-
-
Machine Learning Preprocessing
-
Function for Audio Distortion Simulator
-
Frontend Animation for Beating Heart
-

Recording Heart Rhythm from Applewatch Microphone

Inspiration
We live in a rural area of the country. Our relatives and family have seen how much cities and the country’s healthcare differs. For example, my father actually had to be airlifted to the city, as nobody comes here for help. Upon starting this hackathon, we thought back to that scary time and investigated how physicians were trying to improve health in rural communities. There, we stumbled upon tele-auscultation.
Auscultation is a common diagnostic procedure where a doctor will test if you have a heart murmur. If so, that opens up the risk of mitral valve and heart problems in the future. That’s why every doctor listens to your heart when you go for your yearly checkup. Tele-auscultation is an attempt at bringing this important procedure to communities like ours – to have doctors diagnose with an electronic stethoscope and have data sent to them, so they can diagnose from anywhere. Unfortunately, similarly to lag on zoom, audio files sent can be corrupted on the way with packet delay, loss, and distortion, which makes diagnosis near-impossible in some cases. We found nobody has solved this issue, as healthcare and network administrators rarely work together. So we solved it.
What it does
We used deep learning to identify heart murmurs. To do this, we used the CirCor Digiscope Phonocardiogram dataset, which is the largest repository of auscultation sounds. This has been done before, but we made two key changes.
Firstly, we mimicked the negative effects of poor networks using data augmentation-on-the-fly. This will help the model operate in telehealth conditions. Secondly, we trained the model to use Apple Watch microphones to improve accessibility, as Apple Watches cost half that of e-stethoscopes which are typically used. We found Apple Watch microphones were better than that of phones because they could record as low as 20Hz, whereas phones usually only 100Hz, which is important because some murmur sounds exist at 70-100Hz.
Our Apple Watch app will listen to the patient’s heart for 20 seconds, then that data is sent to an available physician who provides a first diagnosis, which is then seconded by our model as confirmation. That decision is sent back to the Apple Watch and informs the user.
How we built it
We will break our project into three parts.
- We created a function that simulates the effects of telehealth communication and recording on an Apple Watch.
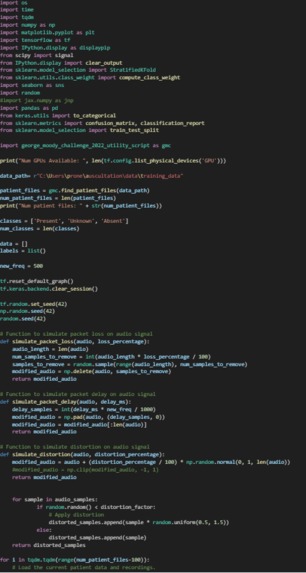
This first involves building our initial dataframe, where we unpack the .wav files from the CirCor Digiscope Phonogram dataset, with over 1000 20-second murmur sounds, and label each with their respective positive or negative murmur diagnosis.
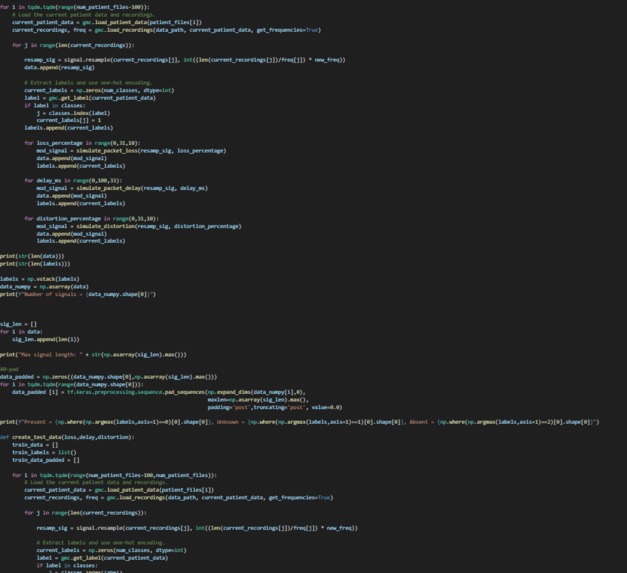
To simulate the effect of network degradation, there are three augments: packet loss, delay, and distortion. The function will simulate the corresponding effect on the audio signal. For packet loss, we randomly remove a specified percentage of the packets. For delay, the function splits the signal into packets and pads the signal with zeros to create the desired delay. For distortion, the function adds random noise to the signal. These modified audio signals are then preprocessed into a numpy array for our machine learning model.
To simulate the sound being recorded by an Apple Watch, we resampled, compressed, distorted, and applied gating. While Apple doesn’t release an analysis of their microphones, community members have published microphone analyses we used to model this section.
- To build the classifier, we used the Keras library, building a simple Deep Neural Network model. This binary classification model will predict the presence or absence of heart murmurs.
To train the classifier, we 0-padded the input audio sequences and applied one-hot encoding to the labels. This allows the model inputs to be standardized. We found the optimal model was a simple DNN. We believe this is because a murmur can exist at any point in the heart sound and may occur multiple times. This means an RNN and LSTM, which focus on long-term relationships will not work. A CNN would also not work well because that forces the audio sequences to be cut up into sections that are analyzed independently, which often would not align with the actual length of one heartbeat or murmur. Thus a DNN allows us to look at short-term anomalies that indicate a murmur.
After training our model, we found there was major overfitting. Thus, we incorporated DropOut layers in our model and k=5 folding to prevent overfitting.
- Frontend (User Application) To develop the watchOS application, we used Xcode, Apple's development software, and their language, Swift. Using this program we made an app that first shows the user a “record” screen. Upon holding the button, the watch starts recording through its mics and shows the user a diagram of auscultation points, prompting the user in the order they should be recorded. The watch then records each auscultation point independently and sends the .wav files to a server hosting the model. The model will return the results of the auscultation to the app, allowing it to transition to the final screen displaying the user’s results.
Challenges we ran into
Our biggest challenge was identifying how to distort the files to make our data sound like it was recorded by an Apple Watch, and to how much they should be distorted to. We had to look through community analysis that we then independently verified by recording our own samples and analyzing the differences between our generated audio and real Apple Watch audio.
Accomplishments that we're proud of
As our model initially without measures to prevent overfitting had a AUC ROC of 1 and accuracy of 100%, we are proud of the measures we took to prevent overfitting. By slowly implementing k-folding, dropout layers, and a specialized SDG optimizer to prevent an exploding gradient, we could make a model that worked well on our validation set. Thus, we were quite surprised by the metrics achieved by the machine learning model, fluctuating between 85 to 90% accuracy with a AUC ROC score of 0.91, which is great but not too good to indicate overfitting.
What we learned
We learned a lot about heart murmurs and about health disparities. 25% of the United States lives in a designated “health professional shortage area”, indicating a lack of primary health care, further emphasizing the importance of telehealth. We also played with several models aside from DNNs, such as CNNs, GRUs, and basic RNNs. We learned that DNNs are by far the most effective for what our classifier was looking for – essentially, an anomaly in a longer sequence. Before, we assumed that the only difference between models was the input shape and what layers we could add. However, now we learnt that different models also work best for different intentions for what data the model should pay attention to.
What's next for A Change in Heart
Looking back, I did not think we would be working with something that could genuinely have an impact on the world. After this hackathon, we hope to refine our model and test an anomaly identification model, which presents our data as a problem to identify an anomalous section of the larger heart sound. This is fundamentally different from our approach. Once we isolate the optimal model, we hope to pursue publishing our app into the Apple app store and having the model locally act as a preventative medicine tool.


Log in or sign up for Devpost to join the conversation.