-
-
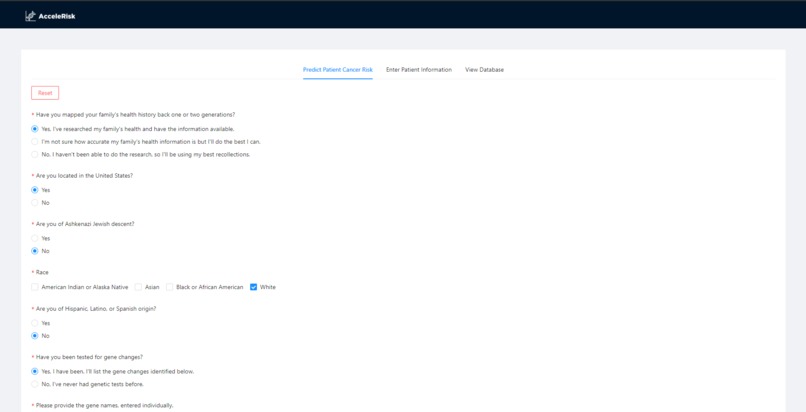
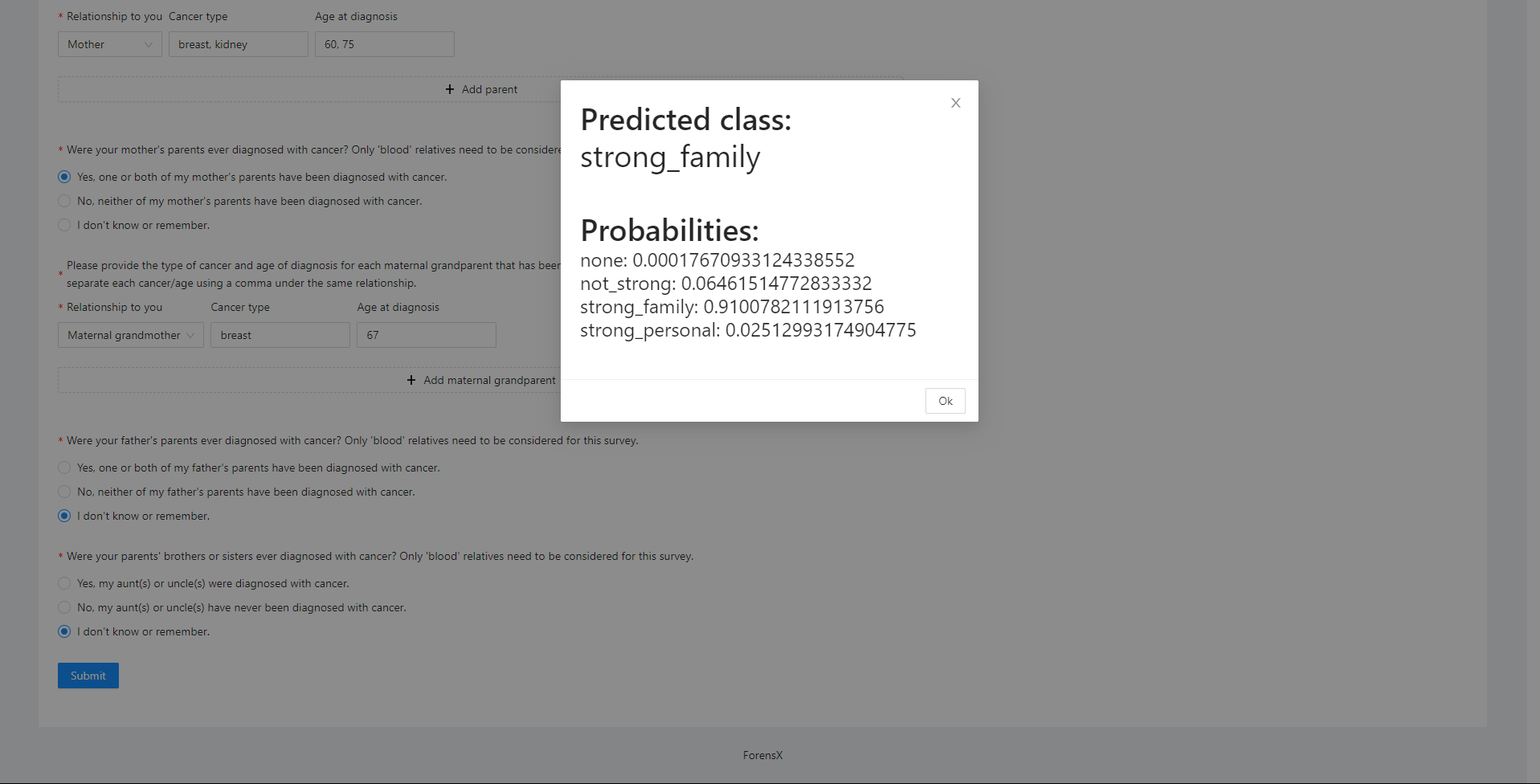
Derived from the Information is Power survey, our dynamic form generation system provides questions based on the user’s selections
-
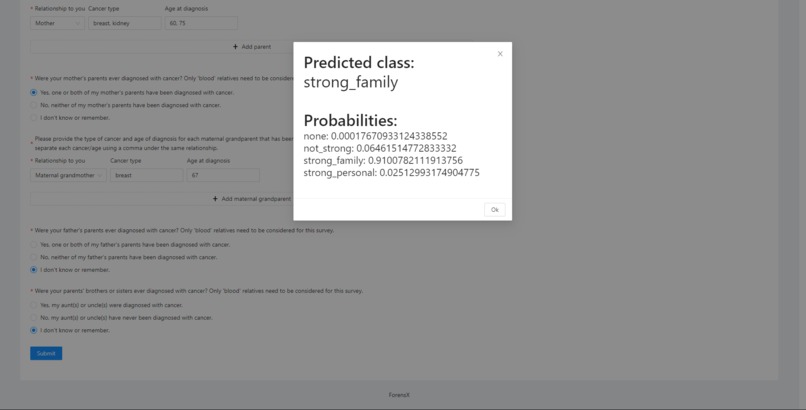
Sample predicted patient cancer risk provided alongside the probabilities returned by our machine learning model
-
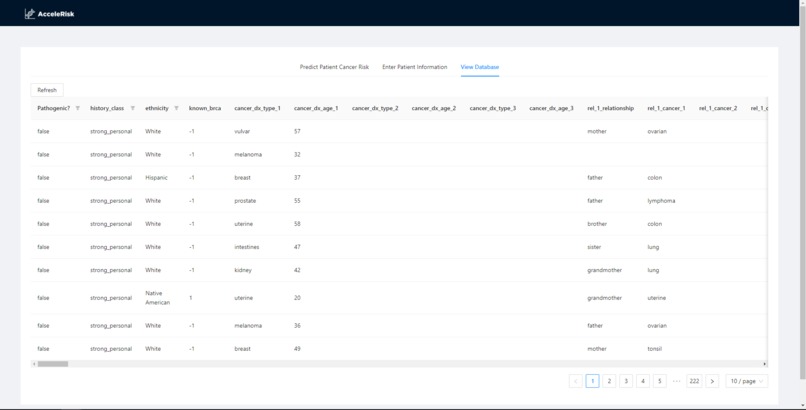
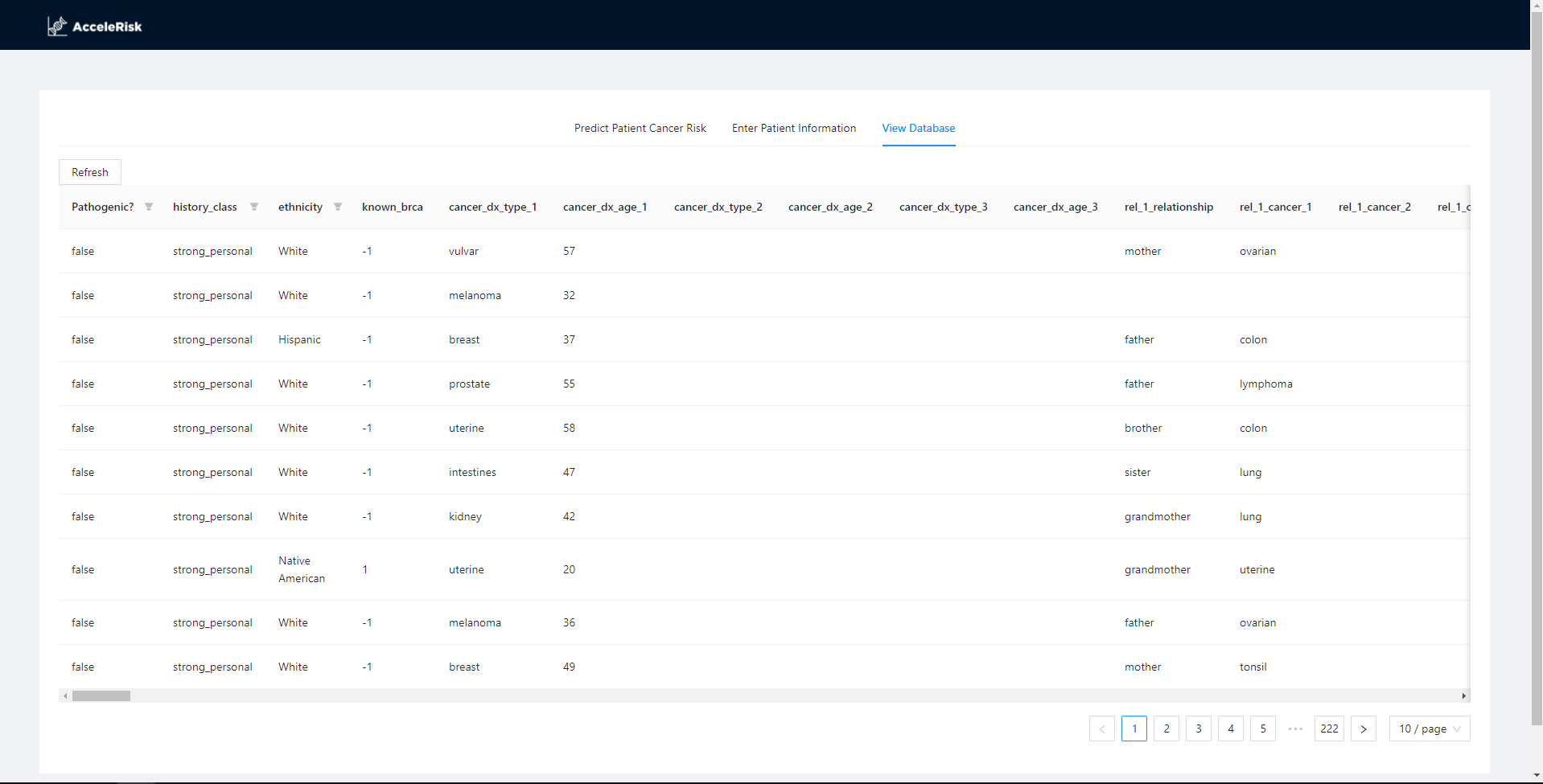
Our database features all patient historical data with filtering and pagination functions, maximizing capability for genetic counselors
Inspiration
Scanning through thousands and thousands of rows of gene and family data is a tiring and arduous process. One must have the patience and the knowledge to filter through the mountain of data and make the correct decision. However, there is a tradeoff. The more time put into looking at one patient and making the correct decision, the less time available to categorize the rest of the patients. To alleviate this problem, we created a robust end-to-end solution incorporating machine learning technologies to help genetic counselors sift through this data more quickly and accurately.
What it does
AcceleRisk provides genetic counselors an all in one place for their tasks. The genetic counselor can enter data into our dynamic form in order to predict the risk of a patient using our machine learning model. Additionally, one can also sort and look up historical data with the ability to add new data to the database.
How we built it
To build AcceleRisk, we utilized Javascript and React to create a frontend. We attached this frontend to the backend API using Flask, written in Python. The backend allows access to our machine learning model. The model in question is a boosted regression tree called Catboost from Yandex. We trained the model on a 90% of the data provided, and it achieved 80% accuracy predicting the 10% that we held out.
Challenges we ran into
We ran into a couple of challenges along the way. Our main challenge was dealing with a low quality dataset. There were extra columns, strange formatting, and inconsistent data. We successfully dealt with that challenge through our specialized clean up process. Our second challenge was dealing with the wildly different answers within the data. The data did not lend itself to an easy clean up as many of the columns were unstructured text data. We overcame this challenge through using lookup tables and text similarity. Finally, we had trouble working creating dynamic forms with React.
Accomplishments that we're proud of
Our greatest accomplishments came from our greatest challenges. We cleaned a terribly low quality dataset into a high quality dataset. This cleaned dataset allowed our model to achieve 80 percent accuracy with just 2000 rows of data seen.
What we learned
Coming into this challenge, we were pretty aware of the theory of data cleaning and machine learning. However, applying this theory was a wholly different task. We improved significantly in our understanding of the process of cleaning different types of data, and what data is best to put into models. In addition, we learned about data augmentation and strategies to maintain model accuracy. Finally, we learned how to integrate a React front end with a Flask backend.
What's next for AcceleRisk
In the future, we hope to train and test different models, including more Deep Learning models as we stuck to mostly Machine Learning. As for our frontend, we hope to create a form that is more accessible and coherent for users. As for our backend, we want to upgrade our database from a csv to a SQL database.


Log in or sign up for Devpost to join the conversation.