-
-
System Diagram
-
Web App
-

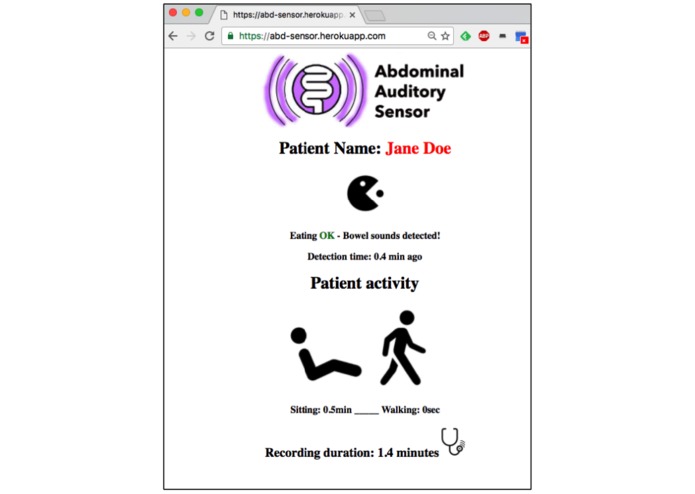
Final Prototype


Real Time Embedded Systems Project
University of Pennsylvania, ESE 519
Team: Jono Sanders, Hitali Sheth, Sindhu Honnali
Code: Abdominal Auditory Monitor on GitHub
Description and Goals
Description:
Ileus, or a lack of movement through the gastro-intestinal tract occurs after abdominal surgery. With over 500,000 stomach surgeries performed every year, it is estimated that ileus costs $750 million annually. Constant monitoring of bowel sounds, to detect movement and activity can help in predicting, diagnosing, or monitoring problems. This device will observe stomach sounds on patients after surgery to help doctors and nurses to better treat them and recover more quickly.
Goals:
- Use external sensor to detect/filter sounds
- Define criteria for different kinds of sound expected
- Train microcontroller to detect
- Visualize on Tablet
- Add additional sensors to detection motion

Preliminary Components and Architecture Layout
Update 1 - Thur, Nov 3rd
Progress so far! We have selected our components and started wiring up the modules to our microcontroller, the Mbed LPC1768. Here is the list of components:
- 3M Littmann Lightweight II S.E. Stethoscope
- 16x2 LCD, show noise counts
- Adafruit Bluefruit LE SPI Friend
- Adafruit 9-DOF IMU Breakout - L3GD20H
We are working on the circuit that will properly filter the sounds coming out of the stethoscope. To determine the the frequency range we should be examining, we are analyzing recordings of stomach noises using python.

Fast Fourier Transform of a stomach grumble
Update 2 - Tue, Nov 8th
We are testing circuits to filter out noisy signals from our stethoscope+microphone. This is much more difficult to get a clear reading out of than we anticipated.

Amplifying and filtering circuit
Update 3 - Tue, Nov 15th
We have begun testing the accelerometer to keep track of patient activity after surgery. The motion data is being collected to help categorize different activities based on magnitude and some directional movement information.

We are also recording sounds from the stethoscope using a powered amplifying circuit as outlined last week. The data is noisy but we are using Matlab filters (Chebyshev 8th order filter, high pass, low pass) to look specifically at frequency distribution and amplitudes in the range of 5 - 880 Hz, as describe in various research papers.
 Raw sound data
Raw sound data
 Stomach sounds filtered through Chebyshev 8th order and decimated to reduce amplitude
Stomach sounds filtered through Chebyshev 8th order and decimated to reduce amplitude
Update 4 - Tue, Nov 22th
Data Transfer
 Perf board with MBED and Zigbee MRF chip for data transfer
Perf board with MBED and Zigbee MRF chip for data transfer
Training Methods used for 50 sample readings of noisy and quiet stomach sounds
Naive Bayes : Testing error: 20%,Training error: 20%
Decision trees : Testing error: 4 %, Training error: 4%
SVM: Testing error: 1%, Training error: 16%
Update 5, Dec 1st
Final Prototype:
 Clear acrylic mounting plates
Clear acrylic mounting plates
Sound Processing in Software :
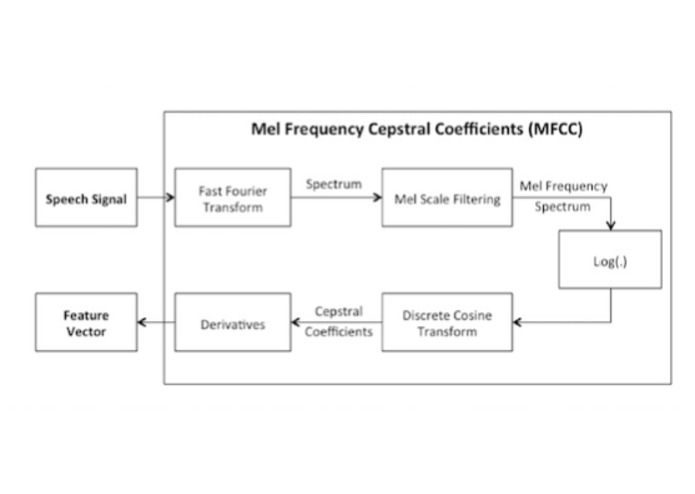
Since amplitude and frequency are insufficient to adequately represent the sound signals we obtained, we use MFCC coefficients which gave us a feature vector. The MFCC coefficients basically give us a higher number of features for each sound sample, extracted from its frequency and amplitude.
The mel-frequency cepstrum (MFC) is a representation of the short-term power spectrum of a sound, based on a linear cosine transform of a log power spectrum on a nonlinear mel scale of frequency. Having these coefficients extracted from the FFTs helped us to represent audio sounds effectively and be able to classify them.
 Decision Tree for FFT values from stethoscope recordings
Decision Tree for FFT values from stethoscope recordings
Abdominal sound training :
We used 50 samples of stomach sounds which includes sounds when talking, moving, after eating and no movement.
We tried various machine learning algorithms to classify the sounds. SVM, Naive Bayes and Decision tree were implemented in matlab as well as Python to process the signals.
Decision trees gave us the highest accuracy and we decided to implement that on our processor.
Basically decision tree gave us the most important features among all the features which are essential for classification. This was helpful when we had to implement the model on ARMLPC 1768, since there are memory constraints on the hardware.
We then used these decision points and implemented a decision tree on the board. Though decision tree is not the best model choice, with the considered ARM LPC1768 memory constraints and limited training samples, we chose to implement it.



Log in or sign up for Devpost to join the conversation.