-
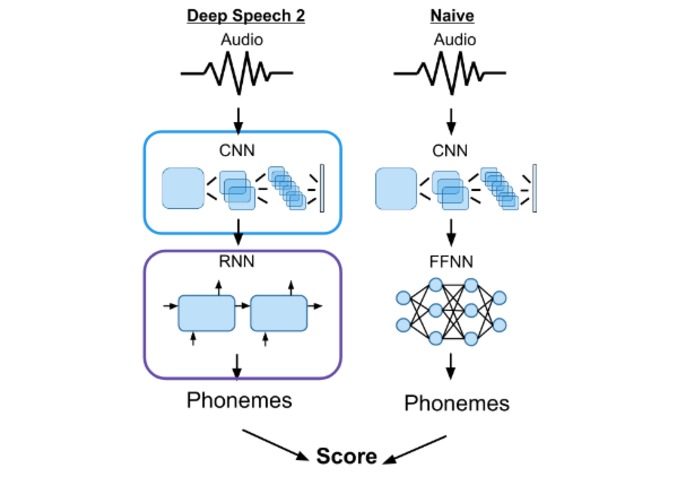
DeepSpeech2 Architecture
-
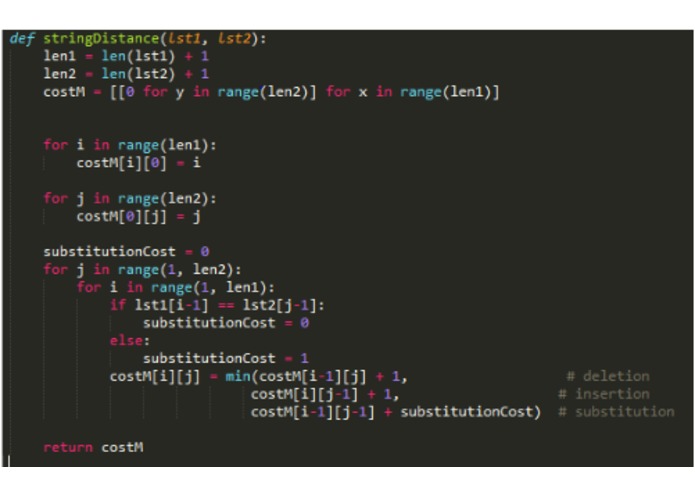
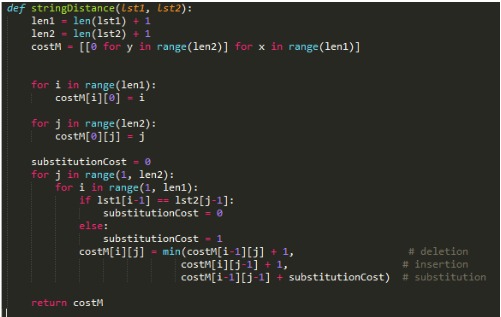
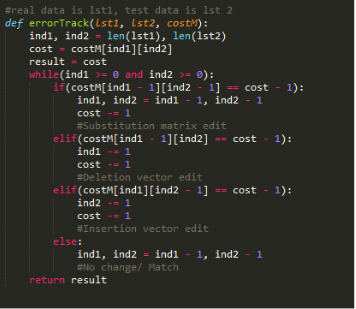
Zhao's Alg.
-
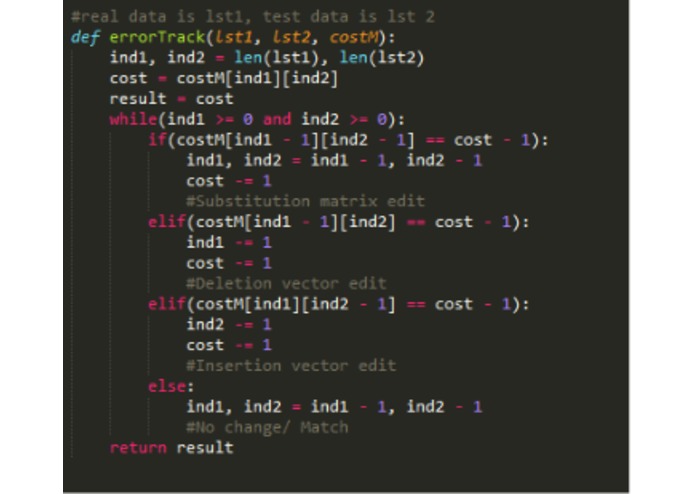
Zhao's Alg., cont.
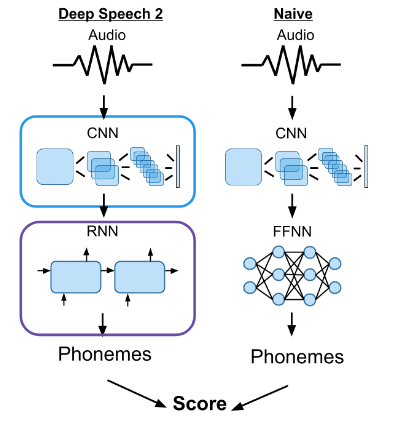
Evaluating accents and improving pronunciation
In the digital age, it has become increasingly important to be able to communicate across cultural, national, and linguistic barriers. Although sites like DuoLingo exist to help you learn the vocabulary and sentence structure of a new language, no such site yet exists to provide detailed feedback on your pronunciation. We're taking the first steps in creating such a system by utilizing the power of deep learning.
Idea
Baidu's DeepSpeech2 model works by combining features extracted from audio by a convolutional neural network (CNN) and contextual data from a recurrent neural network (RNN). We suspect that predictions based solely off of the CNN's features will be much more accurate for standard pronunciations or accents than for nonnative speakers, which predictions utilizing both parts of the network may be able to leverage the contextual information to mask these potential problems.
Results
We actually discovered a bug in Baidu's PaddlePaddle API, which was reproduced by Baidu's mentors. Unfortunately, we found out at 3:00am that they couldn't find a quick way to patch the problem, so we were unable to train or test either the CNN-only or the CNN+RNN networks.
Contributions
We still think that we have provided some interesting contributions or directions for further exploration. In particular, we feel that our idea has potential to identify both common mistakes for individuals and characteristics of accents for different countries or regions, and should be transferable to languages other than English.
We have also set up code in the GitHub repo that should be able to train the CNN-only network using the same parameters as the CNN+RNN network.
We further present Zhao's algorithm as an efficient way for tracking the substitutions, additions, and deletions between two lists of phonemes, one of which may be considered the ground truth. This provides a base-level summary for an individual's or group's results.
Built With
- paddlepaddle
- python
- tears
- the-biggest-data
- the-deepest-learning

Log in or sign up for Devpost to join the conversation.