-
-
-
-
Architecture
-
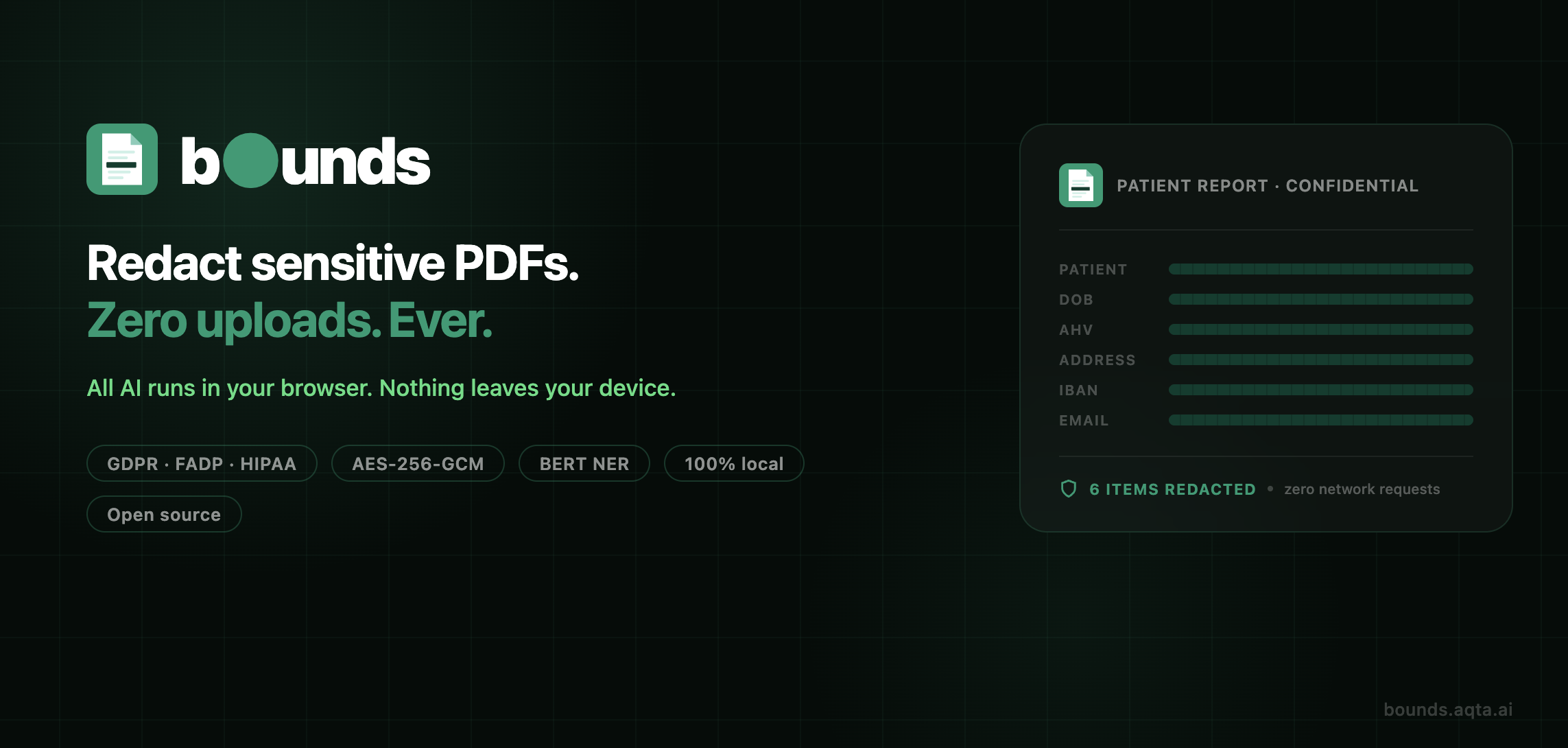
Banner
-
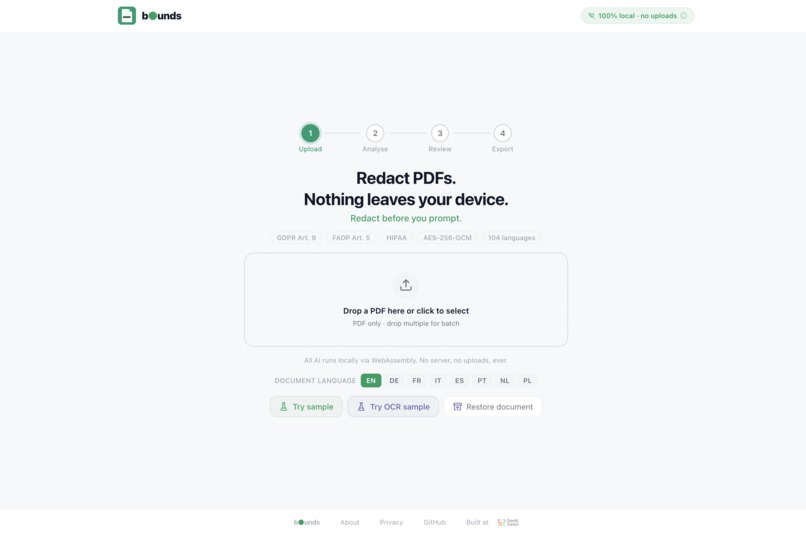
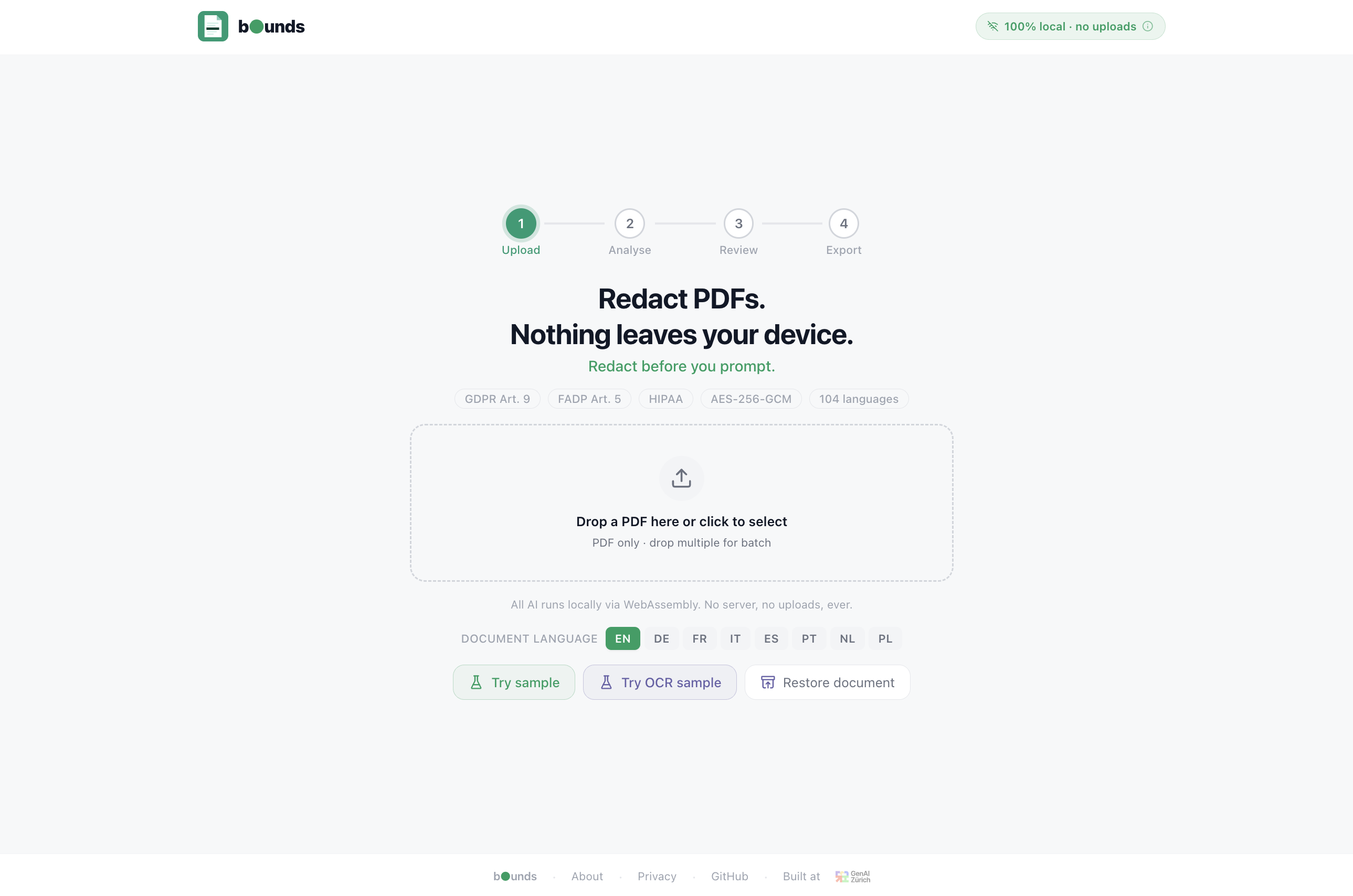
Homepage
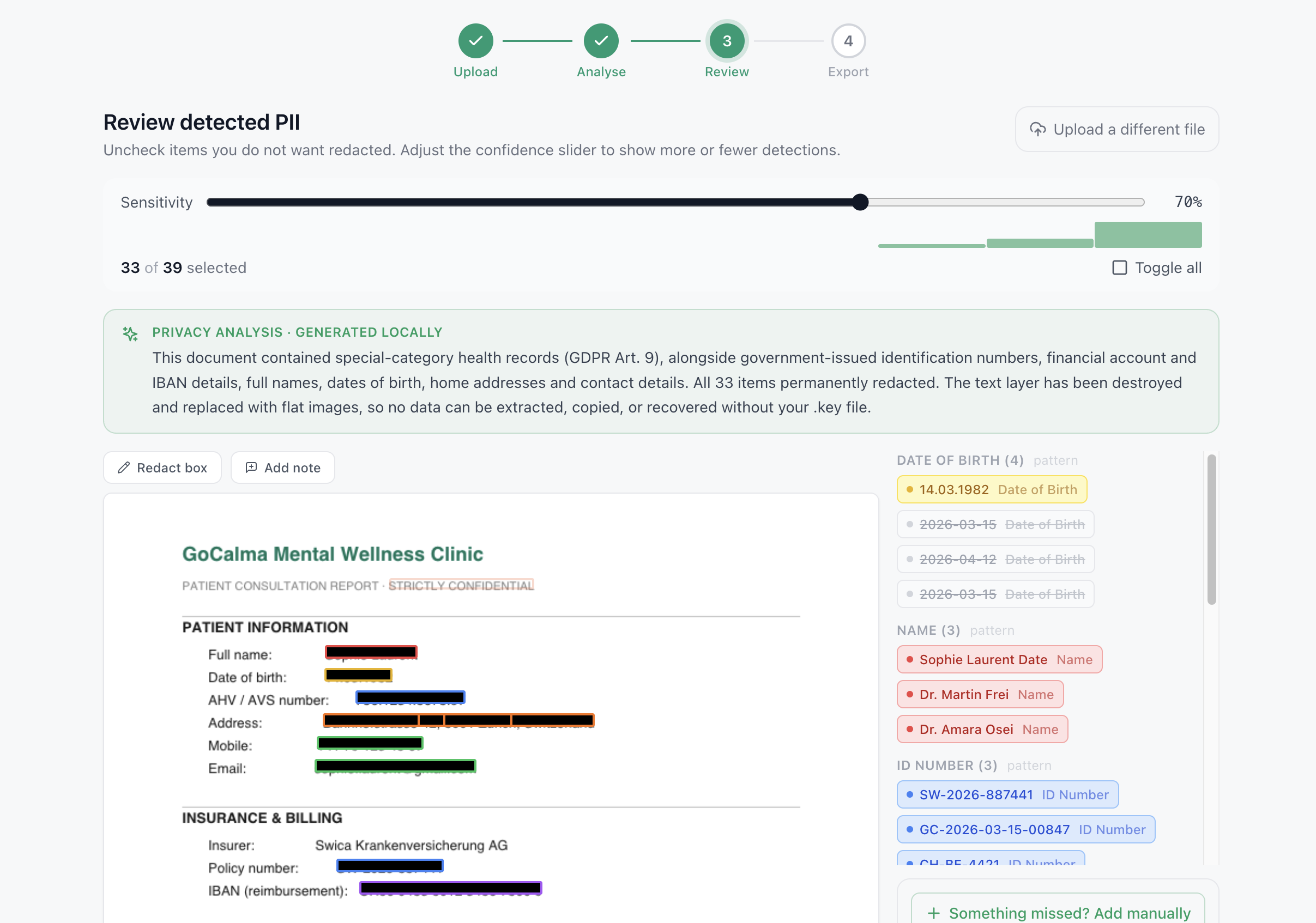
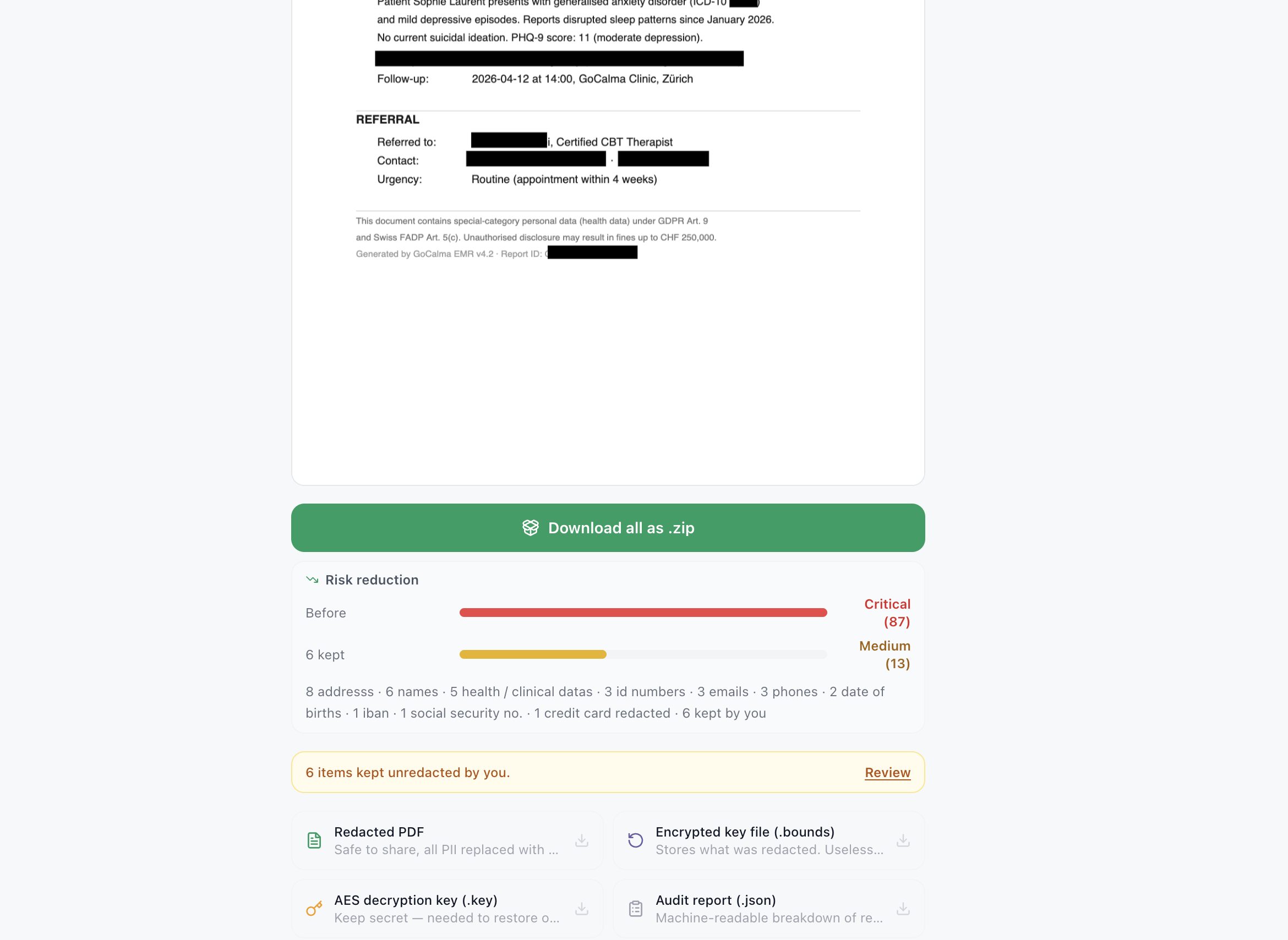
💡 Inspiration
On 27 March, the European Commission confirmed a breach. 350 gigabytes. Confidential documents. Contracts. Cloud infrastructure. The files were on a server. That was enough.
In Switzerland, a data breach doesn't just fine your company. It fines you up to CHF 250,000, personally.
Bounds has no server. Nothing to breach.
🔒 GoCalma's challenge | AI-Powered Privacy Redaction: Own Your Data
Why Bounds
- Data that stays in bounds — nothing crosses the boundary of your device. The whole product promise is that your files never go "out of bounds" to a server.
- Setting bounds on what's visible — redaction is literally drawing a box (a bound) around sensitive information and limiting what can be seen.
What it does
- ✈️ Fully offline — works in airplane mode after first load
- 🧠 Hybrid AI detection — multilingual BERT NER + 40+ regex patterns, all local
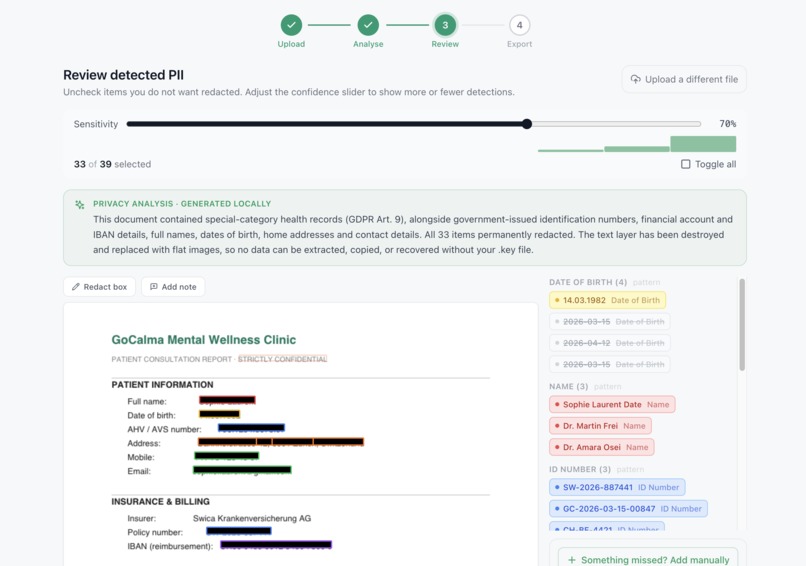
- 🔍 Auto-detects PII — names, addresses, IBANs, SSNs, emails, phones, passports, DOB, health data, credit cards
- 🌍 8 UI + document languages — EN, DE, FR, IT, ES, PT, NL, PL
- 📷 OCR for scanned PDFs — Tesseract.js with spatial word reconstruction for form layouts
- 👤 Face detection — universal browser face detection with TinyFaceDetector fallback
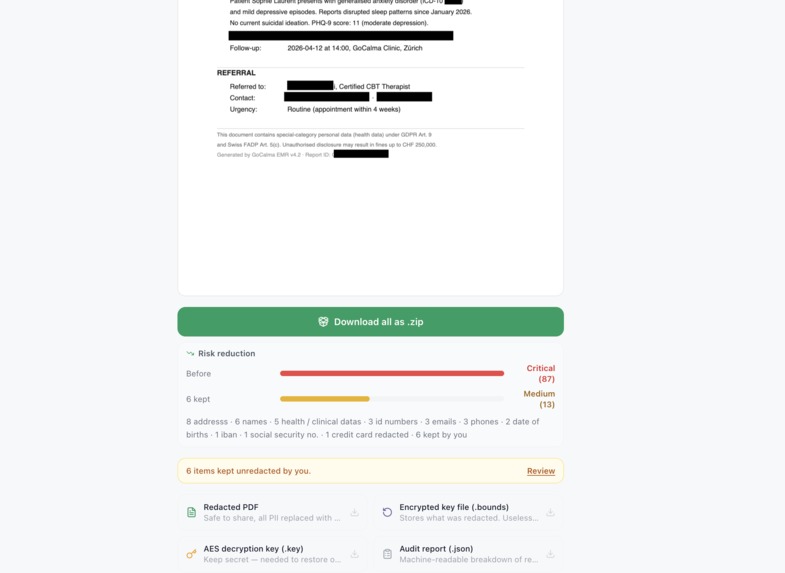
- ⬛ True redaction — pages rasterised to image, original text layer removed entirely
- 🗝️ Reversible encryption — AES-256-GCM vault + .key file, restore original values any time
- 📋 Audit trail — timestamped JSON report, no document content included
- 📦 Batch processing — drop multiple PDFs, processed sequentially with default options
GenAI Integration
The Problem: Organisations want to use ChatGPT, Claude, or custom LLMs to analyse documents but sending unredacted files violates GDPR/HIPAA and exposes data to training pipelines.
The Solution: Bounds sits upstream of GenAI workflows:
Sensitive PDF → Bounds (local redaction) → Redacted PDF → Safe to send to: ├─ AI provider for summarisation ├─ Custom RAG pipelines └─ Your platform
Generative AI components running entirely in the browser:
- BERT multilingual NER (430MB ONNX) — discriminative AI for named entity detection across 104 languages
- LaMini-Flan-T5-77M (77MB) — generative AI produces plain-language privacy risk summaries: "This document contains 3 names, 2 addresses and 1 IBAN. Risk level: High."
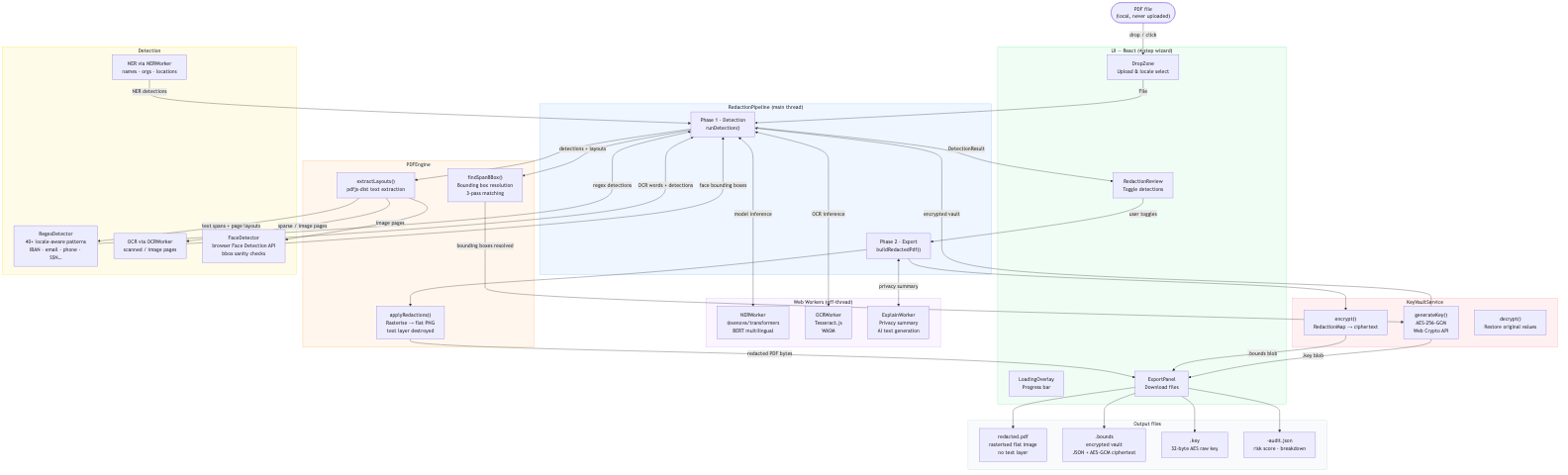
🏗️ How I Built It
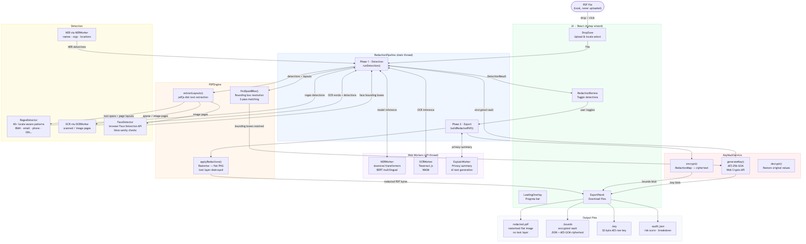
The entire pipeline runs in WebAssembly inside the browser. No backend, no server, no environment variables.
Architecture:
@xenova/transformers— quantised multilingual BERT NER (~430MB ONNX) in Web Worker, cached in IndexedDB after first downloadtesseract.js— OCR for scanned PDFs with spatial row reconstruction to handle two-column form layoutspdfjs-dist— text extraction with precise bounding boxespdf-lib— rasterises redacted pages to PNG, rebuilds clean PDF with no text layer- Web Crypto API — AES-256-GCM reversible encryption vault, no library needed
- React 18 + Tailwind + Vite — 4-step wizard UI
- Deployed as fully static site on Vercel
Hybrid detection: regex runs in parallel with NER for structured identifiers (IBANs, credit cards, passports, phone numbers) with deduplication between layers. 40+ regex rules with per-pattern confidence thresholds and label-context lookbehind for form-style documents.
🚧 Challenges I Ran Into
- WASM + SharedArrayBuffer: Requires both
Cross-Origin-Opener-Policy: same-originandCross-Origin-Embedder-Policy: require-corpheaders. Easy to miss, hard to debug when it fails silently. - Bounding box alignment: Mapping pdfjs extraction coordinates to pdf-lib render coordinates required careful calibration across different PDF structures.
- OCR form layout: Two-column forms get read column-by-column by Tesseract, so "Emergency contact:" and "Jean Dubois" end up 20 lines apart in the text stream, breaking label-context regex. Fixed by reconstructing reading order from word bounding box positions.
- Progressive loading: Fitting a 430MB model into a UX that doesn't feel broken required progressive loading states, a network request transparency panel, and IndexedDB caching so the download only happens once.
- Face detection cross-browser: Chrome's Shape Detection API requires an experimental flag. Replaced with a universal fallback using TinyFaceDetector via ONNX, so face blurring works in all browsers without flags.
🏆 Accomplishments I'm Proud Of
- Genuinely zero uploads. Open DevTools → Network tab during processing. Nothing outbound. The privacy guarantee is architectural, not a policy.
- Reversible redaction. Share a document with full confidence. Restore original values any time with the .bounds vault + .key file pair. I haven't seen this done in a browser-native tool before.
- Works in airplane mode. Demoed at 35,000 feet, Dublin → Zürich, airplane mode on.
- Universal face detection. Works in Firefox, Safari, Chrome, no experimental flags required.
- 176 unit tests, 100% pass rate. Production-ready code quality.
📚 What I Learned
- Local AI inference in the browser is genuinely viable now. WASM + Web Workers + IndexedDB caching makes a 430MB model feel reasonable.
- The Web Crypto API is powerful and underused. Most teams reach for a library when the platform already has everything needed for AES-256-GCM.
- Privacy by design beats privacy by policy. Architectural guarantees beat trust-based promises.
- OCR is a coordinate problem as much as a text problem, getting the words right is only half the work.
🚀 What's Next
Near term:
- Streaming processing for large documents (100+ pages)
- DOCX and XLSX support
- Image redaction (JPEG, PNG standalone files)
Later:
- Desktop app (Electron wrapper, removes browser memory limits for very large files)
- Email redaction (.eml, .msg)
- Custom entity types, user-defined patterns saved locally
💼 Business Model
Bounds is MIT licensed. The enterprise layer adds priority support, SLA guarantees and white-label deployment for regulated industries.
🙏 Acknowledgements
Built for GenAI Zürich Hackathon 2026, GoCalma Challenge.
GoCalma's challenge pushed the architecture toward truly zero-trust design. Thanks to the GenAI Zurich community for inspiring privacy-first innovation.

Log in or sign up for Devpost to join the conversation.