-
-
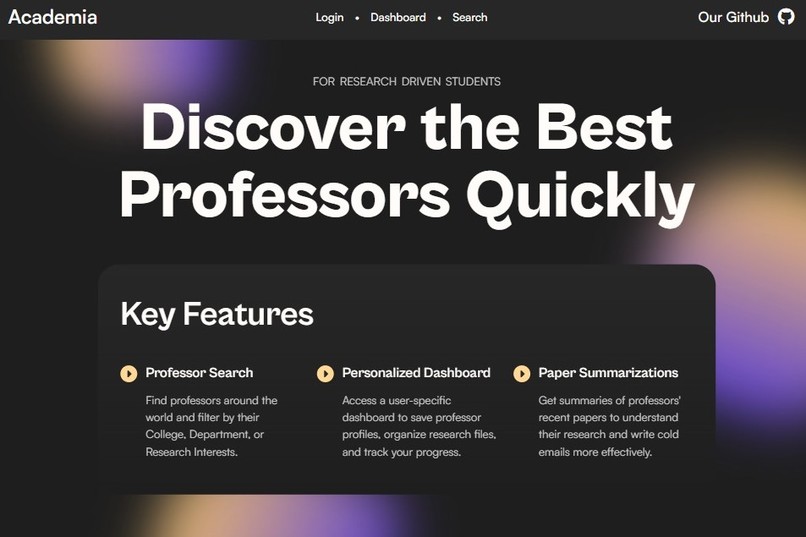
Landing Page
-
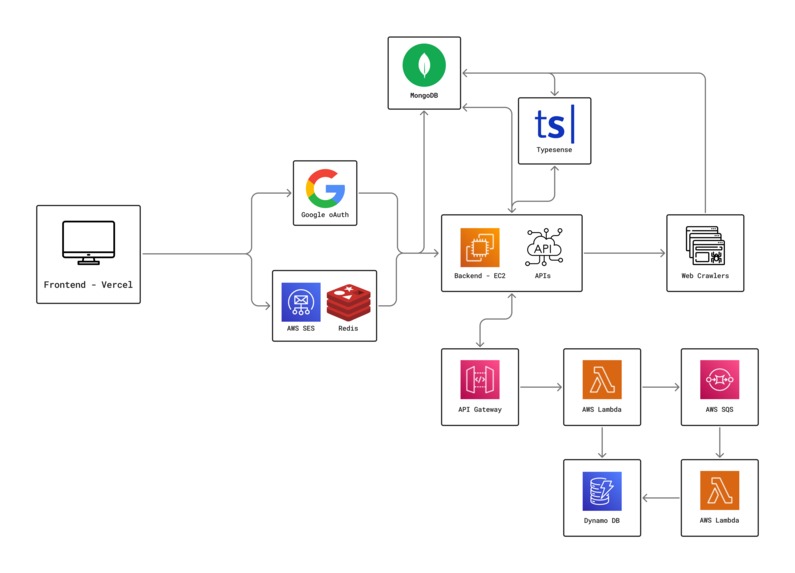
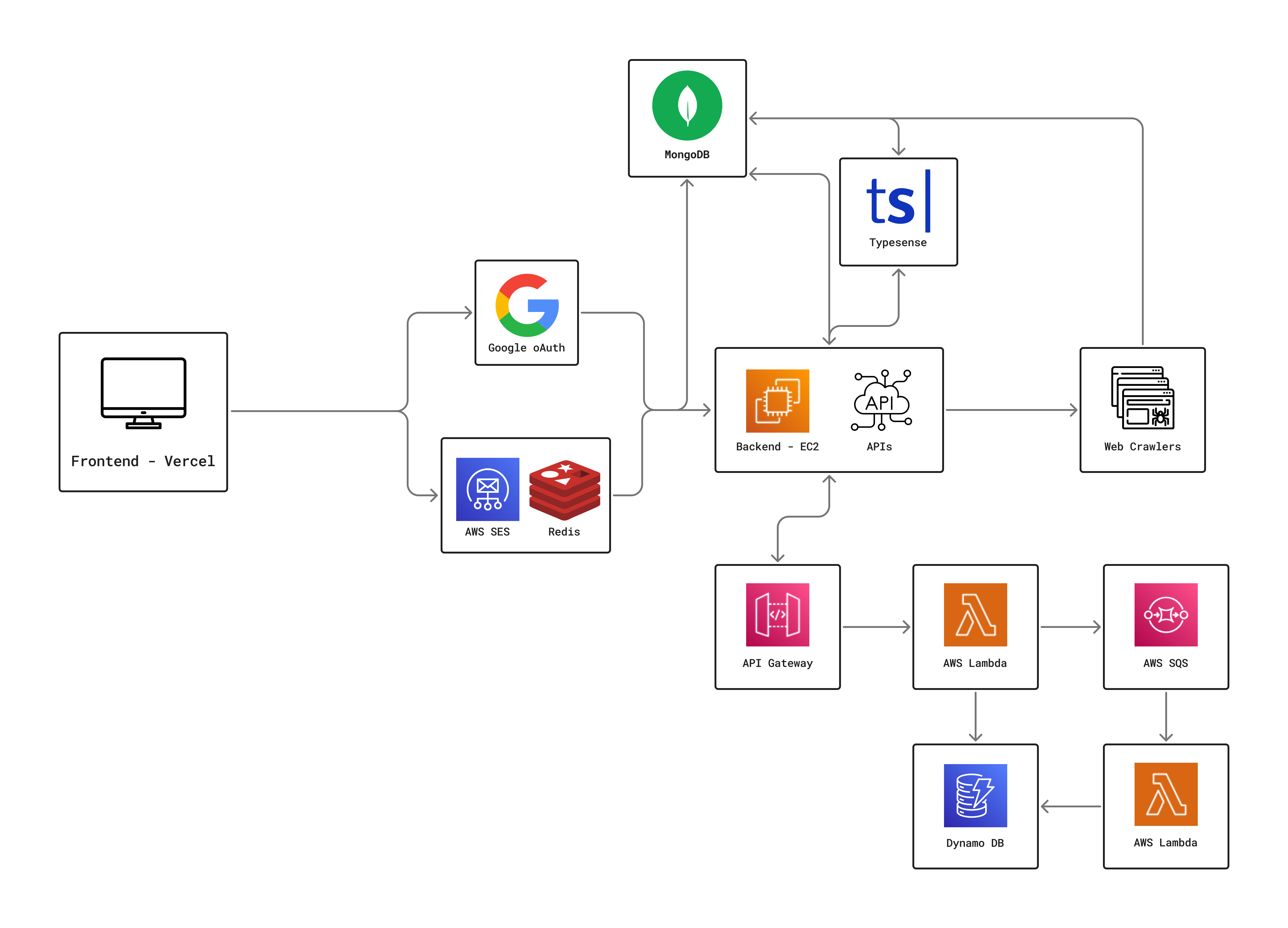
High-Level Architecture Diagram
-
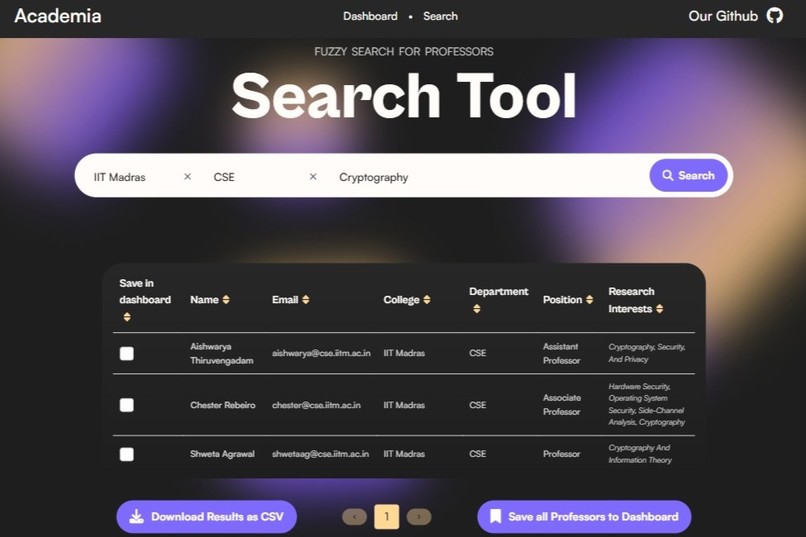
Professor Search Page
-
Login Page
-
Sign Up Page
-
OTP Page
-
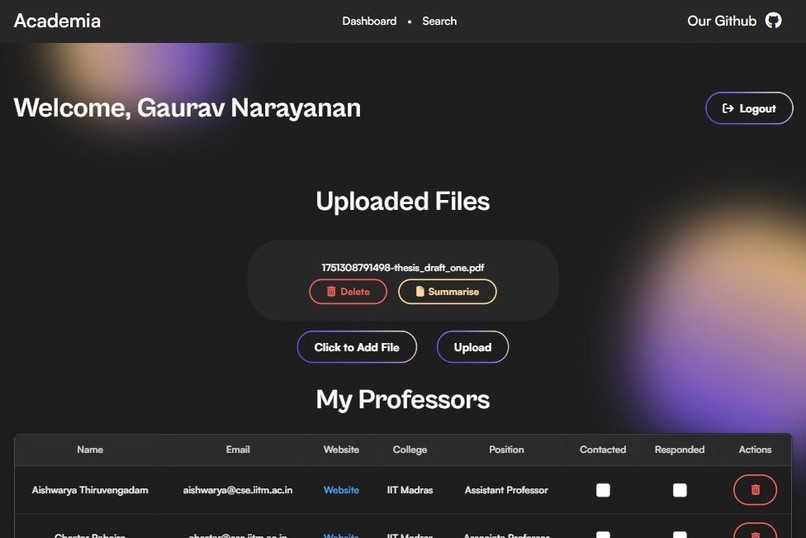
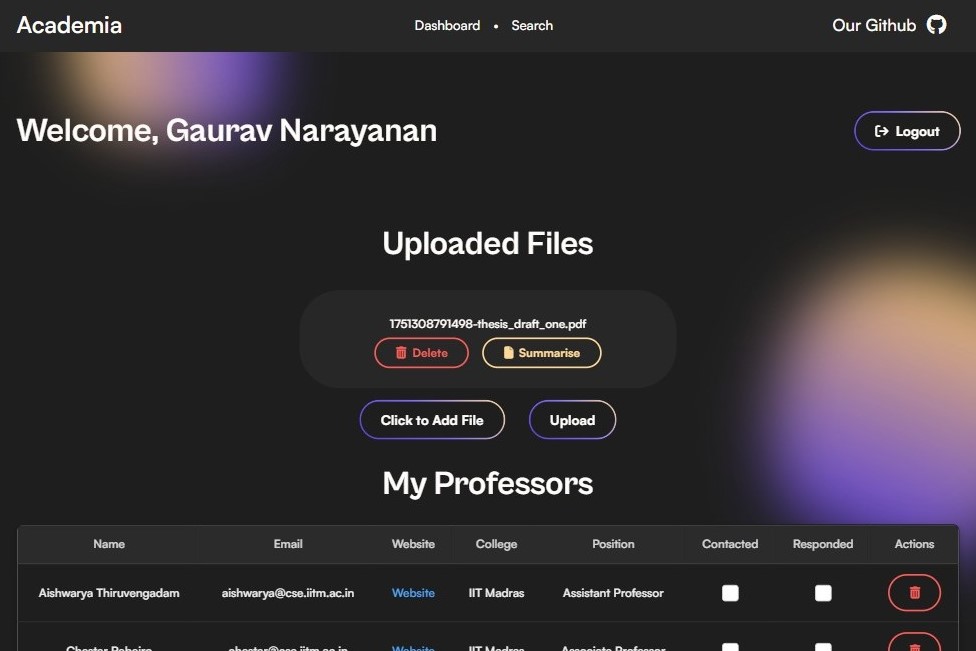
Dashboard Page (Saved Files & Professors)
-
File Preview Modal
-
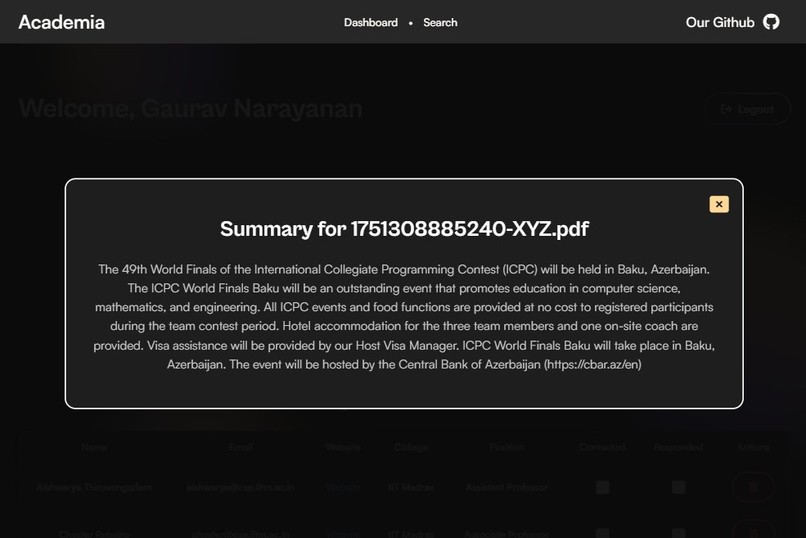
Summarised Modal




Inspiration
Finding the Right Research Opportunity Shouldn’t Take 500 Emails
Cold-emailing professors is a key step for students pursuing research—but the current process is slow, tedious, and inefficient. Our application streamlines the search, helps craft tailored emails, and tracks outreach—saving students hundreds of hours and significantly increasing response rates.
Why It Matters
- On average, cold-email reply rates are just 8.5%, with 23.9% emails opened and many never replied to.
- Personalized emails are 2–3× more likely to be opened and generate up to 6× higher response rates.
- Follow-up emails can double or triple reply rates, yet 70% of emails go un-followed-up.
What It Does
Easy Professor Filtering
- Integrates Typesense for fast, tag-based search
- Filter professors by research interests and save matches to your dashboard
Personalized Dashboard
- Upload & summarize research papers
- Track professors’ mailing info and outreach history
Research Paper Summary
- Instant AI-powered summaries of uploaded papers
- Get concise insights in just a few seconds
How We Built It
Backend Crawlers & Database
- Manual crawlers scrape college websites for professor data
- Store results in MongoDB
MERN + Typesense Search
- MERN stack with Typesense for tag/synonym-based fuzzy searching
- Tags and synonyms map research terms (e.g., “ML” ↔ “machine learning”)
- Render professor info based on matched tags
Authentication & Email
- OAuth + custom auth
- Amazon SES for email handling
- Redis for session or caching management
Personalized Dashboard
- Save matching professors to their personal dashboard
- Download professor lists as CSV
Paper Upload & Summary Pipeline
- Users upload papers to S3
- Summary request triggers API Gateway
- Lambda checks DynamoDB for existing or pending summaries
- If none, sends SQS message to start pipeline
- Triggered Lambda does the following,
- Runs Amazon Textract for OCR
- Calls Hugging Face BART API for summarization
- Stores summary in DynamoDB.
Challenges We Faced
Typesense + MongoDB Replicaset
Typesense required MongoDB in replica set mode, adding setup complexity and performance overhead—especially in limited environments.
Hosting on a t2.micro
Running 4 backend services (API, admin panel, Typesense, summarizer) on a single t2.micro (1GB RAM) strained resources and demanded tight optimization.
Web Crawling & Cleaning
University websites varied widely, requiring custom crawlers and extensive data cleaning for consistency in names, emails, and research interests.
Paper Summarization Pipeline
Due to AWS free tier limits and Hugging Face costs, we had to redesign our summarization pipeline for efficient, low-cost inference.
Accomplishments That We're Proud Of
Typesense Integration
- Support for synonyms and tags to map research interest terms (e.g., “ML” = “machine learning”)
- Tag-based curation rules for filtering professors based on recurring user interests :contentReference
Summarization Pipeline (Free Tier)
- Lambda functions & SQS for event-driven workflows
- DynamoDB to store metadata
- Textract for OCR (up to 1k pages/month free for 3 months)
- API Gateway to expose summarization endpoints
Production Deployment
- Hosted on EC2 Free Tier, serving crawler, Typesense, and dashboard services
Student Dashboard
- Users upload papers → triggers Textract + summarizer pipeline
- Crawler populates professor info
- Dashboard displays saved professors, tags, outreach logs, and summaries
What We Learned
End-to-End System Design with AWS
Gained experience in designing, deploying, and maintaining a full-stack solution using AWS services like Lambda, S3, and API Gateway for scalability and reliability.
Serverless Architecture Principles
Understood how to structure backend logic in a serverless, event-driven model, reducing operational overhead and improving deployment flexibility.
Search Optimization Techniques
Learned to enhance search relevance by extracting and mapping synonyms from research tags, and integrating them with Typesense for more flexible querying.
Large-Scale Service Integration
Learned to manage complexity and ensure consistency while working across multiple connected services including APIs, scrapers, email modules, and frontend components.
Resilient Data Handling
Developed fallbacks and error-tolerant scrapers to handle diverse HTML structures and data inconsistencies across university websites.
What's Next For Academia
Automated Professor Crawler
- Objective: Replace manual data-gathering with automated crawlers.
- Features:
- Scrape faculty profiles from university & institutional websites.
- Capture details like name, department, research interests, publications, contact info.
- Scheduled updates to keep data fresh and accurate.
- Smart deduplication to avoid repeated entries.
Q&A Community Forum
- Objective: Build a collaborative space for applicants and researchers.
- Features:
- Users can ask and answer questions related to:
- Research topics, methodologies, and literature.
- Graduate school applications, essays, funding, etc.
- Tags, votes, and reputation system to surface the best content.
- Searchable archives for past questions and answers.
Email Tracking & AWS Bedrock Integration
- Objective: Streamline outreach and content summarization.
- Features:
- Email Tracking Module
- Log emails sent to professors.
- Track opens, clicks, replies.
- Reminders and status tracking (e.g. “Sent,” “Follow-up due”).
- AWS Bedrock Summarization
- Auto-summarize long email threads.
- Generate concise bullet-point summaries of professor profiles.
- Assist users in drafting personalized emails based on scraped data.
Built With
- amazon-api-gateway
- amazon-cloudwatch
- amazon-dynamodb
- amazon-ec2
- amazon-lambda
- amazon-ses
- amazon-sqs
- amazon-textract
- amazon-web-services
- docker
- google-gmail-oauth
- hugging-face
- mongodb
- node.js
- react
- redis
- swagger
- typesense

Log in or sign up for Devpost to join the conversation.