-
Complete Authentication
-
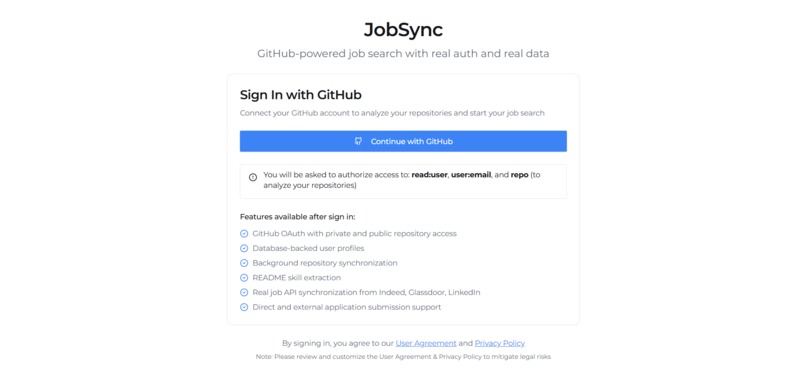
Auth Page
-
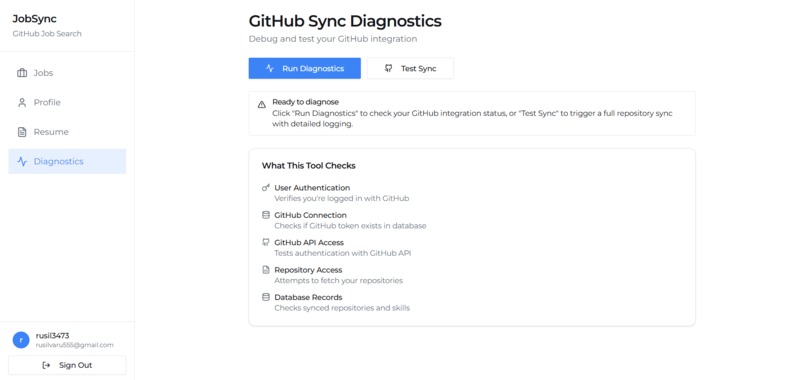
Profile Page
-
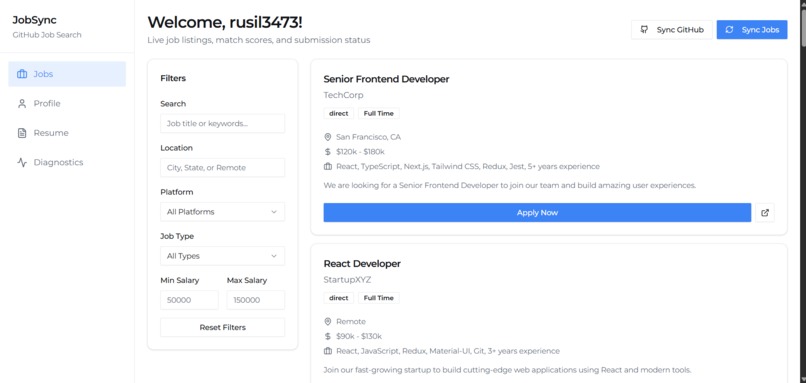
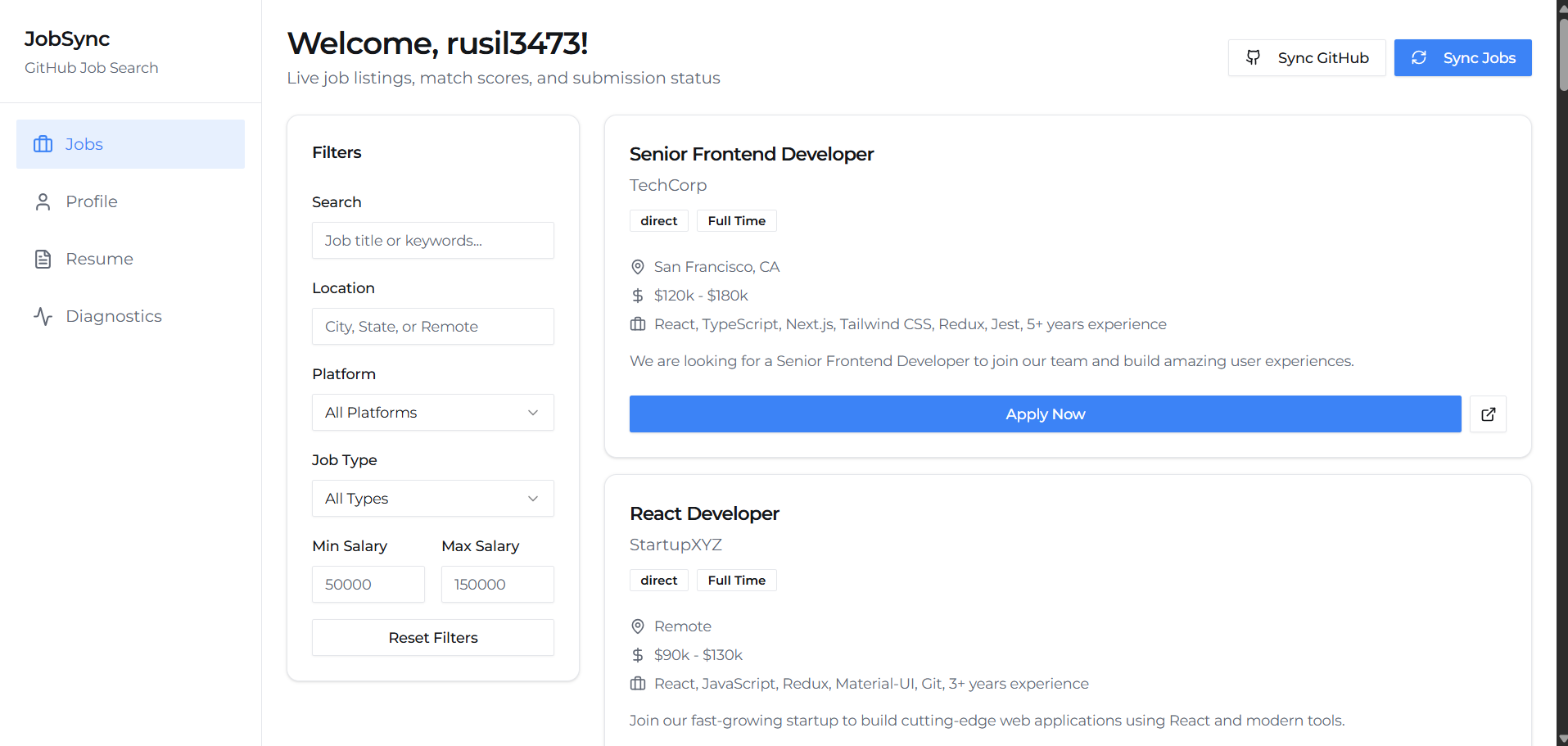
Jobs Page
-
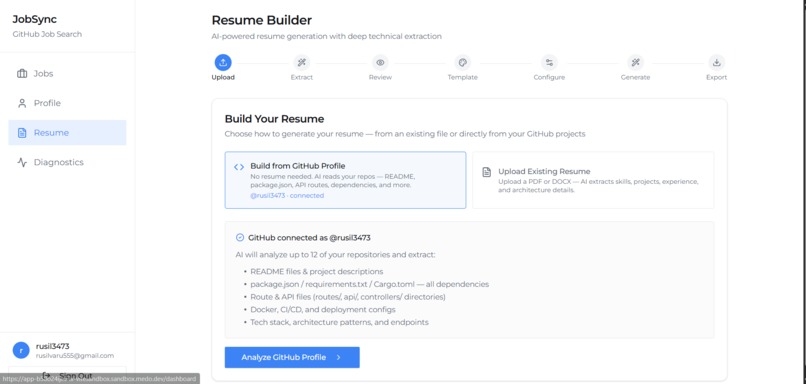
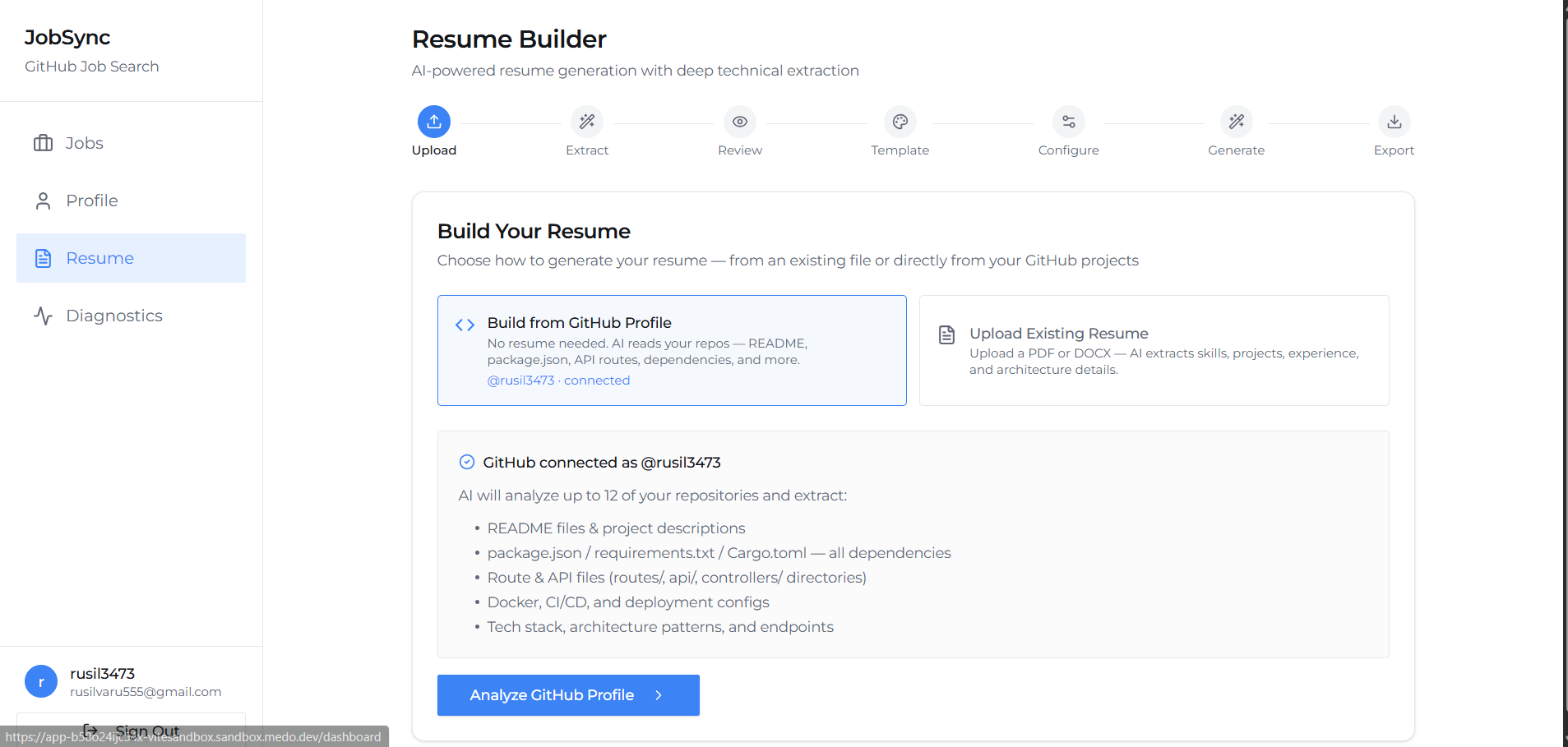
Resume Builder Page
Inspiration We all know the pain: you're a developer with real projects on GitHub — real React apps, real APIs, real contributions — but when you apply for jobs, you're still copy-pasting the same bullet points into PDF templates that no recruiter reads. The disconnect between what you actually build and how you present yourself is massive. Meanwhile, job boards are noisy, irrelevant, and don't understand your stack.
We built this platform because we believe your code should speak for itself. Instead of writing "Proficient in React" for the hundredth time, we wanted a tool that reads your repositories, extracts your real skills, and matches them to jobs that actually fit.
How We Built It The frontend is a React + TypeScript application powered by Vite, styled with Tailwind CSS and shadcn/ui components. Users authenticate via a custom GitHub OAuth flow, and we fetch their real repositories, READMEs, and tech stacks through the GitHub REST API.
The core magic happens in a multi-step resume extraction pipeline. Users upload a PDF resume; we parse it client-side and use structured data extraction to pull out contact info, work experience, education, skills, and projects. Each project gets a priority score based on its relevance to the job market. Each project gets a priority score based on its relevance to the job market, calculated by combining its market demand, complexity, and how recently it was completed, with each factor weighted by its relative importance, where the weights are tuned to surface your strongest work first.
On the backend, Supabase handles everything: Postgres stores resume sessions, profiles, and job listings; Row-Level Security policies keep each user's data isolated; and Edge Functions (Deno/TypeScript) run the GitHub sync and job aggregation logic securely with service-role credentials.
What We Learned The biggest lesson was that auth is not one-size-fits-all. We started with Supabase Auth, but since the entire value prop is built on GitHub identity, a custom OAuth flow made more sense. The challenge was bridging that custom session securely into Supabase Edge Functions without leaking tokens — we solved it by passing user_id in the request body and verifying it server-side against the profiles table.
We also learned a lot about state synchronization. The priority score editor needs to write to Postgres on every keystroke, but React's useCallback closures can capture stale state values. We fixed this by keeping sessionId in a useRef so the DB update function always reads the current value, not the one from the last render.
Challenges We Faced False session expiry: The job sync edge function originally used supabaseClient.auth.getUser(), but our app uses custom GitHub sessions—not Supabase JWTs. This caused every sync to return "Unauthorized" and the frontend to wrongly log users out. We rewrote the function to validate user_id against the profiles table instead.
PDF parsing reliability: Resumes come in wildly different formats. Getting consistent extraction for multi-column layouts and irregular spacing required iterative prompt tuning.
Real-time DB writes without race conditions: Debouncing priority input while still committing on blur, plus handling async DB errors gracefully, took several iterations to get right.
Built With
- gemini-api
- github-auth
- github-repo-fetch
- react
- serp-api
- supabase
- typescript

Log in or sign up for Devpost to join the conversation.