Inspiration
Training machine learning models is often a messy, manual process. Data scientists and ML engineers frequently find themselves managing individual Python scripts, SSHing into remote servers, and crossing their fingers that a crash doesn't wipe out hours of training. We wanted to bridge the gap between Data Science and robust DevOps. The inspiration for AMLED was to treat ML training workloads like highly available, fault-tolerant microservices—making them observable, resilient, and easy to orchestrate.
What it does
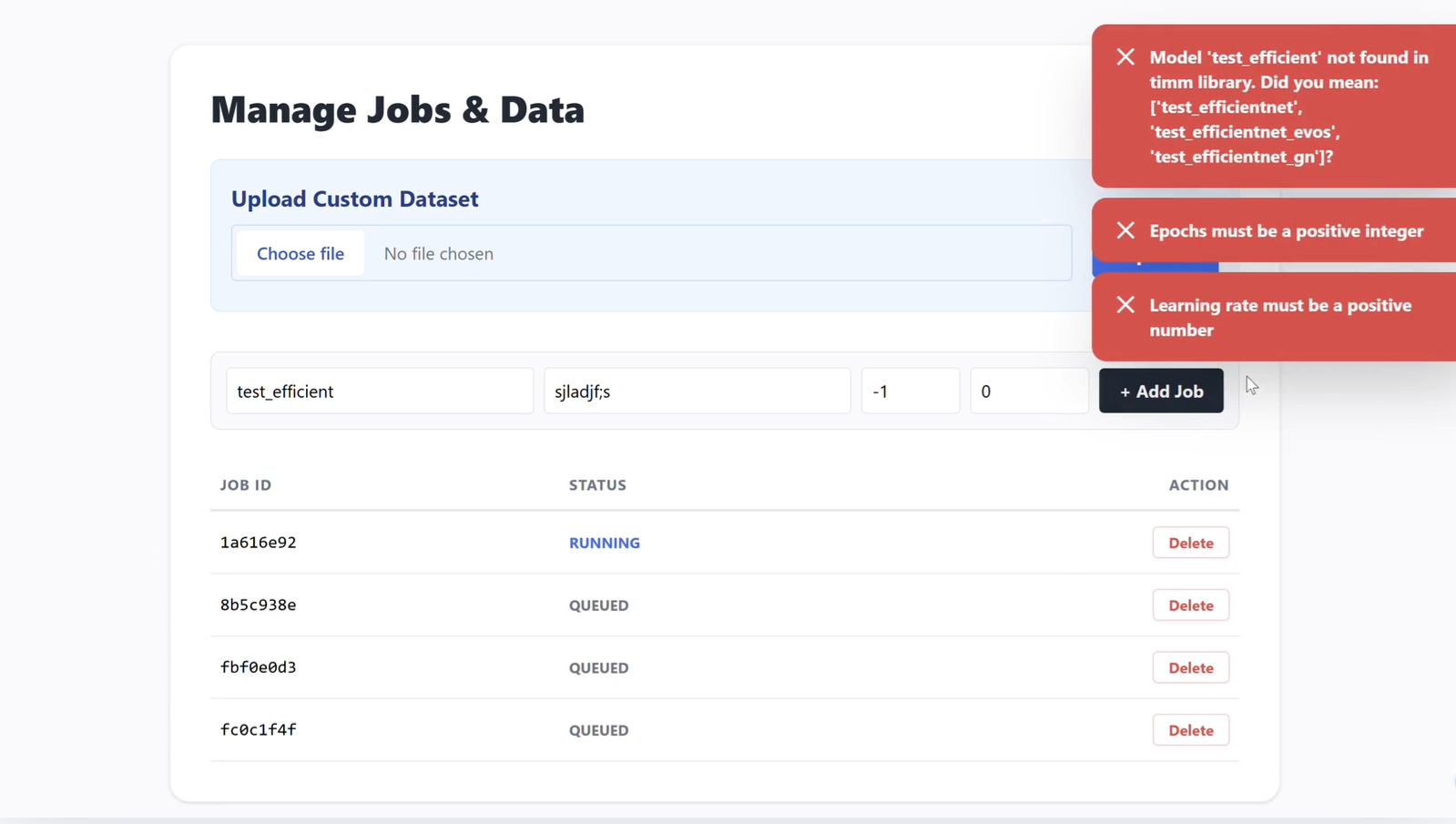
AMLED is a distributed orchestrator for ML model training jobs. Through a clean, reactive web UI, users can configure and dispatch deep learning tasks (selecting models from the timm library, setting epochs, learning rates, etc.).
Instead of running a blocking script, the backend queues the job, provisions worker containers to train the model, and tracks real-time execution metrics like epoch progress and loss. If a worker process fails or a node goes down, the system is designed to handle the fault gracefully. We even built an experimental LLM-based worker (fixworker.py) that uses the Groq API to analyze and auto-fix certain code failures on the fly.
How we built it
We focused on a lightweight but highly scalable stack:
- Backend: FastAPI handles our API routing and orchestration, backed by an SQLite database for persistent job state management.
- Frontend: A responsive, real-time dashboard built entirely with petite-vue and Tailwind CSS, served directly from the Python backend to keep the architecture simple but modern.
- ML Workers: PyTorch handles the heavy lifting, utilizing the timm library for loading state-of-the-art vision models.
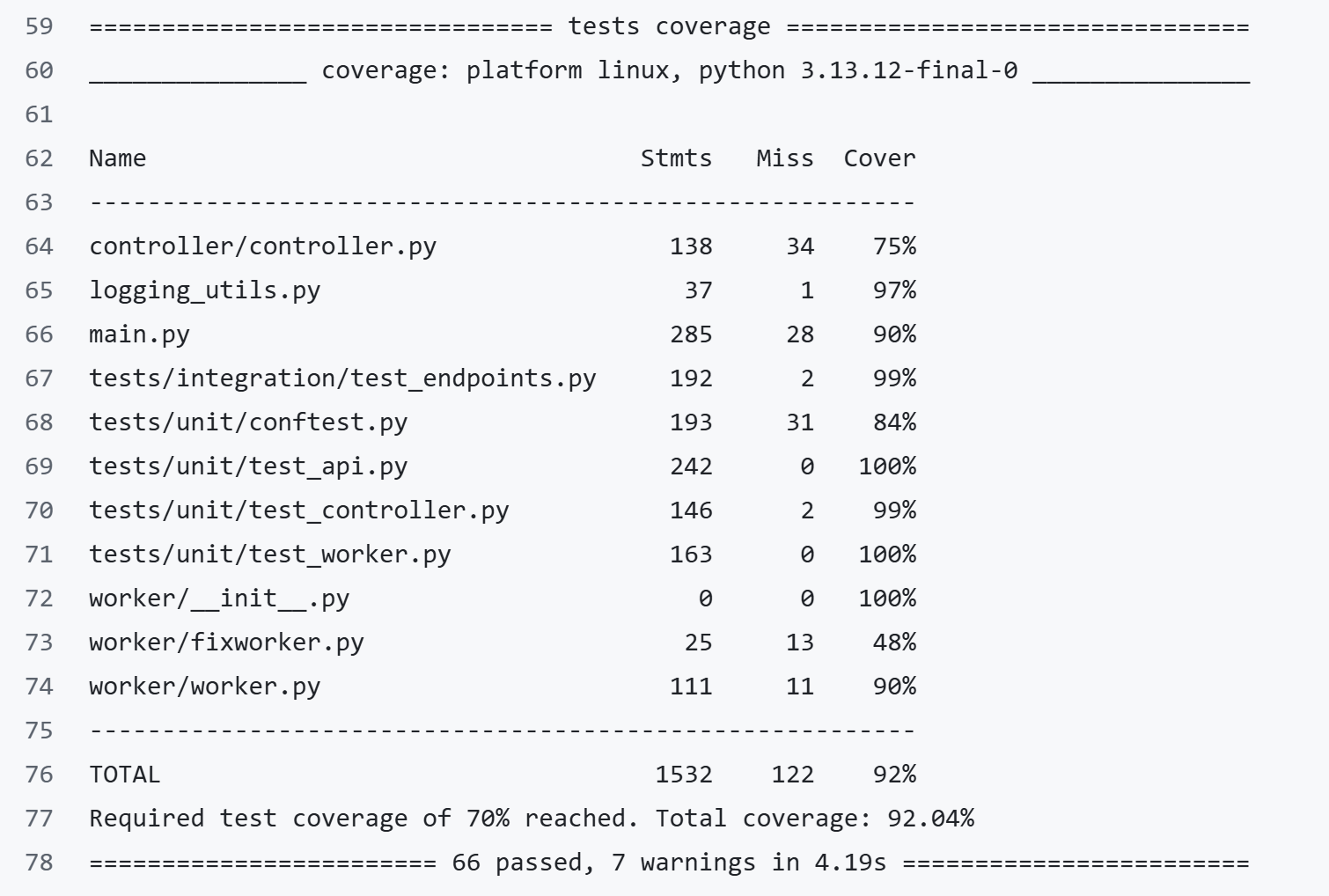
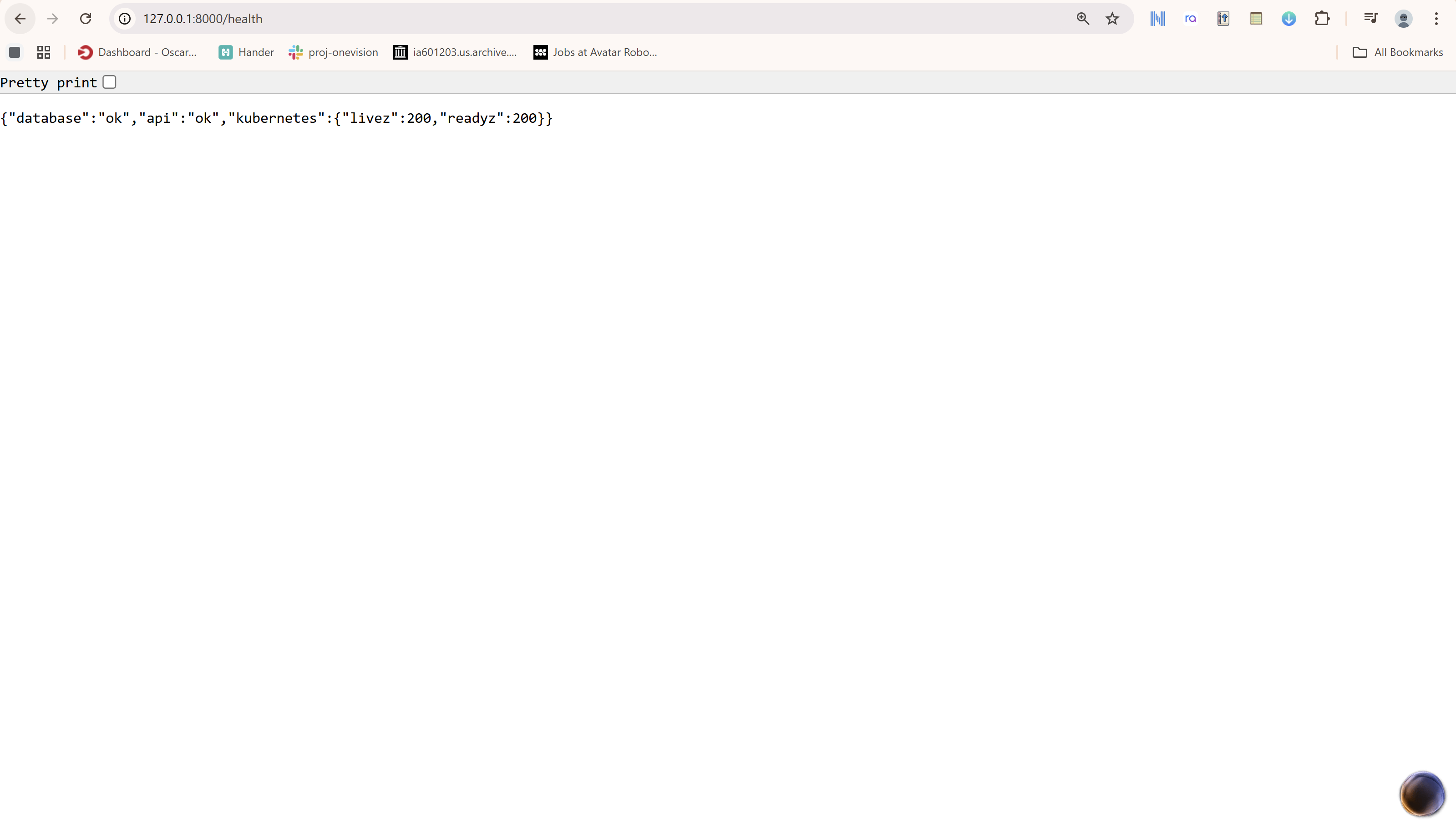
- Infrastructure: Docker and Kubernetes. We rely on container restart policies and K8s health checks (/livez, /readyz) to manage the lifecycle of our training pods. We also set up a rigorous CI/CD pipeline using GitHub Actions and Pytest to ensure reliability.
Challenges we ran into
One of the most frustrating early bugs was our PyTorch DataLoader crashing silently inside Docker. We discovered this was due to Docker's default /dev/shm (shared memory) limits choking PyTorch's multi-processing capabilities. We had to specifically reconfigure our container infrastructure to allocate dedicated shared memory. As well, in order to build a reliable CI pipeline, we wrote comprehensive unit tests using an in-memory database (:memory:). However, FastAPI's session management kept closing our test connections, destroying the temporary data. We had to build a custom mock database connection wrapper to keep the test states alive.
Accomplishments that we're proud of
- Robustness: We can literally send a kill command to a running training container, and the system seamlessly recovers and resumes training from the checkpointed model state.
- Very solid tests: We achieved near-perfect test coverage on our core controller. Our GitHub Actions pipeline spins up the UI, runs integration tests against live endpoints, and blocks merges if anything breaks.
- Seamless UI for the user: We managed to build a sleek, lightweight application without needing a complex Node.js build step or separate frontend repository.
What we learned
We learned a massive amount about container lifecycle management. Specifically, exactly how Docker and Kubernetes allocate OS-level resources like shared memory to individual processes. As well, we learned how to handle and schedule jobs for Kubernetes by coordinating the controller and the worker. We also deepened our understanding of testing robust asynchronous Python applications, specifically how to mock database connections and handle stateful requests.
What's next for A Machine Learning Engineer's Dream! (AMLED!)
We want to include real-time loss graphs (similar to TensorBoard) and expand our LLM auto-fixing agent so it can automatically adjust hyperparameters if it detects a model's training loss is plateauing.
Built With
- docker
- fastapi
- kubernetes
- petite-vue
- pytorch
- sqlite

Log in or sign up for Devpost to join the conversation.