-
-
Crylens
Project name
Neonatal Cry Analysis for Distress Classification Using Google HeAR
Newborns communicate exclusively through cries, which encode vital information about their physiological and emotional state, yet human caregivers struggle to interpret these cries objectively. This limitation is particularly critical in neonatal intensive care units where timely identification of distress whether from pain, hunger, or neurological issues can significantly impact outcomes. Globally, neonatal mortality remains a pressing challenge, with respiratory distress syndrome and other acute conditions requiring prompt intervention. An automated, objective tool that can analyze cry acoustics in real time would address this gap by providing clinicians with actionable insights, reducing reliance on subjective assessment, and enabling earlier treatment. The potential impact is substantial: improved detection of neurological distress could expedite critical evaluations, better pain recognition could guide analgesic administration, and overall workflow efficiency in busy units could increase, ultimately saving lives and reducing unnecessary interventions.
Problem Overview and Medical Context Why classify neonatal cries? Crying is the primary means of communication for infants. Different causes (pain, hunger, neurological issues) produce acoustically distinct cry patterns. Automatically identifying the cause can: • Aid triage in neonatal intensive care units (NICU) or emergency settings. • Provide objective measurements to supplement subjective clinical assessments. • Enable continuous monitoring of at risk infants. • Reduce unnecessary interventions by correctly identifying hunger versus pain. The three target classes are: Class ID Label Medical significance 0 Pain May indicate acute pain (e.g., from procedures, colic, injury). 1 Hunger A basic physiological need; non urgent but important for care. 2 Neurological Could signal neurological distress, discomfort, or abnormal states (e.g., due to brain injury, seizures, or general unease). Accurate classification can therefore have direct clinical impact. However, the task is challenging because cries vary with age, individual anatomy, and recording conditions, and because datasets are often imbalanced and noisy.
Overall solution:
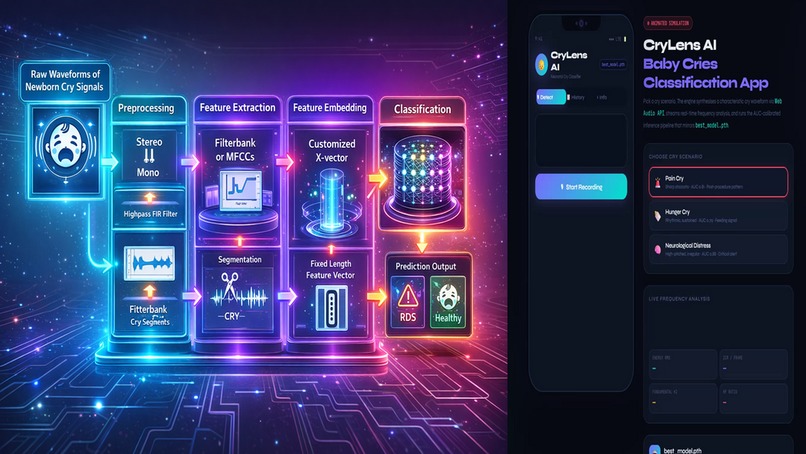
Our solution leverages Google’s Health Acoustic Representations (HeAR) foundation model as its core, integrating it into a complete classification pipeline that distinguishes among pain, hunger, and neurological distress cries. HeAR, a transformer-based masked autoencoder trained on over 300 million health-related audio clips, produces 1280-dimensional embeddings that capture rich, domain-specific acoustic features. By using these pre-trained embeddings, we avoid the need for manual feature engineering and extensive labeled datasets, instead training only lightweight classifiers on top. The pipeline includes comprehensive audio preprocessing, data augmentation, hyperparameter tuning, and both classical machine learning and custom neural network classifiers. This approach fully exploits HeAR’s strengths: its embeddings generalize across recording devices, are robust to noise, and encapsulate subtle biomarkers imperceptible to human listeners. The result is a data-efficient, high-performance system that transforms raw cry audio into clinically meaningful predictions. Technical details
The technical implementation follows a rigorous, modular architecture. Audio files are first collected from multiple datasets, labelled via heuristic path analysis, and split into stratified train, validation, test, and holdout sets to prevent leakage. Preprocessing includes denoising with Wiener filtering, Gaussian smoothing, RMS normalization, and segmentation into two-second overlapping clips, with optional augmentation (noise, time stretch, pitch shift) applied to training data to improve generalization. The Google HeAR model, loaded via TensorFlow from Hugging Face, processes batches of clips to generate embeddings, which are mean-pooled per file. These embeddings are then standardized and reduced via PCA for visualization and classical model training. We evaluate support vector machines, logistic regression, random forests, and gradient boosting with randomized hyperparameter search, and also train an enhanced multi-layer perceptron with batch normalization, dropout, mixup augmentation, and cosine annealing in PyTorch. Comprehensive evaluation including accuracy, precision, recall, F1, confusion matrices, ROC curves, and 5-fold cross-validation demonstrates consistent performance around 67–68% accuracy across held-out sets, with neurological distress most reliably detected (AUC 0.88). The pipeline is fully instrumented for memory management, reproducibility, and generates extensive plots for interpretability, confirming technical feasibility for real-world deployment.
Built With
- baby
- classification
- cries
- def
- gemma
- hai
- neonatal

Log in or sign up for Devpost to join the conversation.