-
-

Bring light to people
-
UML
-




Inspiration
Visual impairment has been a neglected issue for decades. While there are hardware solutions for the visually impaired, there's a scarcity of software addressing this problem. Research indicates that almost 20 million Americans, which is 8 percent of the U.S. population, have visual impairments.
Now, imagine someone who has lost their vision but refuses to lose their vision for life. We believe that technology can be a potent force for good, breaking down barriers and leveling the playing field for all. Our vision is to harness the power of Computer Vision and machine learning to create picture evaluation software that allows users to perceive the world around them more fully.
What it does
Our groundbreaking project is harnessing the power of AI and computer vision to identify objects in pictures and provide detailed, context-rich descriptions of these objects within their environments. For the blind and visually impaired, this technology is a game-changer since they can simply take a photo, and get an instant evaluation of their surroundings, painting a vivid picture of what's in front of them.
How we built it
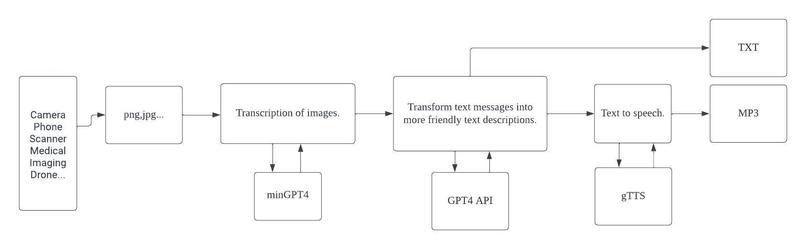
Image Collection: Firstly, an image is captured using devices capable of collecting images, such as digital cameras, smartphones, or scanners.
Preliminary Image Detail Recognition: Once the image is procured, it's imported into miniGPT4. miniGPT4 is a deep learning-based image processing model, proficient at conducting preliminary detail recognition of the image and extracting key features and elements present in it.
Further Textual Description: The initial results recognized by miniGPT4 are then inputted into GPT4. Using the advanced text generation capabilities of GPT4, we produce a more comprehensive and coherent textual description derived from the preliminary image recognition results.
Optimizing Text Description for the Visually Impaired: To ensure maximum understanding for the visually impaired, the description generated by GPT4 is further refined. The focus in this step is to render the textual description more illustrative and detailed, specifically emphasizing visual elements that might not be apparent to the blind audience.
Voice Conversion: Finally, to enable blind individuals to hear the description of the image, we employ the "gtts" (Google Text-to-Speech) technology. This tool transforms the refined text description into a clear voice in MP3 format, allowing the visually impaired to access the information of the image content audibly.
Challenges we ran into
Data Quality: Ensuring the accuracy of image recognition demanded high-quality image inputs. Factors like blurriness, overexposure, or underexposure in images could compromise recognition accuracy.
Model Training: Fine-tuning miniGPT4 and GPT4 for specific data presented challenges, particularly in obtaining sufficient training data and computational resources.
Linguistic Accuracy: When converting image content into textual descriptions and refining them for blind-friendly versions, linguistic accuracy and coherence were paramount. Without these, descriptions could become ambiguous or misleading.
Latency Issues: Ideally, providing real-time feedback for the visually impaired is the aim, but processing and converting images to voice could introduce latency, especially on mobile devices.
Device Compatibility: Ensuring the project functioned seamlessly across a plethora of devices, such as different models of smartphones, tablets, and computers, was a challenge.
User Experience: Designing an intuitive and user-friendly interface was essential, especially considering users who might be less tech-savvy, like elderly visually impaired individuals.
Accomplishments that we're proud of
Innovative Approach: By integrating cutting-edge AI models like miniGPT4 and GPT4 with image recognition and text-to-speech technologies, we've pioneered a comprehensive solution that bridges the visual world with the auditory one for the visually impaired.
Social Impact: This project directly addresses the needs of the visually impaired community, offering them a chance to "see" the world through sound, enhancing their daily experiences and potentially transforming their interactions with their surroundings.
Technical Achievement: Overcoming challenges related to data quality, real-time processing, and ensuring device compatibility showcases our technical expertise and problem-solving capabilities.
User-Centric Design: Our focus on refining descriptions specifically for the visually impaired and ensuring intuitive user interfaces signifies our commitment to delivering a solution tailored for the end-user's needs.
What we learned
Importance of Quality Data: We understood the pivotal role that high-quality image data plays in ensuring accurate AI-driven image recognition and resultant textual descriptions.
Iterative Development: The necessity of continuous testing, feedback, and iterative improvements became evident, ensuring our solution met real-world needs and was user-friendly.
User-Centric Focus: Direct engagement with the visually impaired community may have highlighted the importance of a user-centric approach, understanding their specific challenges, and designing solutions tailored to their needs.
Technical Challenges: We became more adept at troubleshooting and overcoming technical hurdles, be it related to latency issues, device compatibility, or AI model fine-tuning.
Collaboration is Key: Cross-functional collaboration between different expertise areas, like AI, UX design, and hardware integration, is essential for the success of a multifaceted project like this.
Ethical Considerations: Working with personal data, we learned about the ethical implications of our work and the importance of prioritizing data security and user privacy.
Scalability and Flexibility: As we expanded the project, the need for designing solutions that are scalable and adaptable to different languages, devices, and user preferences became clear.
Real-World Testing: The value of field testing and real-world user feedback became evident, as it provided insights that laboratory conditions or simulations couldn't offer.
What's next for SnapRead
User Feedback: Initiate a trial phase with actual users and gather their feedback and suggestions. This will help you understand potential issues in real-world usage and provide solutions.
Model Optimization: Based on user feedback, consider further training and optimizing the miniGPT4 and GPT4 models to enhance the accuracy of image recognition and description generation.
Expand Device Compatibility: If not already covered, consider expanding to other popular mobile devices and operating systems.
Enhance Voice Output: Think about introducing more voice options or utilizing advanced text-to-speech technologies to offer more natural and emotionally rich voice outputs.
Real-time Feedback Mechanism: Develop a system that allows users to provide feedback immediately after hearing a description, aiding quicker system optimization.


Log in or sign up for Devpost to join the conversation.