-

Banner
-

Logo
-
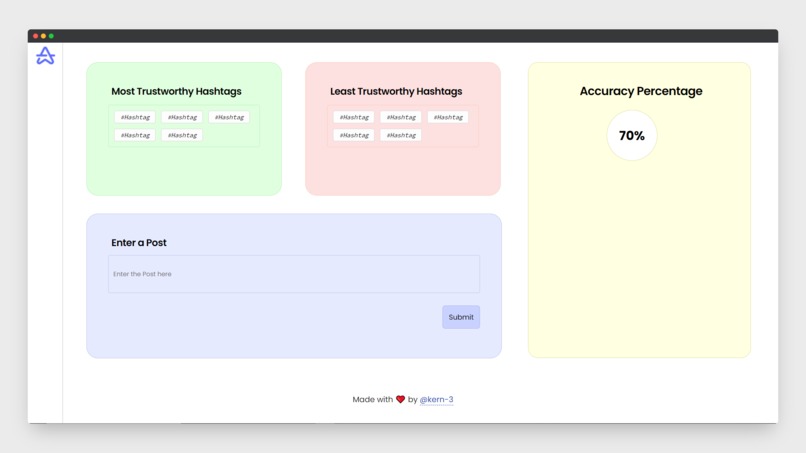
Website we had scrap off
-
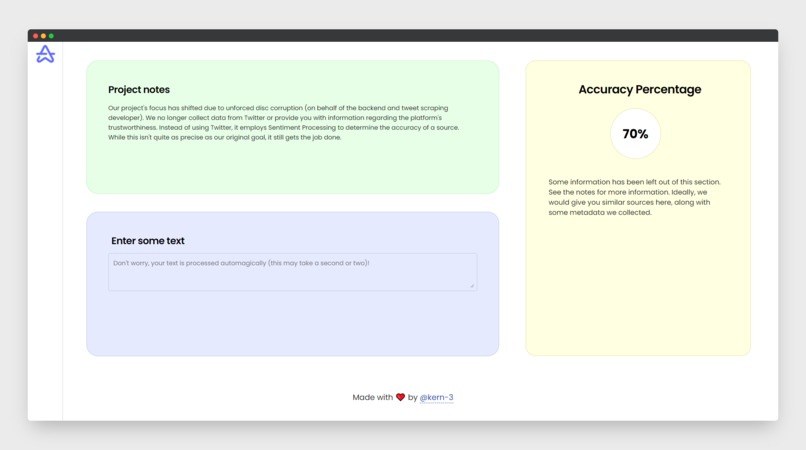
The Current website


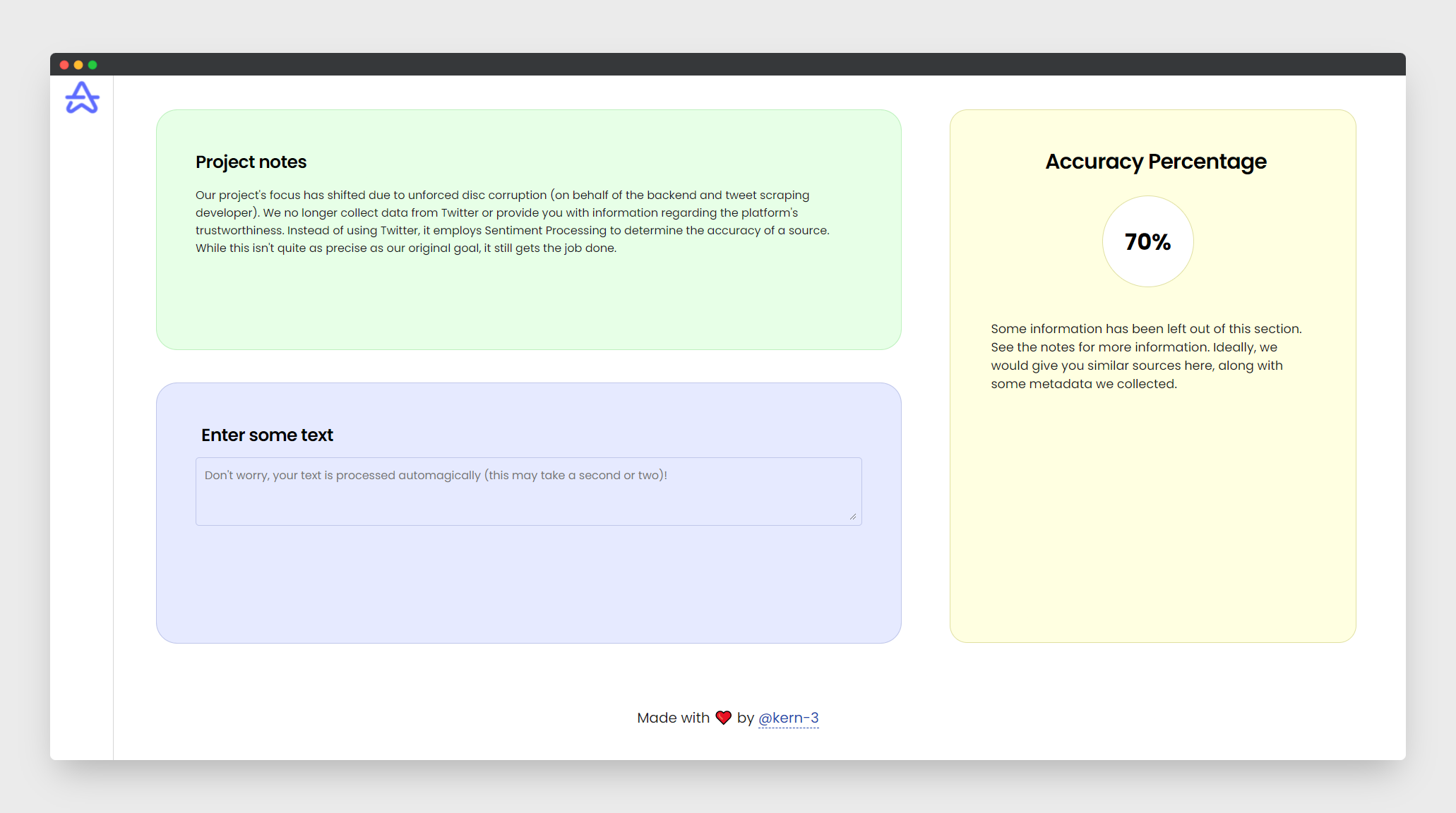
Note
We were compelled to abandon the Twitter portion of our project after the "rapid unplanned disassembly" of the backend engineer's computer's disc. At the moment, it's just a tool for interacting with a backend that specialises in sentiment analysis. We've left the README in its current state below so you can see what we were close to accomplishing if it weren't for Rocky Mountain Power (thats right, I called them out. Fight me).
The reason why we don’t have a full-fledged website isn’t because of a faulty backend or a faulty front end but rather it’s a connectivity issue between the two.
Cross-Origin Resource Sharing (CORS). CORS is a standardization of HTTP headers that specifies the origin of the sender (e.g. the domain). The purpose of CORS is to let the browser know if it should permit the loading resource. CORS only works over HTTP (unencrypted HTTPS). The website is HTTPS, but the API is not (HTTP).
CORS disallows the loading of HTTP resources from HTTPS, which means we can’t use our API (fully-working) from our frontend. There are three ways we could get around this:
- Disable browser safety and protection, which is is impossible for obvious reasons.
- Get the API an SSL certificate (thus allowing for HTTPS). Also impossible (it would require changing IP routing tables over SSH on a remote server; synonym for a bad idea).
- Get the API and the Frontend under the same domain. The last idea, get them under the same domain. We cannot do this because we do not own the domain we use (we use Netlify).
Our API: http://166.70.232.119:443/ (single endpoint, query, with a single variable q. Example: http://166.70.232.119:443/query?q=my%20cat%20killed%20eighty-seven%20door%20to%20door%20salemen)
Inspiration
We were motivated to create a tool to try to discern the difference between what is trustworthy and what is not after observing the widespread misuse of social media and the spread of fake news via social media. Your Aunt Velma will no longer be able to claim that Bonobos are using 5G to spread poisons into millions of people's drinking water! Doesn't it sound fantastic...?
What it does
Accurate is a tool that can help you figure out which online sources are the least trustworthy. This is accomplished by gathering information on which sources are related to which social media posts (in this case, Twitter). After this information is gathered, NLP is used to identify basic intent, and the result is skewed by the popularity of the source. Following that, the data would be traced back to the social media site, and some factors might be linked to identifiers (e.g. hashtags).
- Data Collection:
A bot will be used to start with one post and then go on to others, collecting information along the way. After that, sources are gathered, and all data is converted to a format that the Data Analyzing engine can understand. - Data Analysing:
Using Natural Language Processing to first determine a source's purpose, then biassing it with metadata acquired during data collection. Data is looped back to social media, where identifiers (hashtags) are assigned a trustworthiness grade. - Data Visualisation:
We've also built a web application to enable users to engage with our tool, which provides the user with accuracy of specific posts and hashtags, as well as posts related to the user's post in a visually appealing manner.
How we built it
This project is made of a few different components:
- Crawler: Rust, Asynchronous processing (Tokio + Hyper), Web scraping Twitter, JSON
- AI & NLP: Natural Language Sentiment Analysis, Python (Tensorflow, Pandas, NLTK), R (ggplot), Lots of homegrown Data
- Backend: Rust, Asynchronous processing (Tokio + Hyper), Data aggregation, REST Arch.
- Frontend: HTML, CSS, Javascript, JSON
- Pitch Deck: Figma
Cloning repo
git clone https://github.com/kern-3/accurate.git
cd accurate
Crawler
This is the peice that grabs social media posts and sources, and bundles them into a file that the NLP software. The crawler is built in Rust, so you can just use the cargo utility that we all know and love :)
- Rust
- Asynchronous processing (Tokio + Hyper)
- Web scraping Twitter
- JSON
cd crawler
cargo build --release
# Find the binary where it normally is (target/release/accurate-crawler)!
# View the help message for invocation.
AI & NLP (natural language processing)
The Natural Language Processing aspect of this project is one of the most critical parts. It should only be needed to run once per group of crawler output data. This is built in Python, so you can run it as normal (but download the dependencies first!).
- Natural Language Sentiment Analysis
- R (ggplot)
- Python (Tensorflow, Pandas, NLTK)
- Lots of homegrown data
sudo pip3 -r requirements.txt
python3 accurate-nlp.py
# View the help message for invocation.
Backend
The view from the outside world! This peice assembles crawler and NLP data into a final product, which is then accessible via a REST HTTP server. This is also built in Rust, so build it the same way as the crawler!
- Rust
- Asynchronous processing (Tokio + Hyper)
- Data aggregation
- REST architecture
cd backend
cargo build --release
# Find the binary where it normally is (target/release/accurate-backend)
# View the help message for invocation.
Frontend
Whats the point of a backend without a front end‽ This is hosted on a server that the website domain points to. To host it on your local computer, do this!
- HTML
- CSS
- Javascript
- JSON
- Figma
cd frontend
# Open the index.html file
Challenges we ran into
- One of the most significant challenges we faced during the hackathon was a 13-hour power outage at one of our teammates' location, which prevented us from progressing because we needed data that he had to provide for further predicting the outcomes from that data and aggregating it, as well as connecting the frontend, backend, and model, but it's something no one could avoid.
- Also one of the issues we encountered was obtaining the enormous amount of data we required. We concluded that using already gathered data would be against the spirit of the competition, so we opted to collect our own. We discovered that Web Scraping Twitter was the ideal tool for the job because of a combination of incredibly fast networking rates and a highly parallel processor.
Accomplishments that we're proud of
- This is our (kern3’s) first project ! As a result, we're pleased to be capable of doing anything like this. We're also pleased with how we divided the tasks among ourselves which turned out to be very efficient.
- We successfully finished with the model and were able to achieve 92% model accuracy on test data, which we were pleased with given the obstacles and time constraints.
- Pleased with the website's visual design.
- We were ecstatic since we were able to work with a variety of languages and technologies from various fields and link them together to create Accurate.
What we learned
- We got a lot of experience in how to aggregate data, and how to connect different systems together, especially with so many different languages interacting with each other.
- We all learned a lot about how to interact in reasonably large and complicated projects because this was our first/second hackathon, and we had a great time working in our team.
What's next for Accurate
- Given the time (and possible financial backing), we would love to package this technology into a browser extension, for easier, inline, and informed social media interaction.
- We'd also like to expand our reach to various social media sites and check for the accuracy of the information shared there too.
Built With
- bson
- css3
- ggplot
- html5
- hyper
- javascript
- json
- keras
- natural-language-processing
- python
- r
- rest
- rust
- sentiment-analysis
- tokio-rs
- web-scraping-twitter

Log in or sign up for Devpost to join the conversation.