




Inspiration
People with certain physical disabilities often find themselves at an immediate disadvantage in gaming. There are some amazing people and organizations in the gaming accessibility world that have set out to make that statement less true. People like Bryce Johnson who created the Xbox Adaptive Controller, or everyone from the Special Effect and Able Gamers charities. They use their time and money to create custom controllers that are fit to a specific user with their own unique situation.
Here's an example of those setups:

You can see the custom buttons on the pad and the headrest as well as the custom joysticks. These types of customized controllers using the XAC let the user make the controller work for them. These are absolutely amazing developments in the accessible gaming world, but we can do more.
Games that are fast paced or just challenging in general still leave an uneven playing field for people with disabilities. For example, I can tap a key or click my mouse drastically faster than the person in the example above can reach off the joystick to hit a button on a pad. I have a required range of motion of 2mm where he has a required range of over 12 inches.
I built SuaveKeys to level the playing field, now made even better with more input options via an Android app powered by wit.ai
What it does
SuaveKeys lets you play games and use software with your voice alongside the usual input of keyboard and mouse. It acts as a distributed system to allow users to make use of whatever resources they have to connect. For example, if the user only has an alexa speaker and their computer, they can play using Alexa, but now they can use their Android phone or iPhone using the SuaveKeys mobile app.
Here's what it looks like:
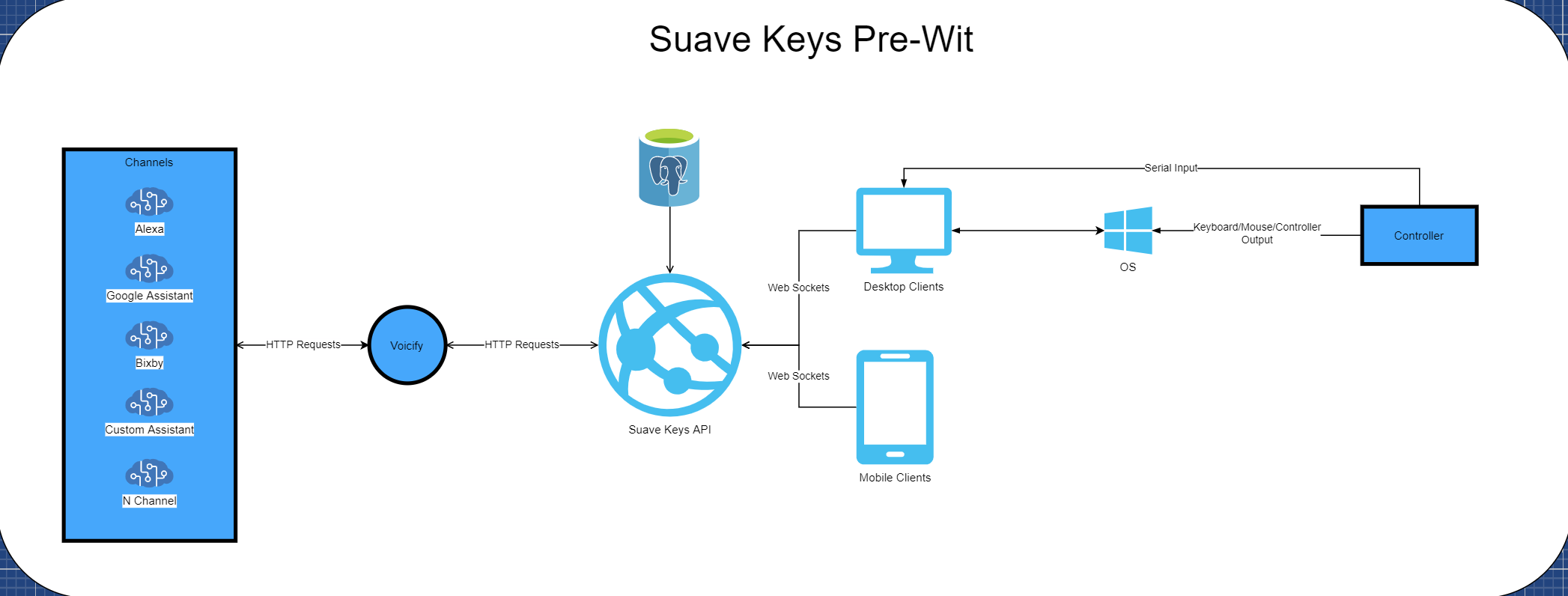
The process is essentially:
- User signs into their smart speaker and client app
- User speaks to the smart speaker
- The request goes to Voicify to add context and routing
- Voicify sends the updated request to the SuaveKeys API
- The SuaveKeys API sends the processed input to the connected Client apps over websockets
- The Client app checks the input phrase against a selected keyboard profile
- The profile matches the phrase to a key or a macro
- The client app then sends the request over a serial data writer to an Arduino Leonardo
- The Arduino then sends USB keyboard commands back to the host computer
- The computer executes the action in game
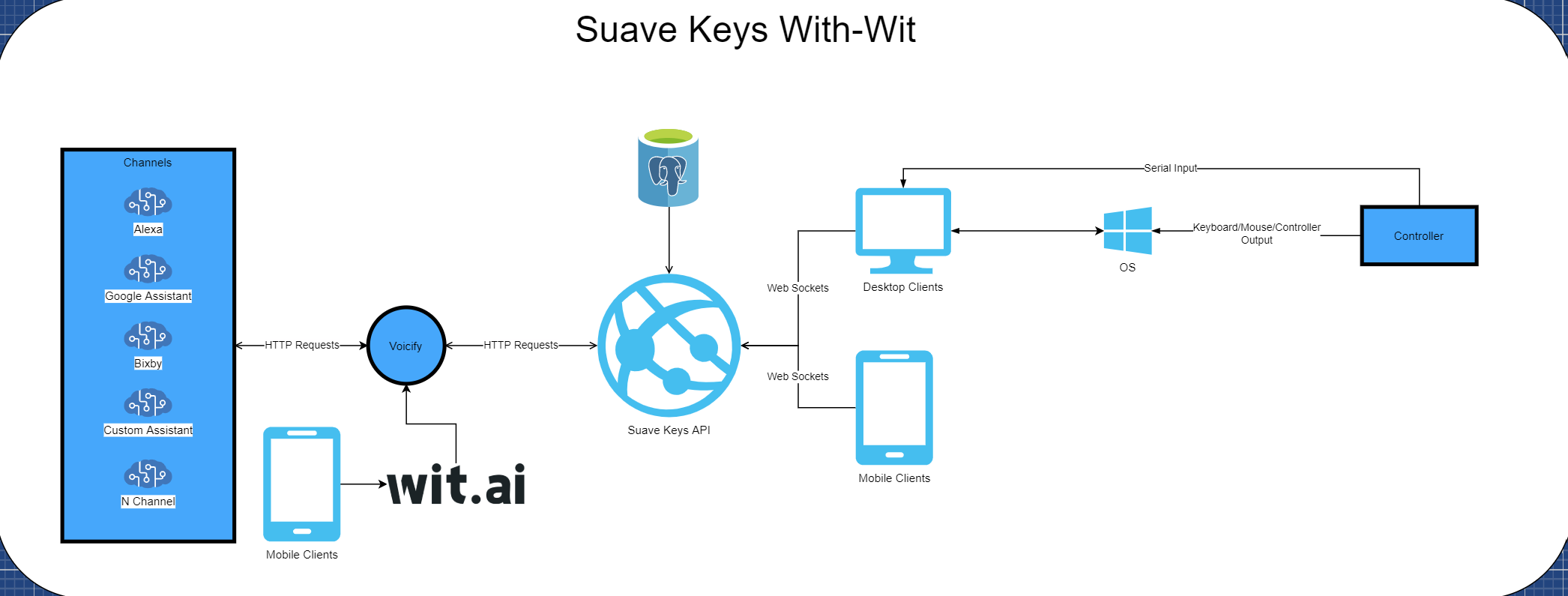
Now with the mobile app and wit.ai, we can use our phone as a new input device which creates a much faster turnaround on the request and enables more users to play games with their voice:
The app also allows the user to customize their profiles from their phone as well as their desktop client. So if you want to quickly create a new command or macro, you can register it right within the app.
Here's a quick gif of it in action in Call of Duty: Modern Warfare where I use my voice to get a headshot. I was able to use my hands to process movement, but all attacking was done with my voice:

If you watch the bottom left, you can see my phone screen where I say "attack" which then triggers the right intent in wit.ai, and then sends it to Voicify, to the SuaveKeys API, to my desktop, to Arduino, and actually fires the gun in the game to get a headshot.
Here's an example of a Fall Guys profile of commands - select a key, give a list of commands, and when you speak them, it works!
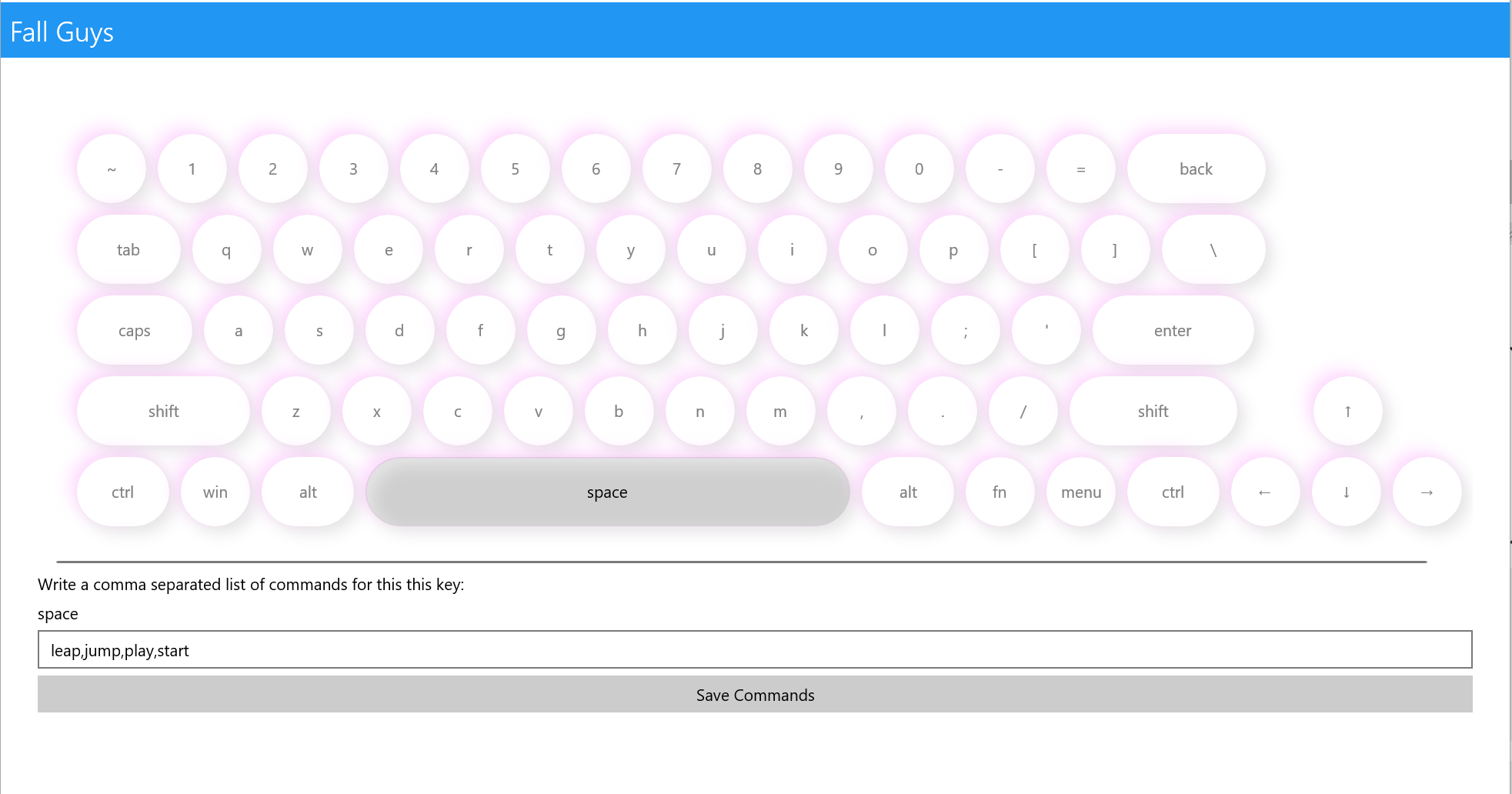
You can also add macros to a profile:

How I built it
The SuaveKeys Mobile app is built using C#, .NET, and Xamarin with the help of wit.ai, SignalR, and a whole lot of abstraction and dependency injection.
While the SuaveKeys API and Authentication layers already existed, we were able to build the client apps to act as both ends of the equation.
Each page in the app is built using XAML, C#, and MVVM. To handle differences in platforms such as:
- Speech to text providers
- UI differences
- Changes in business logic
I built a dependency abstraction that lets us create an interface in the shared code, an implementation of that interface separately in each platform project, then inject it back into shared code.
For example, our ViewModel that handles the Speech to text flow that lets us actually talk to our app and have it work looks like this:
public class MicrophonePageViewModel : BaseViewModel
{
private readonly ISpeechToTextService _speechToTextService;
private readonly IKeyboardService _keyboardService;
public ICommand StartCommand { get; set; }
public ICommand StopCommand { get; set; }
public bool IsListening { get; set; }
public MicrophonePageViewModel()
{
_speechToTextService = App.Current.Container.Resolve<ISpeechToTextService>();
_keyboardService = App.Current.Container.Resolve<IKeyboardService>();
_speechToTextService.OnSpeechRecognized += SpeechToTextService_OnSpeechRecognized;
StartCommand = new Command(async () =>
{
await _speechToTextService?.InitializeAsync();
await _speechToTextService?.StartAsync();
IsListening = true;
});
StopCommand = new Command(() =>
{
IsListening = false;
});
}
private async void SpeechToTextService_OnSpeechRecognized(object sender, Models.SpeechRecognizedEventArgs e)
{
_keyboardService?.Press(e.Speech);
if (IsListening)
await _speechToTextService?.StartAsync();
}
}
This means, we need to implement and inject our IKeyboardService and our ISpeechToTextService. So to let Android actually use the built-in SpeechRecognizer activity and pass it to wit.ai then voicify, we implement it like this:
public class AndroidSpeechToTextService : ISpeechToTextService
{
private readonly MainActivity _context;
private readonly ILanguageService _languageService;
private readonly ICustomAssistantApi _customAssistantApi;
private readonly IAuthService _authService;
private string sessionId;
public event EventHandler<SpeechRecognizedEventArgs> OnSpeechRecognized;
public AndroidSpeechToTextService(MainActivity context,
ILanguageService languageService,
ICustomAssistantApi customAssistantApi,
IAuthService authService)
{
_context = context;
_languageService = languageService;
_customAssistantApi = customAssistantApi;
_authService = authService;
_context.OnSpeechRecognized += Context_OnSpeechRecognized;
}
private async void Context_OnSpeechRecognized(object sender, SpeechRecognizedEventArgs e)
{
var languageResult = await _languageService.ProcessLanguage(e.Speech).ConfigureAwait(false);
var updatedSlots = languageResult.Data.Slots.ToDictionary(s => GetVoicifySlotName(languageResult.Data.Name, s.Name), s => s.Value);
var tokenResult = await _authService.GetCurrentAccessToken();
updatedSlots.Add("AccessToken", tokenResult?.Data);
var voicifyResponse = await _customAssistantApi.HandleRequestAsync(VoicifyKeys.ApplicationId, VoicifyKeys.ApplicationSecret, new CustomAssistantRequestBody(
requestId: Guid.NewGuid().ToString(),
context: new CustomAssistantRequestContext(sessionId,
noTracking: false,
requestType: "IntentRequest",
requestName: languageResult.Data.Name,
slots: updatedSlots,
originalInput: e.Speech,
channel: "Android App",
requiresLanguageUnderstanding: false,
locale: "en-us"),
new CustomAssistantDevice(Guid.NewGuid().ToString(), "Android Device"),
new CustomAssistantUser(sessionId, "Android User")
));
OnSpeechRecognized?.Invoke(this, e);
}
private string GetVoicifySlotName(string intentName, string nativeSlotName)
{
if (intentName == "PressKeyIntent" && nativeSlotName == "wit$search_query")
return "key";
if (intentName == "TypeIntent" && nativeSlotName == "wit$search_query")
return "phrase";
if (intentName == "VoicifyLatestMessageIntent" && nativeSlotName == "wit$search_query")
return "category";
return "query";
}
public Task InitializeAsync()
{
sessionId = Guid.NewGuid().ToString();
// we don't need to init.
return Task.CompletedTask;
}
public Task StartAsync()
{
var voiceIntent = new Android.Content.Intent(RecognizerIntent.ActionRecognizeSpeech);
voiceIntent.PutExtra(RecognizerIntent.ExtraLanguageModel, RecognizerIntent.LanguageModelFreeForm);
voiceIntent.PutExtra(RecognizerIntent.ExtraSpeechInputCompleteSilenceLengthMillis, 1500);
voiceIntent.PutExtra(RecognizerIntent.ExtraSpeechInputPossiblyCompleteSilenceLengthMillis, 1500);
voiceIntent.PutExtra(RecognizerIntent.ExtraSpeechInputMinimumLengthMillis, 15000);
voiceIntent.PutExtra(RecognizerIntent.ExtraMaxResults, 1);
voiceIntent.PutExtra(RecognizerIntent.ExtraLanguage, Java.Util.Locale.Default);
_context.StartActivityForResult(voiceIntent, MainActivity.VOICE_RESULT);
return Task.CompletedTask;
}
}
The gist of it is kicking off the speech recognition, then when we process the speech, send it to our ILanguageService (this is where we implement the wit.ai call), then fire that processed data off to the voicify ICustomAssistantApi.
Here's the gist of the WitLanguageService that is then injected into our android service:
public class WitLanguageUnderstandingService : ILanguageService
{
private readonly HttpClient _client;
public WitLanguageUnderstandingService(HttpClient client)
{
_client = client;
}
public async Task<Result<Intent>> ProcessLanguage(string input)
{
try
{
if (_client.DefaultRequestHeaders.Contains("Authorization"))
_client.DefaultRequestHeaders.Remove("Authorization");
_client.DefaultRequestHeaders.Add("Authorization", $"Bearer {WitKeys.WitAccessKey}");
var result = await _client.GetAsync($"https://api.wit.ai/message?v=1&q={HttpUtility.UrlEncode(input)}");
if (!result.IsSuccessStatusCode)
return new InvalidResult<Intent>("Unable to handle request/response from wit.ai");
var json = await result.Content.ReadAsStringAsync();
var witResponse = JsonConvert.DeserializeObject<WitLanguageResponse>(json);
// map to intent
var model = new Intent
{
Name = witResponse.Intents.FirstOrDefault()?.Name,
Slots = witResponse.Entities.Select(kvp => new Slot
{
Name = kvp.Value.FirstOrDefault()?.Name,
SlotType = kvp.Value.FirstOrDefault()?.Type,
Value = kvp.Value.FirstOrDefault()?.Value
}).ToArray()
};
return new SuccessResult<Intent>(model);
}
catch (Exception ex)
{
Console.WriteLine(ex);
return new UnexpectedResult<Intent>();
}
}
}
Here, we send the request off to our wit app, then take the output and map it to an simplified model that we can send to the Voicify app.
So all-in-all the flow of data/logic is:
- User signs in
- User goes to microphone page
- User taps "start"
- User speaks
- Android STT service listens and processes text
- Android STT service takes output text and sends to wit for alignment
- Android STT takes aligned NL and sends it to Voicify
- Voicify processes the aligned NL against the built app
- Voicify sends request to SuaveKeys API webhook
- SuaveKeys API sends websocket request to any connected client (UWP app)
- UWP app takes request and sends it to Arduino
- Arduino sends USB data for keyboard input
- BOOM HEADSHOT (or whatever other action should happen in the game)
Challenges I ran into
The biggest challenges are performance from request to game, and testing while also talking to my chat on stream! Since the whole thing was built live on my twitch channel, I'm always talking to chat about my thought process, what I'm doing, and answering questions. So trying to keep that interactivity while also testing something that requires me to speak to it can be messy. This led to a TON of weird utterances added in my wit app to either ignore or align which just made more work, but outside of that, everything was pretty straight forward.
For example:
With regards to performance, I'm exploring a couple things including:
- Balancing the process timing while speaking
- Running intermittent spoken word against wit to see if it is valid ahead of time
Accomplishments that I'm proud of
The biggest accomplishment was being able to see it in use! I was able to play games like Call of Duty, Sekiro, and Fall Guys using my voice! It feels like it's closer to a real option for people with disabilities to play competitive, fast paced, and difficult games with as much ease as able-bodied people do and really level the playing field.
What I learned
The biggest learning moment was honestly how easy it was to integrate wit.ai - I had already created a basic language model via Voicify to use on the other supported platforms like Alexa and Dialogflow. Getting that working in wit was unbelievably easy. So many NLU tools overcomplicate the tooling and creation, but I was shocked that I was able to just spin up a wit app, add and align utterances, and just get going.
What's next for Suave Keys
Tons of stuff! I'm working on Suave Keys at least twice a week from now on stream and have tons of new stuff lined up including:
- Making the UI a WHOLE lot cleaner and easier to use
- Working on performance (as mentioned in my challenges faced)
- Enabling more platforms to help more people use it
- Distributing hardware creation to let people actually use it
- Adding more device support for the XAC
- Building shareable game profiles
Conclusion
I think Suave Keys has the chance to enable so many more people to play games that they never could before, and with a mobile app



Log in or sign up for Devpost to join the conversation.