Inspiration
The inspiration for this project originated from a common experience of mine. Oftentimes, my teachers or peer would mistake me for a friend of mine who is also east Asian or vice versa. This prompted me to question whether this phenomenon is distinct to humans or are other things, such as software also prone to such tendencies. This led me to investigate how much bias there is in facial recognition software.
What it does
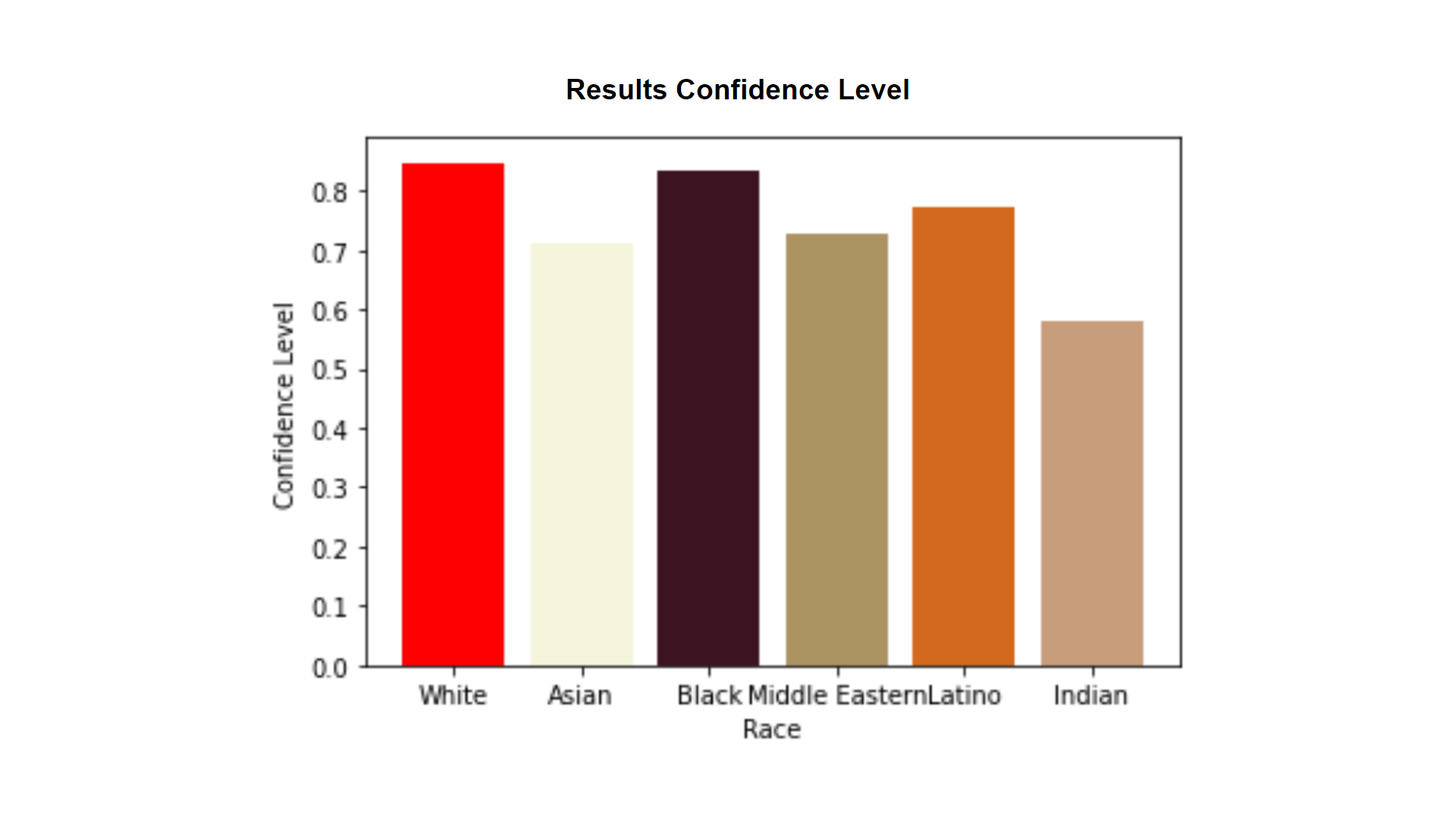
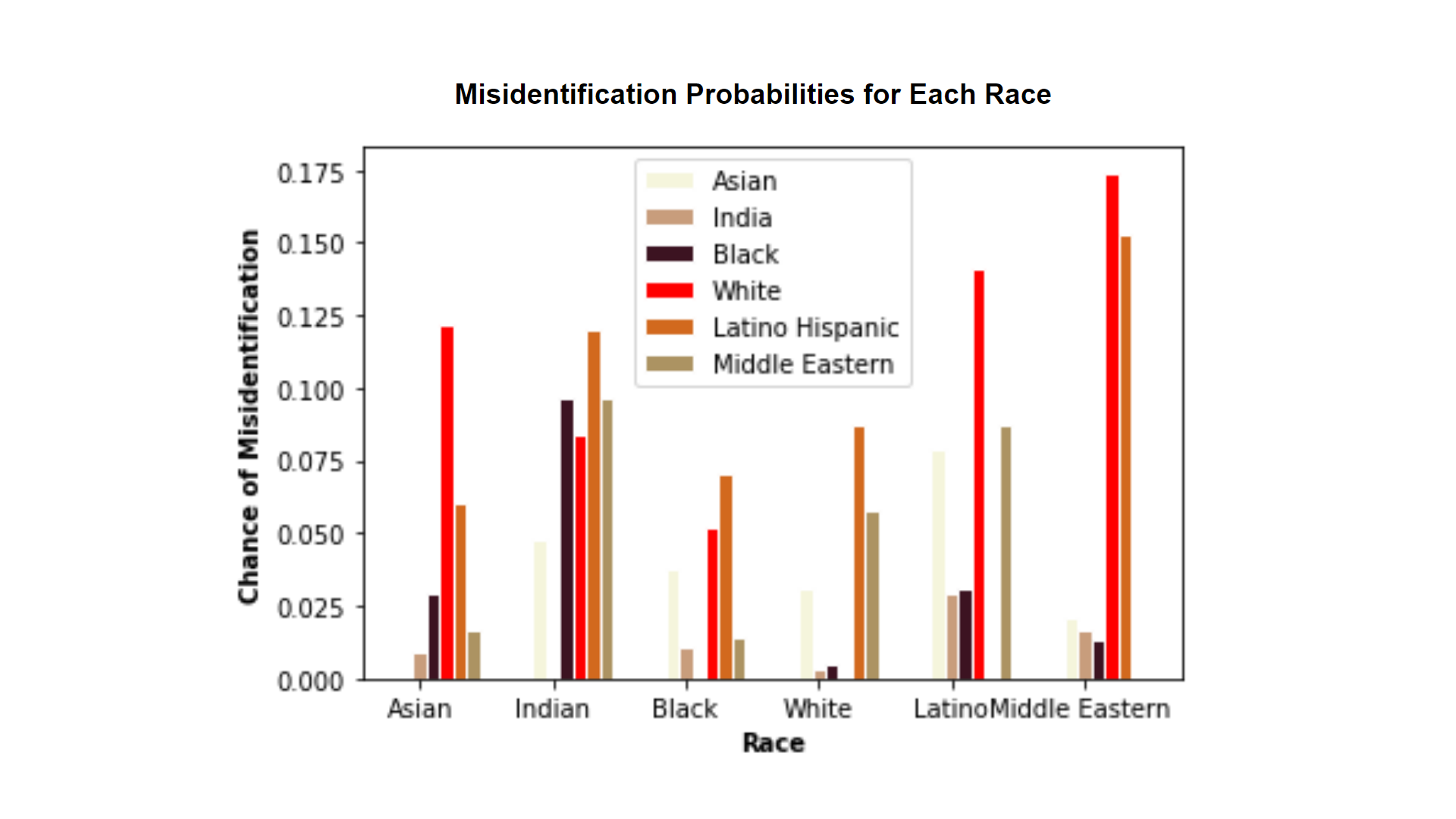
my visualizations point out specific biases in DeepFace facial recognition software, and my data is newly generated from datasets of images so no one has seen them before.
How we built it
Challenges we ran into
I had originally planned to compare the accuracy of one-to-one image matching for the different races using an open-source facial recognition software -- deepFace. However, I could not find a dataset readily available that would allow me to test that (i.e. both have race labeled for each image and have multiple images per individual).
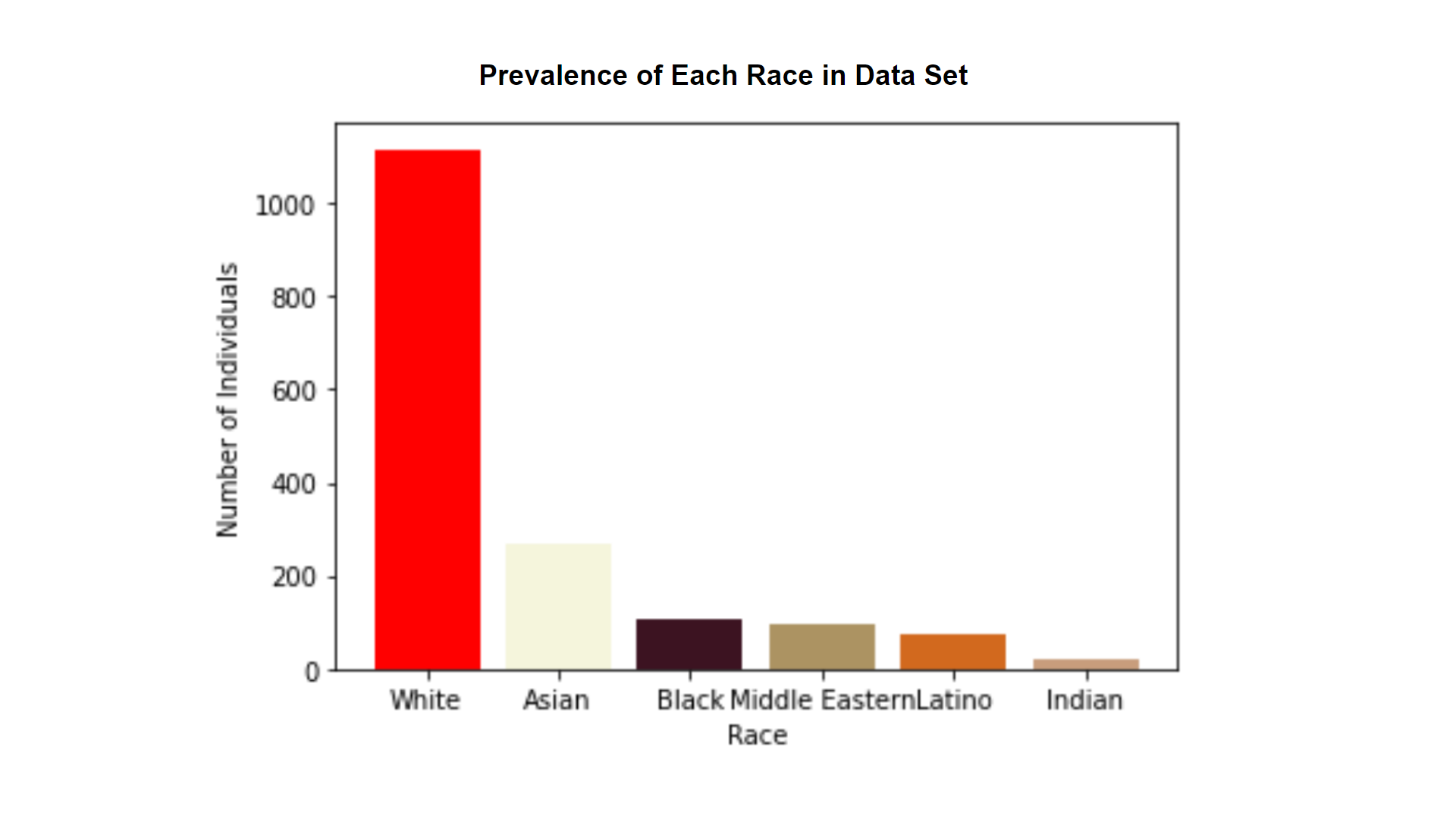
I was unable to find a downloadable dataset of their study results so I had to generate my own. In order to attack this problem, I had to go about it in a roundabout way. I was able to find a set of data created by the LFW organization that consists of 9162 images of approximately 1,600 individuals. Unfortunately, this data set does not include labels about the person’s race. Thus, I decided to run all the images through a race detection in DeepFace with the intention of then matching the images - now identified with race, and find the accuracy. However, due to time constraints, I was only able to finish the racial recognition portion. Even so, I had plenty of data to analyze.

Log in or sign up for Devpost to join the conversation.