







Inspiration
The right to peaceful protest is a cornerstone of democracies all over the world, and with rising levels of surveillance, the stakes for protesting have never been higher. Activists are protesting and amplifying their voices on social media platforms. Maintaining anonymity while protesting helps minimize the risk of retribution against those that protest and their loved ones. With more and more of our lives intertwined in the digital environment, it is important to protect the privacy of those who are voluntarily or involuntarily on these platforms.
What it does
Actiblur protects the anonymity of users in order for them to show solidarity and stand up for what they believe in at protests. Actiblur uses revolutionary face blurring technology to selectively blur faces, allowing users to choose between blurring all faces, all faces but theirs, up to as many users as they would like.
The mobile app can selectively blur faces on both live streams and on recordings. Actiblur also includes closed captions for accessibility, as blurred faces act as a barrier for those who have hard of hearing. Users are also able to view live streams on a web app, based on their geolocation and see streams near them. Actiblur also detects if set keywords are spoken to contact the emergency services using Twilio.
Our platform is not about replacing social media, but developing the technical features of face recognition and blurring, in order to supplement the digital experience. Actiblur provides privacy infrastructure as a service, allowing people to put their voices online and stand up for what they believe in.
How we built it
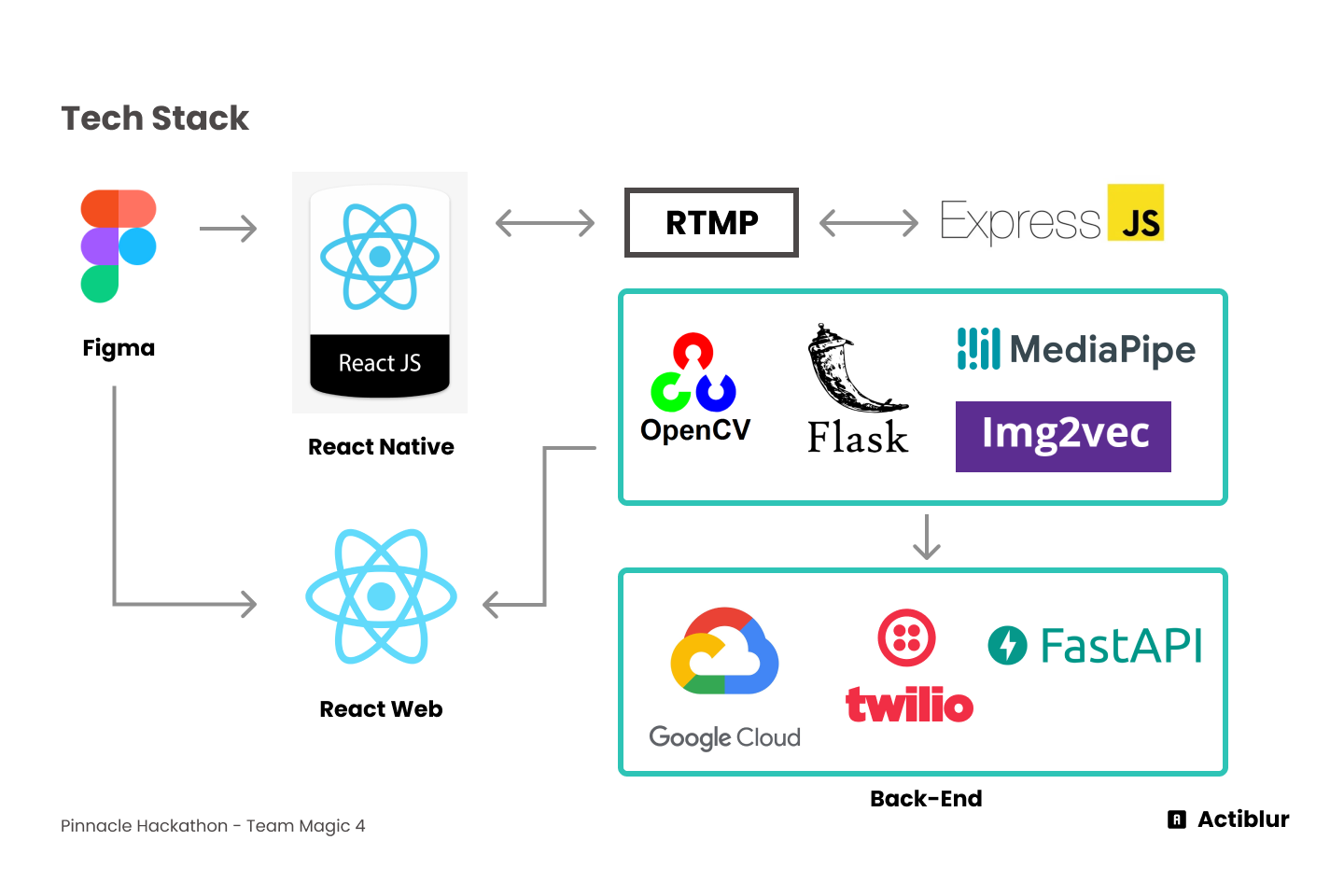
Our mobile app is powered with React Native, it creates a RTMP url which is then served using an Express node. We capture the RTMP url using OpenCV in the backend and grab frame by frame to perform facial recognition and anonymise the set faces. Faces are detected using Mediapipe for fast performance and facial recognition is performed on the faces extracted using the bounding boxes coordinates and cosine similarity with scikit-learn is performed on face embeddings. The embeddings are generated using img2vec which offers pre-trained models, we use AlexNet as a good model which offers a good speed/accuracy compromise. An http stream served with Flask and embedded into our web application written in React.
We also have a backend which allows to create closed captions for live stream, we use Google Cloud speech to text to generate the captions and we implement a safety system which detects a specific keyword to call emergency services, to achieve this we use Google Cloud speech to text to detect the set keywords and Twilio to contact the emergency services.
Challenges we ran into
While our face blurring is performed in the backend and not on device, we still had issues to ensure good performance when generating face embeddings live. We had to explore options such as multi-threading, interpolation and benchmark various pre-trained models to finally find a good middle ground to achieve satisfying performance.
one of our teammate’s laptop had a meltdown and died mid-hackathon. RIP Macbook Pro 2013
Built With
- express.js
- fastapi
- figma
- flask
- google-cloud
- img2vec
- mediapipe
- opencv
- react
- react-native
- rtmp
- twilio







Log in or sign up for Devpost to join the conversation.