-
-

A-EYE for the Blind
-

Hardware Setup
-

Depth Image Produced
-
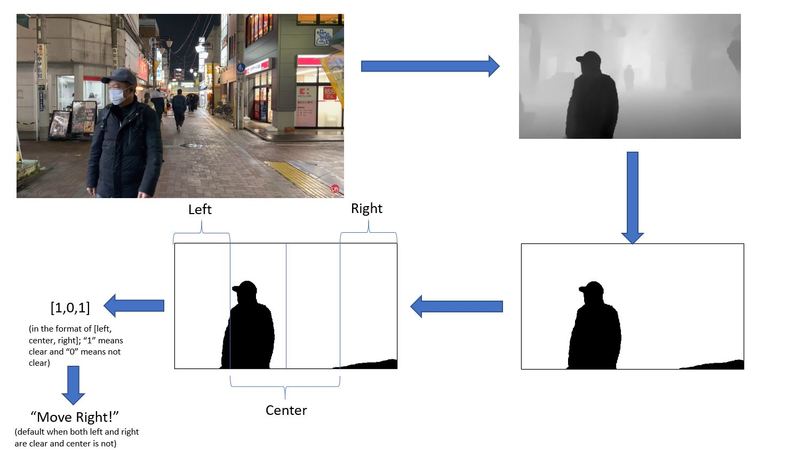
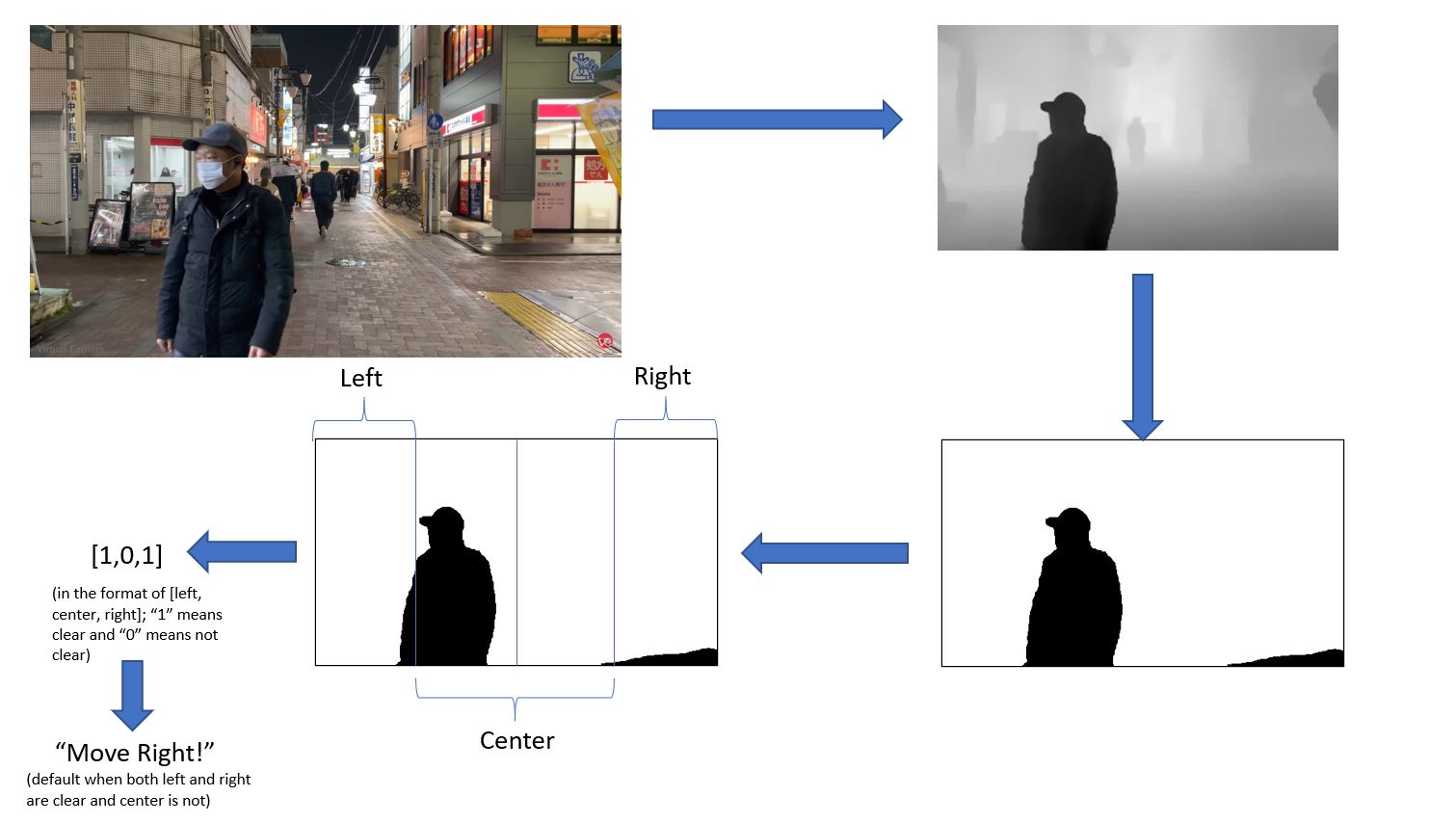
Depth Image to Final Command
-

Home Page
-
Login Section
-
Main Page
-

Firebase




Inspiration
Currently, there are about 300 million people globally with visual impairments. Due to their conditions, they are often limited in their ability to travel around on their own, and doing so often has many risks associated with it. Though most blind people can use canes to "feel" their way around their surroundings, this method has many limitations of its own, including the inability to detect elevated objects and fast, moving objects as well. For these reasons, I decided to create A-EYE for the blind: a product that aims to provide blind people more freedom and safety while traveling.
What it does
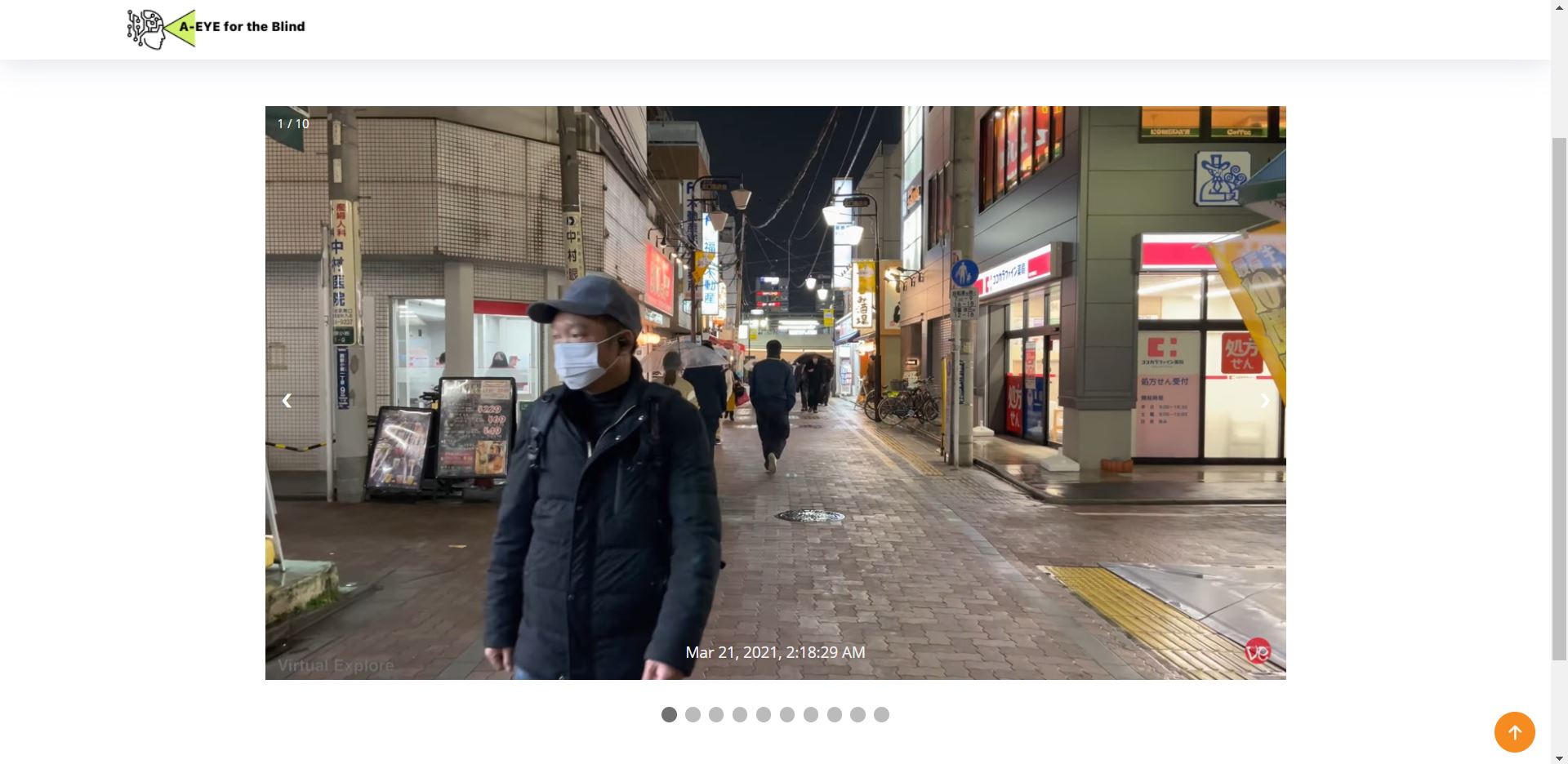
Whenever a blind user goes out to travel around, he or she can use the hardware interface to keep themselves safe during their journey. The hardware interface takes pictures of the user's surrounding, passes the images (in real-time) through a 2D-image-to-depth-image machine learning model, and the Python code integrated into the hardware is able to analyze the various depths of objects in the image and provide users with audio feedback if a side (left, center, or right) is blocked. Finally, the images taken by the device (along with the time they were taken) are also uploaded to a Firebase database under the user's unique UID (for security), and friends and family can check the images live on the website to check-up on the blind person and see if he or she is okay at any time. Location data was also planned to be added to the website, but Python currently doesn't support accurate current location data.
How I built it
Hardware: The hardware setup consisted of a Jetson Nano 2GB, a fan (for cooling down the system while it's running processes), a Raspberry Pi Camera V2, a wifi dongle, a power bank, and wired headphones. The Python code is able to integrate and use all components of the hardware setup.
Model and Python Code: I used a 2D image to depth machine learning model and optimized it for faster performance and higher accuracies. This included implementing methods that used fewer resources, providing more training images that were suitable to the application, adjusting various hyperparameters, and refining results. After achieving the model achieved my desired speed and accuracy, I was able to take the depth images and define thresholds for what the code would consider as an "obstruction" versus what the code would consider as "not an obstruction". Additionally, I split the image into fourths, where the left-most fourth was considered the left side, the middle two-fourths were considered the center, and the right-most fourth was considered the right side. After considerable testing, it was found that if the obstruction area in a certain side was greater than 20% of that total side area, the area truly had an obstruction. On this basis, I was able to develop a code to tell the user (through audio) which areas were blocked and where to move in those situations. Finally, the images captured were uploaded to Firebase under the user's unique UID.
Website (HTML, CSS, JS): To build the website, I used HTML (elements), CSS (styling), and JS (Firebase integration, animations, and more). The website allows friends and families of blind people to sign up for an account and login to them to check on the welfare of the blind person as they travel. User authentication was accomplished through Firebase. Additionally, once the friend or family member logs in, they can view the blind person images (as they travel), the time they were taken, and (in the future) current location. All of this can help re-ensure them that the blind person is safe, and in the case where it looks like the blind person may be in a dangerous situation, action can be taken based on the information provided.
Challenges I ran into
One of the main challenges I ran into was finding a solution to my initial problem of estimating depth. The first solution that came up was using stereo cameras (two cameras separated by a fixed distance) to measure depth. However, this was not very practical as I did not have two cameras, and if in the future I was to implement my product into something more accessible, such as a smartphone, it would not be possible. So, I came across the idea of using machine learning for depth estimation from a 2D image, and I am surprised how it has turned out!
Another challenge was ensuring that my website was completely secure. Privacy was taken into deep consideration and the website was thoroughly tested to see if user data could be extrapolated. With every new way found, I would have to write more code so that people could not access other users' data. I finally reached a point (after considerable time) where there were no ways to hack into other people's data.
Accomplishments that I am proud of
One of the main accomplishments I am proud of was being able to seamlessly connect the hardware, machine learning, and a website in my project!
What I learned
I learned a lot about machine learning, building websites, and Firebase.
What's next for A-EYE for the Blind
One of the key things I want to do is to input a blind person's GPS location into the website and map it, as that would be really helpful in the case they got lost or faced a dangerous circumstance. Another next step would be implementing all of this into a smartphone app, as that would be more accessible.


Log in or sign up for Devpost to join the conversation.