-
-
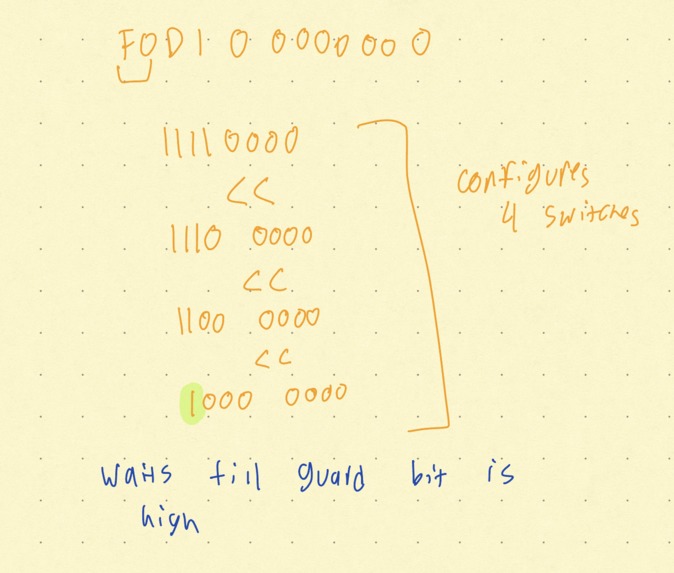
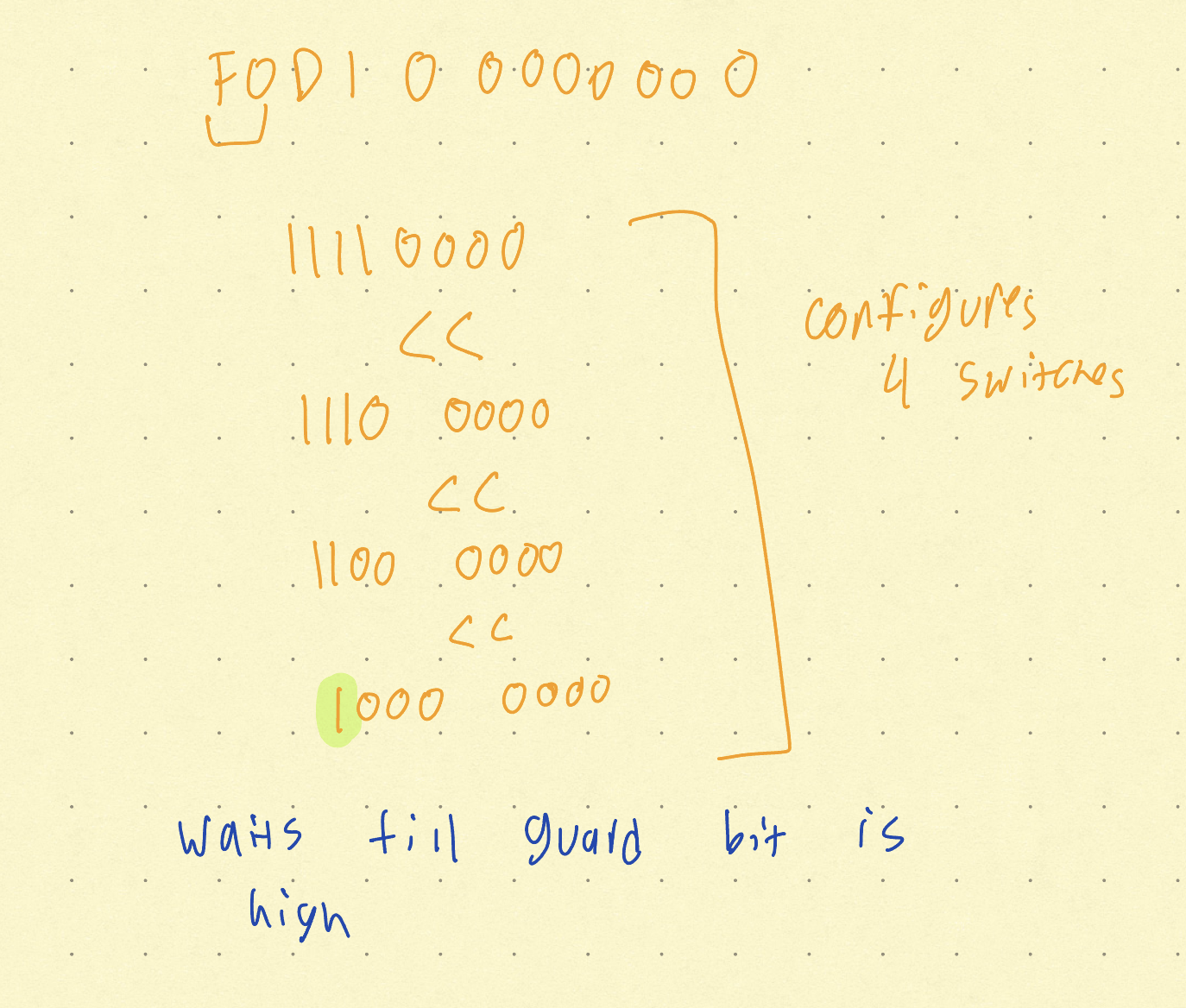
Example Instruction Encoding
-
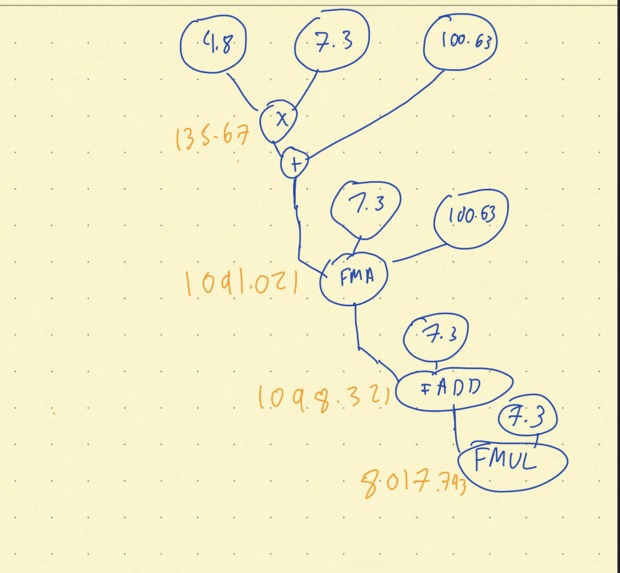
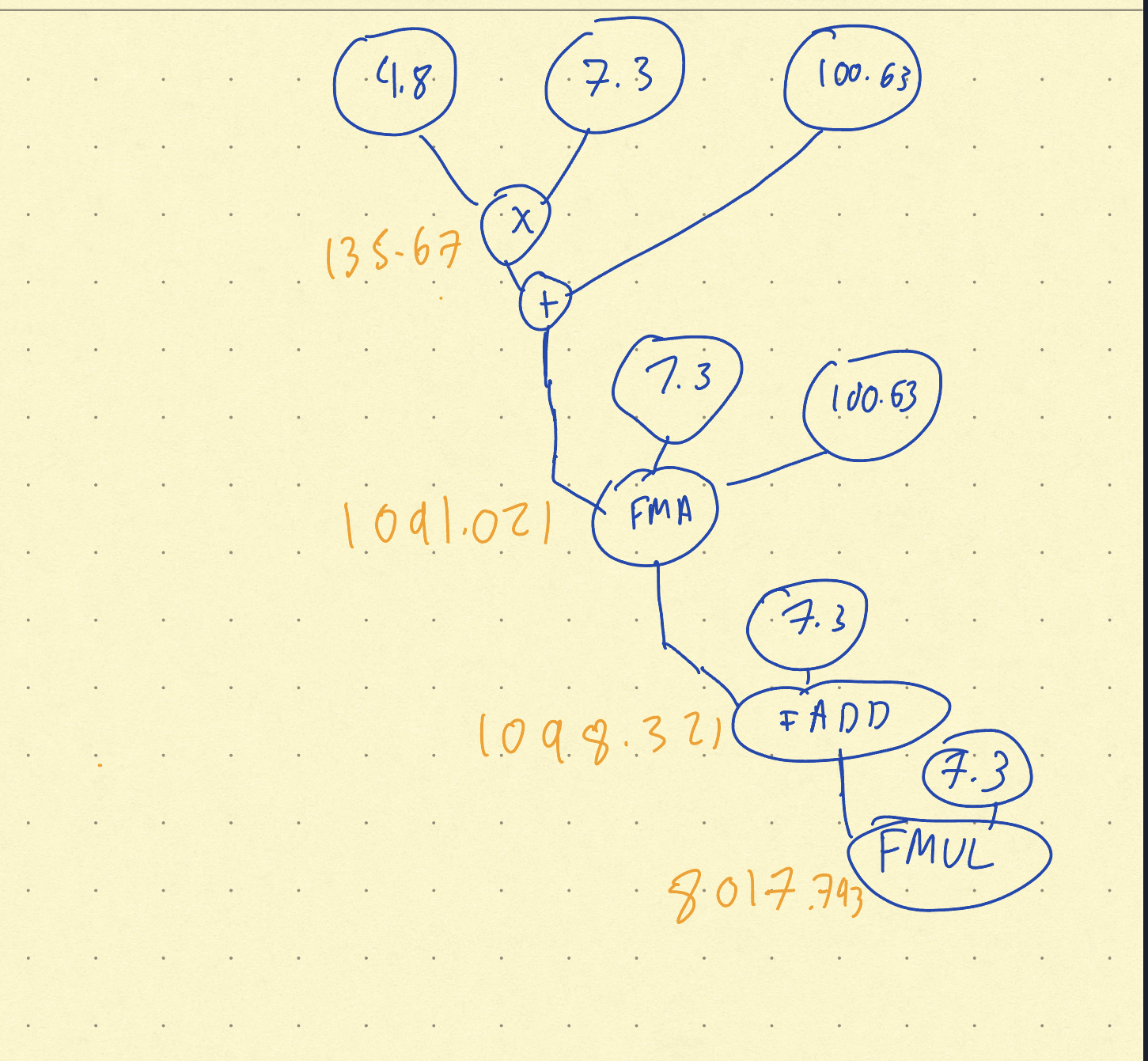
Sample Dataflow Operation
-
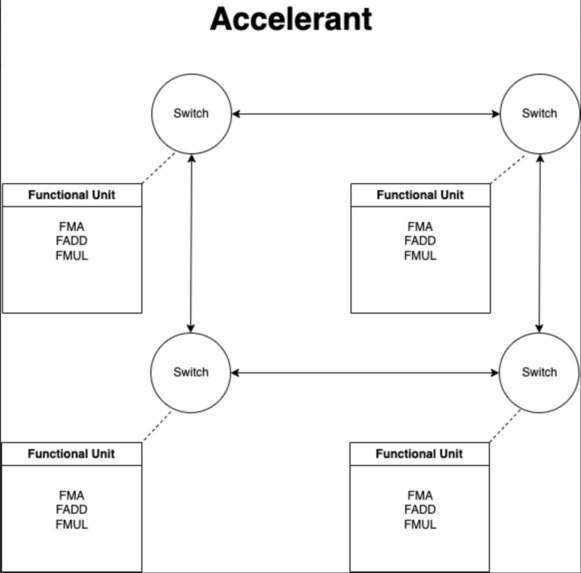
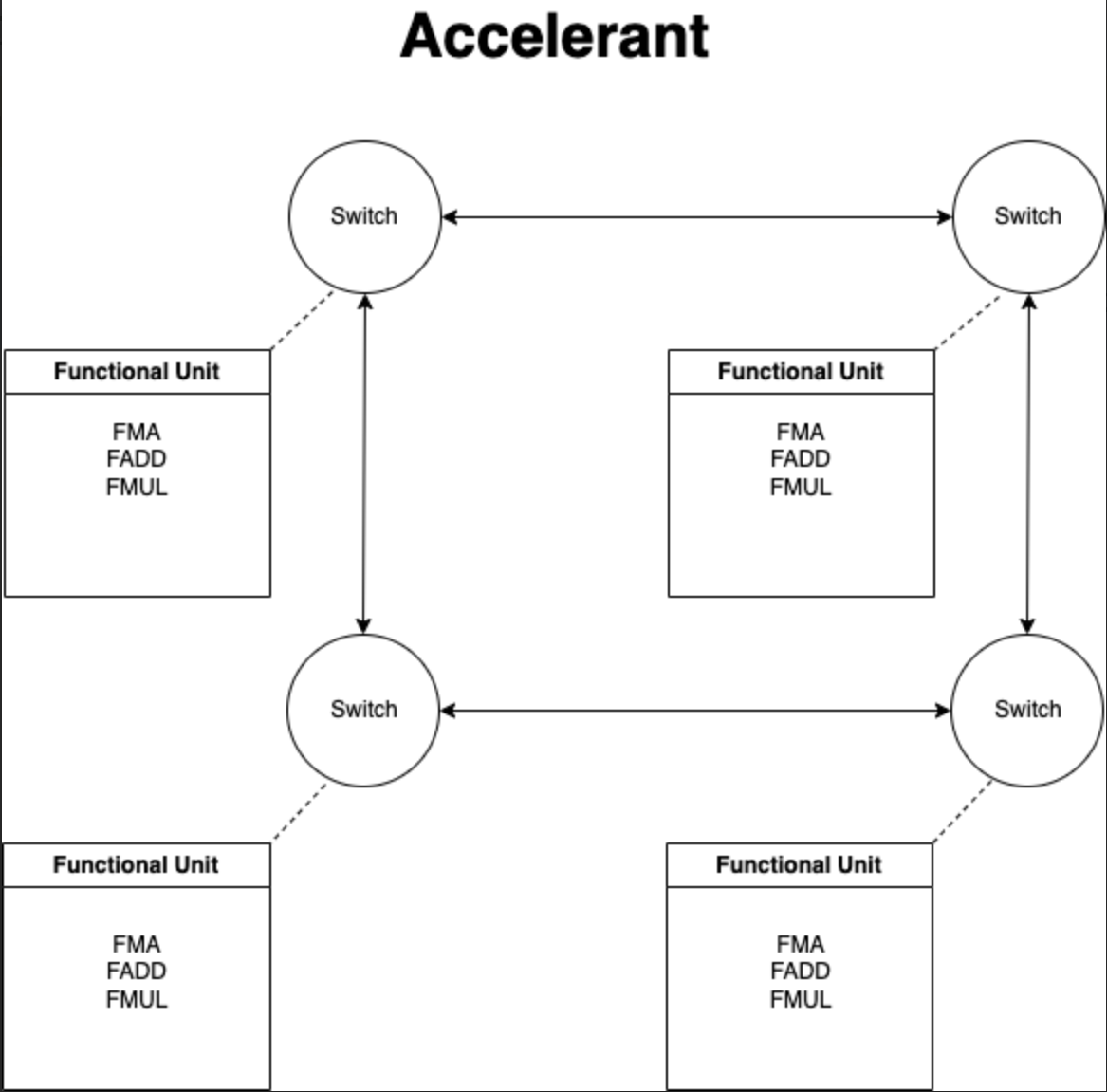
Block Diagram of our Architecture
Inspiration
Our inspirations for this project were the papers DiAG by Professor Dong Kai Wang and DySER by Dr. Ventkataraman Govindaraju. These dataflow-driven architectures are groundbreaking and we want to try and implement them in an accelerator-like architecture.
What it does
This project takes an input of arithmetic instructions that need to be completed. It uses circuit switching to configure an array of functional units to complete the instructions dynamically and efficiently. Think of it as Plinko: the data is the puck, which goes through the pins, which are functional units, and to get an output, we can configure these pins in such a way as to do these operations as efficiently as possible.
How we built it
We implemented floating point math operations from scratch. This required us to understand how the floating point format works. This is an extremely useful implementation since it allows us to compute floating point operations in hardware, much faster than those done in software. We then created our own instruction set for this processor and configured the functional units to perform the floating-point mathematical operations. Then, we created switches that would connect the functional units to the dynamic, circuit-switching datapath to allow for any combination of dataflow through the functional units. Finally, we implemented a configuration of these switches to simulate a matrix-vector product.
Challenges we ran into
Some challenges we ran into were in the implementation of the hardware floating point unit for this project. We had lots of issues with edge cases for some of our operations, but after much optimization and troubleshooting, we were able to iron out all of the errors we encountered and create a fast computational "kernel."
Accomplishments that we're proud of
We are proud of implementing our bespoke architecture for computational acceleration. We were able to implement complex floating point operations for use in this project. Finally, we were also able to create a configuration of these process elements in an effective manner.
What we learned
Firstly, we learned that there can never be enough testing. We would test a variety of numbers in our floating point units and reveal errors that we hadn't considered before. We also found it very useful to draw diagrams and plan before implementing any feature. Finally, we also learned to plan ahead, and not give up because of something that seems unachievable.
What's next for Accelerant
We are going to implement a proper instruction fetch and 6-stage pipeline for the processor and make it more parameterizable. These changes will allow the Accelerant project to generalize for more use cases and become more advanced. We also plan on creating a compiler that can generate dataflow configurations for our processor.
Built With
- systemverilog
- verilator
- yosys





Log in or sign up for Devpost to join the conversation.