-
-
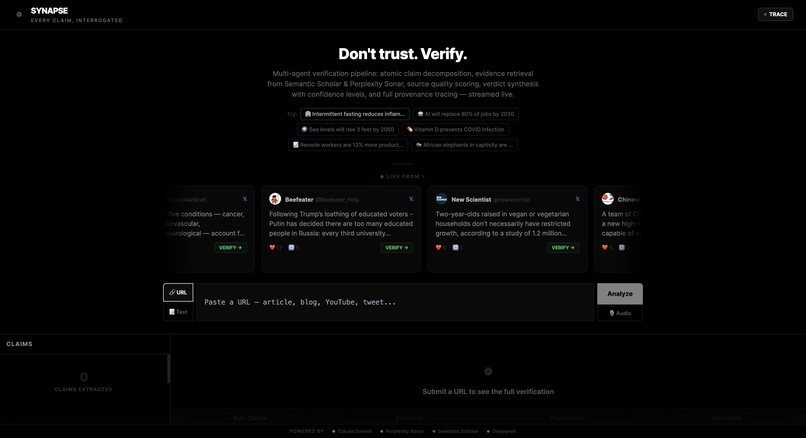
Landing Page + URL/File Ingestion (Perplexity Sonar)
-
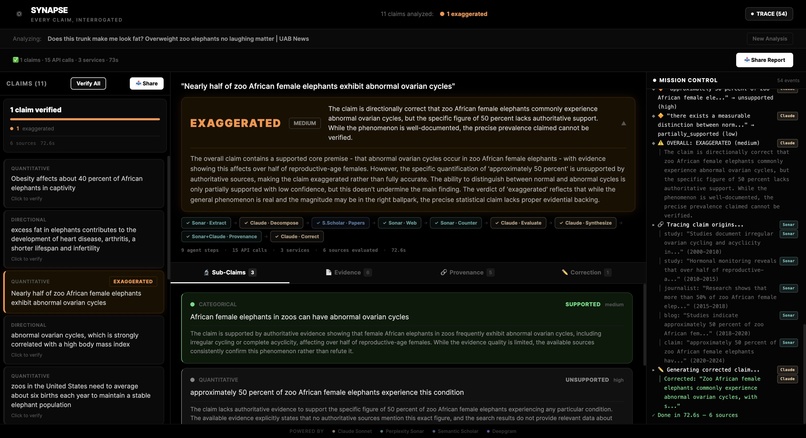
Initial Subclaim Division + Assumption Breakdown (Claude)
-
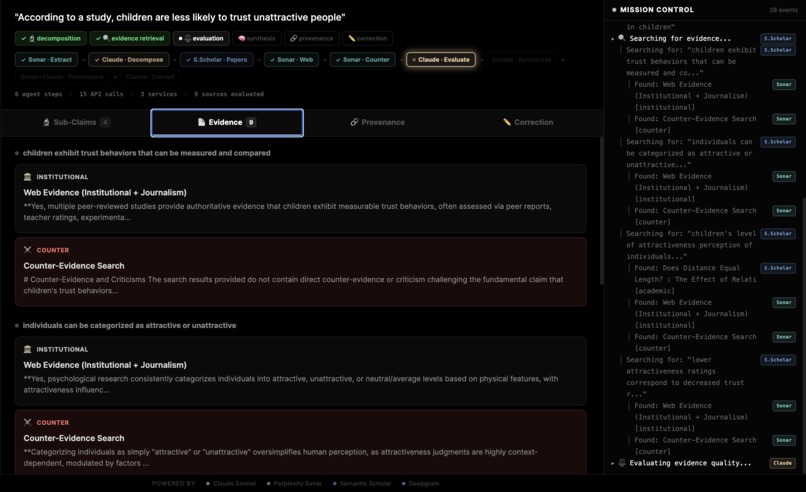
Evidence and Counter-evidence Analysis (Perplexity Sonar + Semantic Scholar)
-
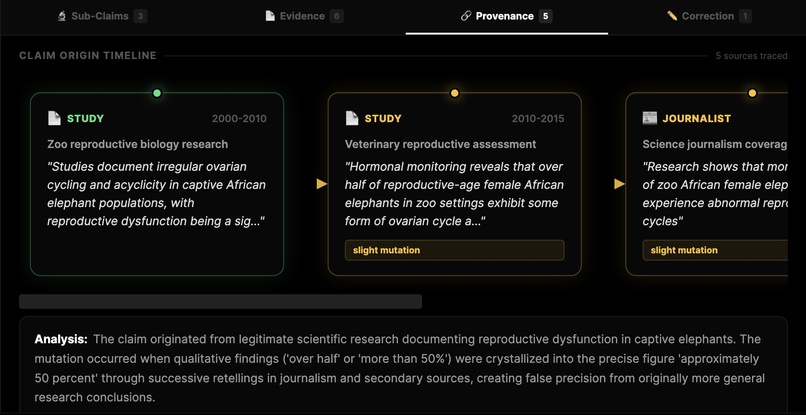
Timeline + Provenance/Origin of the Concept, with Mutations over time (Claude)
-

Corrected Precise Statement + Report + Sharing



Synapse — Every claim, interrogated
Synapse is a claim-level intelligence engine that takes any piece of content — a URL, pasted text, or audio — extracts every factual claim, and runs deep multi-step agent-driven verification on each one. It doesn't just tell you "true or false." It shows you the full forensic breakdown: where the evidence comes from, how strong it is, where the claim originated, and how it mutated as it spread.
The verification process itself is the product. The user watches the agent think, search, evaluate, and reason in real time. Every step is visible. The reasoning IS the interface.
Inspiration
Our team kept running into the same problem in our everyday lives: you read some sort of article, watch some sort of video, hear some sort of podcast, and someone, somewhere, makes a bold claim, and you have no idea if it's actually true. Maybe it was debunked five years ago. Maybe the original study was never replicated. Maybe the citation chain is just a game of telephone where everyone cites the same flawed source.
Existing tools don't solve this well. NotebookLM works at the document level, ChatGPT at the conversation level, Perplexity at the query level. But misinformation doesn't live at any of those levels. It lives at the claim level. For instance, a single article might have ten claims, eight of which are solid and two of which are zombie ideas that were refuted years ago. Yet no tool lets you see that.
We realized that if you make the claim the atomic unit of analysis, the way Git made the commit the atomic unit of code, entirely new operations become possible. You can trace lineage, score confidence, identify orphan ideas nobody followed up on, and actually see whether a citation supports a claim or just mentions it. And that's what we built.
What it does
Synapse takes any piece of content (e.g., article, podcast, video) and breaks it down into its core claims. For each claim, it:
[1] Decomposes assumptions. Every claim has subclaims and assumptions baked into it. Synapse uses recursive claim decomposition to surface these layers so you can see what's actually being asserted beneath the surface.
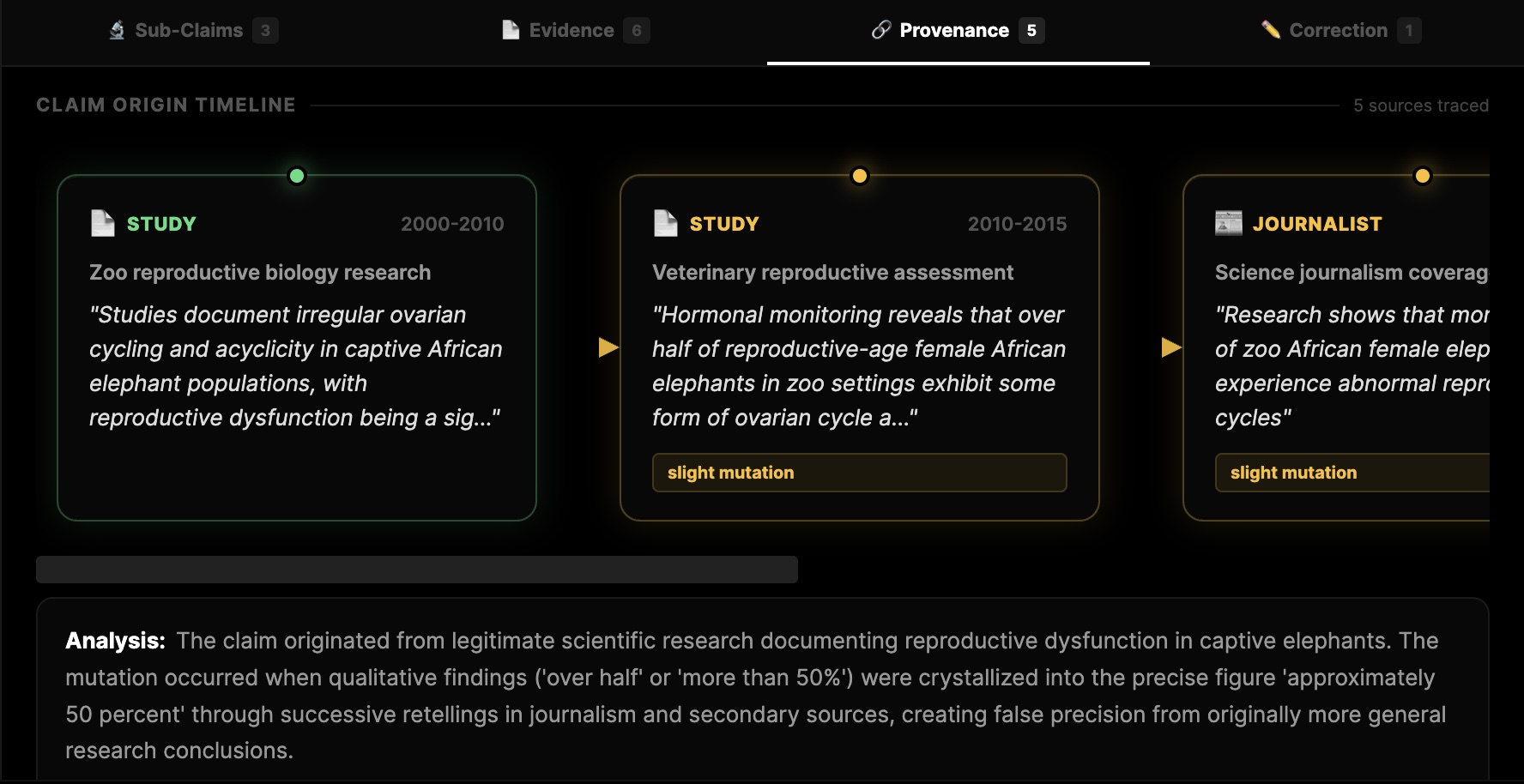
[2] Traces provenance. It follows the citation chain backward (not just "what papers are cited") and finds where the idea originally came from, who replicated it, who challenged it, and where consensus currently sits. You get a full temporal lineage graph of how a piece of knowledge evolved.
[3] Verifies against evidence. Each subclaim gets scored against real evidence through our multi-model verification loop. Synapse tells you whether the evidence supports, opposes, or is inconclusive on each point and shows you exactly what that evidence is.
[4] Corrects with nuance. Rather than just saying "true" or "false," Synapse generates a corrected version of each claim that reflects what the evidence actually shows.
All in all, we turn any article from something you consume (passively) into something you can interrogate (actively).
How we built it
We built Synapse using a multi-agent orchestration architecture with specialized autonomous agents, each responsible for a distinct phase of the verification pipeline. The system runs asynchronous, tool-based model calls across multiple AI providers.
Claim Extraction & Decomposition Pipeline. When an article/podcast/piece of content comes in, we use Perplexity's Sonar API integrated with a Firecrawl Extract pipeline to pull and parse the full content. We then pass the extracted text through Claude 4.6 Opus for initial claim identification; we also use structured output schemas to produce a normalized claim graph. Each top-level claim gets recursively decomposed into atomic subclaims using a custom decomposition agent built on GPT-5.2 with tool-calling capabilities, and this agent runs nested Perplexity searches to gather contextual information needed to identify implicit assumptions that wouldn't be obvious from the text alone.
Evidence Retrieval & Verification Loop. This is the core of Synapse. We run an iterative reasoning loop pairing Perplexity's search capabilities with Claude's extended thinking for deep analytical reasoning. For each subclaim, a Retrieval Agent dispatches parallel searches across Perplexity, Brave Search API, and Semantic Scholar's academic database. The retrieved evidence gets embedded using sentence-transformers and stored in a pgvector-backed Supabase instance for semantic similarity matching against the claim embeddings. Claude then reasons over the retrieved evidence set and evaluates support, opposition, and relevance and generates follow-up search queries for gaps it identifies. Based on Claude's reasoning output, Perplexity runs another round of targeted searches. This loop continues with tuned termination conditions (we use a confidence convergence threshold plus a max-iteration cap) to ensure evidence is genuinely sufficient without wasting API calls.
Provenance Tracking & Citation Chain Analysis. For provenance, we deploy a dedicated Citation Tracing Agent that recursively follows reference chains using Perplexity's nested search capabilities, Firecrawl for scraping reference lists from academic and journalistic sources, and BeautifulSoup for structured HTML parsing. Each citation gets classified using a fine-tuned classifier into three categories: supporting (the cited work genuinely backs the claim), tangential (the cited work merely mentions the topic), or contradicting (the cited work actually undermines the claim). We build a directed acyclic graph of the citation lineage and render it as a temporal provenance timeline from the original proposal through replications, challenges, and meta-analyses.
Challenges we ran into (and solved!)
[1] The biggest challenge was the reasoning loop between Claude and Perplexity. Getting two AI systems to collaborate effectively (where one searches and the other reasons about what to search next) required us to carefully orchestrate everything. We implemented a convergence-based termination strategy: the loop exits when the confidence delta between iterations drops below a threshold, and we also implemented a hard iteration cap to prevent runaway API costs.
[2] Claim decomposition was harder than expected. Natural language is messy, and a single sentence can contain multiple nested claims with shared assumptions. We iterated heavily on the decomposition agent's prompting strategy and added a validation step where decomposed subclaims get checked for atomic verifiability before entering the evidence pipeline.
[3] Citation quality classification was another challenge. Just because an article or podcast cites a paper doesn't mean the paper supports the article's claim. Building the logic to distinguish between supporting, tangential, and contradicting citations required training a lightweight classifier on labeled examples and cross-validating with Claude's reasoning outputs.
[4] Managing concurrent agent execution across multiple API providers (Perplexity, Claude, OpenAI, Brave) while maintaining data consistency and avoiding race conditions in the shared evidence store required significant infrastructure work with Redis-based locking and careful async pipeline design.
Accomplishments that we're proud of
[1] We're proud that the system actually catches things humans miss. It sounds totally plausible that captive elephants are becoming overweight, but when you trace the evidence, it's far less conclusive than the article implies. Synapse catches that nuance automatically.
[2] We believe our provenance tracking feels novel. Being able to click on any claim and see its full genealogy – who proposed it, who tested it, who challenged it – rendered as a temporal citation graph is something we haven't seen at this granularity before.
[3] The multi-model orchestration architecture itself is something we're proud of. Getting Claude, Perplexity, GPT, and multiple retrieval systems to work together in a coherent async pipeline (each handling what it's best at) was a serious engineering challenge that paid off.
[4] We also think the claim-level abstraction itself is an important contribution. It opens up operations like identifying zombie claims and orphan ideas that simply aren't possible when you're working at the document or query level.
What we learned
[1] Working at the claim level is both more powerful and more difficult than we anticipated. Claims are slippery (they blend into each other, they have implicit assumptions, and verifying them requires understanding context that isn't always explicit). But when you get the decomposition right, the downstream analysis becomes remarkably clear.
[2] We learned that the iterative loop architecture (e.g., pairing a search model with a reasoning model in a convergence-based cycle) is incredibly effective for verification tasks.
[3] Embedding-based evidence matching turned out to be far more nuanced than we expected. Naive semantic similarity between a claim and a piece of evidence often produces false positives. There are passages that are topically related but don't actually speak to the truth of the claim. We had to layer citation classification on top of vector similarity and weight by source reliability and recency to get scoring that actually reflects evidential strength rather than just semantic proximity.
What's next for Synapse
We're hoping to build a browser extension that lets you highlight any claim on any webpage and get an instant provenance trace and confidence score, powered by a lightweight edge-deployed version of our verification loop. Longer term, we want to build a persistent knowledge graph where verified claims accumulate over time in our vector store; this would enable cross-article claim deduplication and a continuously improving evidence base that makes every subsequent verification faster and more accurate.
How It Works
1. Ingest Anything
Paste a URL (article, blog, YouTube), raw text, or upload audio/video. Synapse extracts clean text and feeds it to the claim extraction pipeline.
2. Claim Extraction
An LLM identifies every discrete, verifiable factual claim — skipping opinions, rhetoric, and subjective statements. Each claim is tagged by type (quantitative, directional, categorical, provenance).
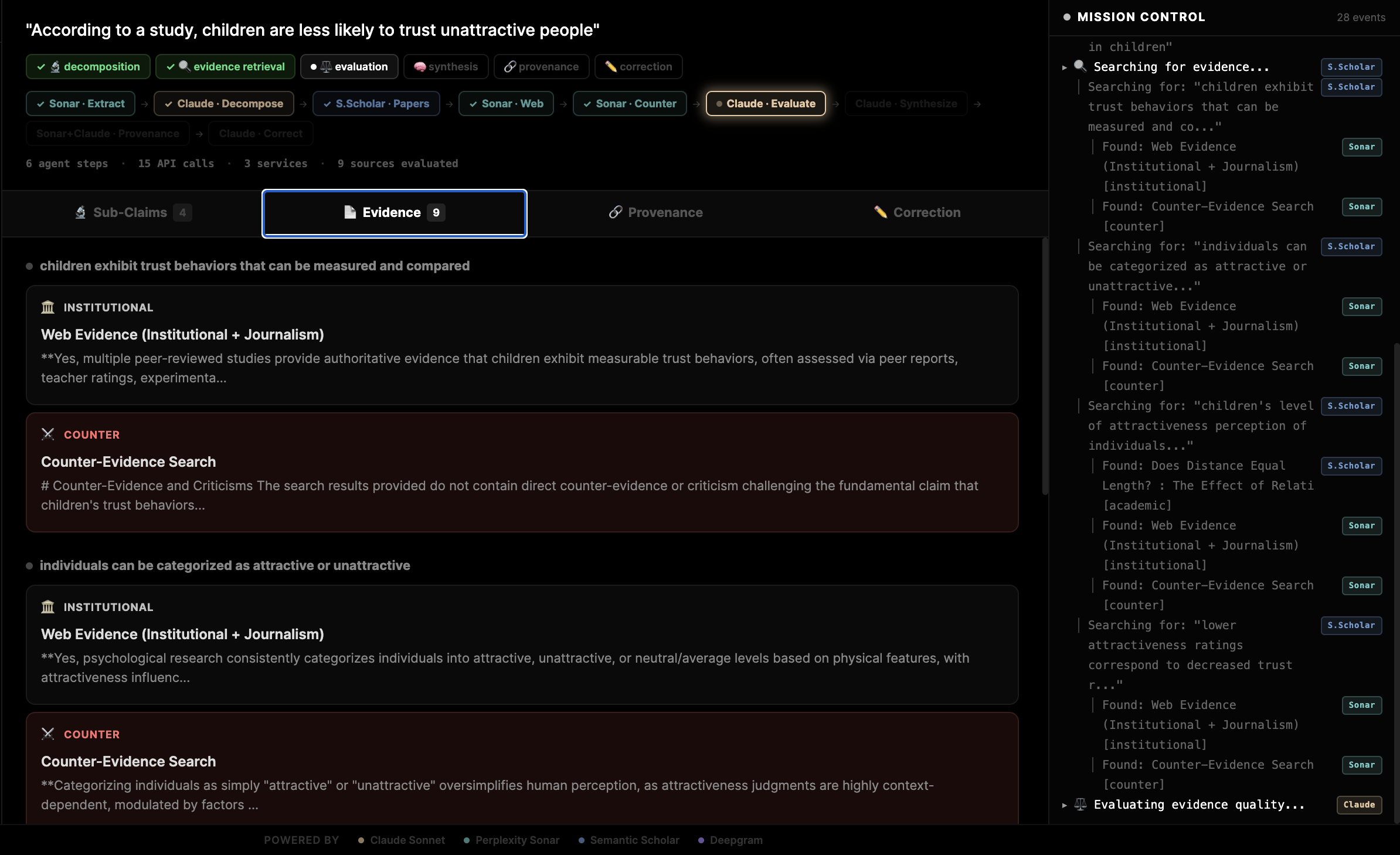
3. 6-Step Verification Pipeline
Each claim runs through a multi-agent pipeline, streamed to the UI in real time via SSE:
- Step 1 — Decomposition: Break compound claims into atomic, independently verifiable sub-claims
- Step 2 — Multi-Source Evidence Retrieval: Parallel search across Semantic Scholar (academic papers), Perplexity Sonar (institutional + journalism), and deliberate counter-evidence search
- Step 3 — Evidence Quality Evaluation: Score each source (0-100) based on study type, recency, citation count, and source authority
- Step 4 — Verdict Synthesis: Per-sub-claim verdicts (Supported / Exaggerated / Contradicted / Unsupported) rolled up into an overall verdict with confidence level
- Step 5 — Provenance Tracing: Trace the claim's likely origin and mutation path — from original study to the version being checked
- Step 6 — Corrected Claim: Generate an evidence-backed corrected version, a steel-manned version, and key caveats
4. Live Agent Reasoning Trace
A terminal-style trace panel shows every step the agent takes in real time — searches fired, evidence found, scores assigned, verdicts reached.
Built With
- anthropic-claude-api
- css
- deepgram-api
- fastapi
- html
- httpx
- networkx
- perplexity-sonar-api
- pydantic
- python
- railway
- react
- react-router-dom
- semantic-sonar-api
- typescript
- vercel
- vite
- x-api-v2



Log in or sign up for Devpost to join the conversation.