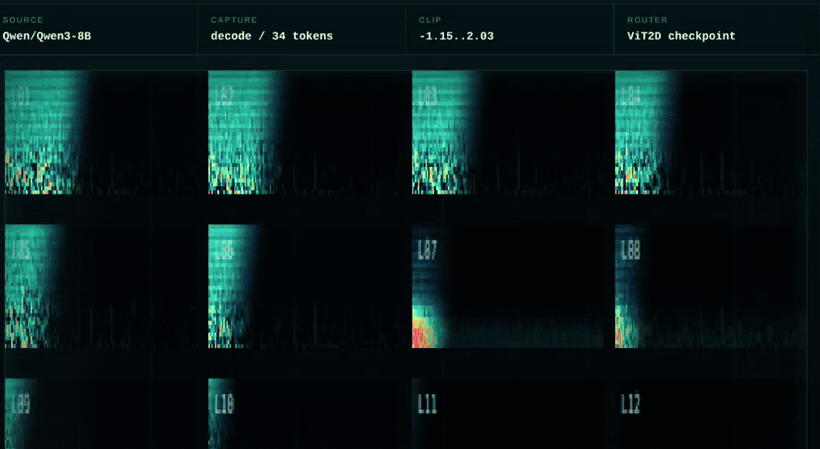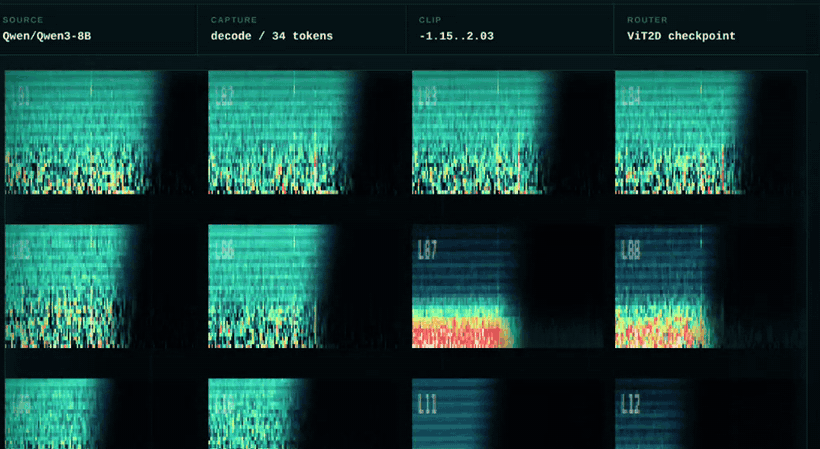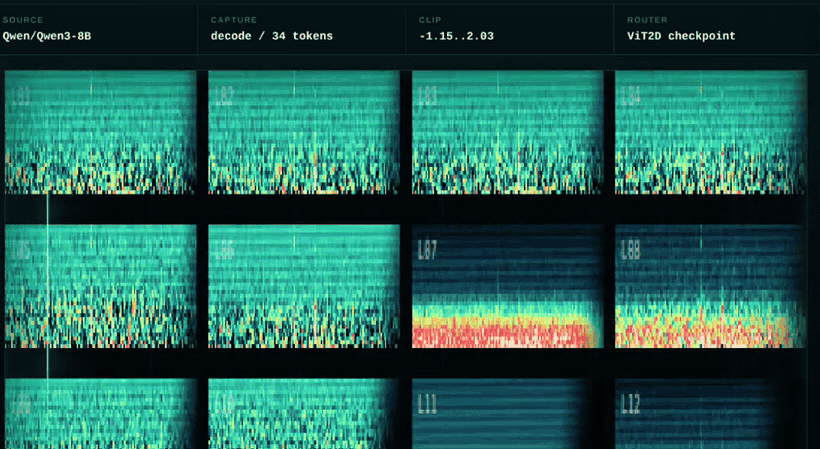
Instead of routing only from transcript text, ActMap Voice uses hidden activations from the reasoning LLM. These activations are converted into a 12 x 32 x 128 activation map and classified with a small vision transformer.
This helps reduce unnecessary retrieval/tool calls, lower inference cost, reduce latency, and avoid bad spoken answers.
How I built it
ElevenLabs provides the voice layer: speech-to-text, agent workflow, and text-to-speech. ActMap runs as an external routing backend after transcription and before the agent speaks.
The demo exposes an OpenAI-compatible Custom LLM endpoint and a /route server-tool endpoint, so ElevenLabs agents can call ActMap before deciding whether to answer, verify, or escalate.
I generated ActMaps from a fixed local Qwen model, trained a vision router over the activation maps, and benchmarked it against a text-only LM router on the same routing task. The final demo replays a benchmark case where the text-only router chooses VERIFY, while ActMap correctly chooses ESCALATE with confidence 0.9916.
Challenges I ran into
The hardest part was making the cost-saving idea concrete. The project is not just “safer voice AI”; it is better routing for expensive voice-agent workflows.
Always using RAG and tools wastes money. Always answering from memory creates risk. The challenge was showing that ActMap can separate cheap direct-answer turns from turns that actually need verification or escalation.
Accomplishments that I'm proud of
On the pilot benchmark, ActMap + ViT reached 96.18% accuracy and 0.9619 macro F1, compared with 91.01% accuracy and 0.9110 macro F1 for a text-only LM router.
The final routing step is also about 4.5x faster once ActMaps exist: 390.7 rows/s versus 86.4 rows/s.
At scale, this matters. In a 10M voice-turns-per-day scenario, better routing can mean hundreds of thousands more correct route decisions per day and millions of dollars per year in avoided unnecessary RAG/tool calls.
What I learned
The key insight is that voice-agent cost is a routing problem. The cheapest path is not always safe, and the safest path is not always necessary.
ActMaps provide a second signal beyond transcript text: how the model internally processes the request. That signal can help ElevenLabs workflows avoid unnecessary expensive calls while still escalating risky cases before anything is spoken.
What's next for ActMap Voice
Next, I want to integrate ActMap Voice more deeply into live ElevenLabs workflows, optimize ActMap extraction latency, and test it across larger real-world support datasets.
The long-term goal is to help voice-agent platforms route more intelligently: fewer unnecessary RAG calls, faster responses, lower operating cost, and safer handoffs when the user request is high risk.
Built With
- codex
- elevenlabs
- fastapi
- python
- torch
- voice-ai

Log in or sign up for Devpost to join the conversation.