-
-

WGAN-GP algorithm
-
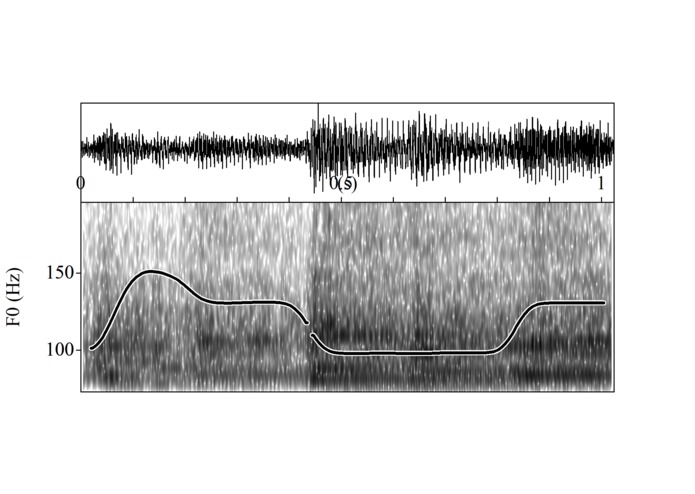
Fake waveform, spectrogram and F0 contour
-
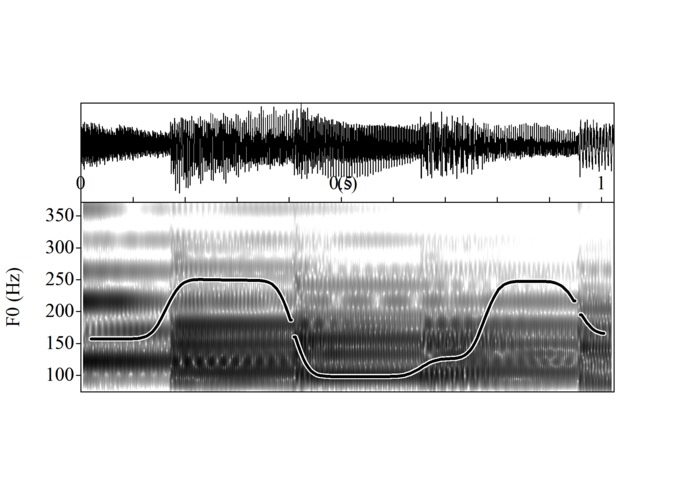
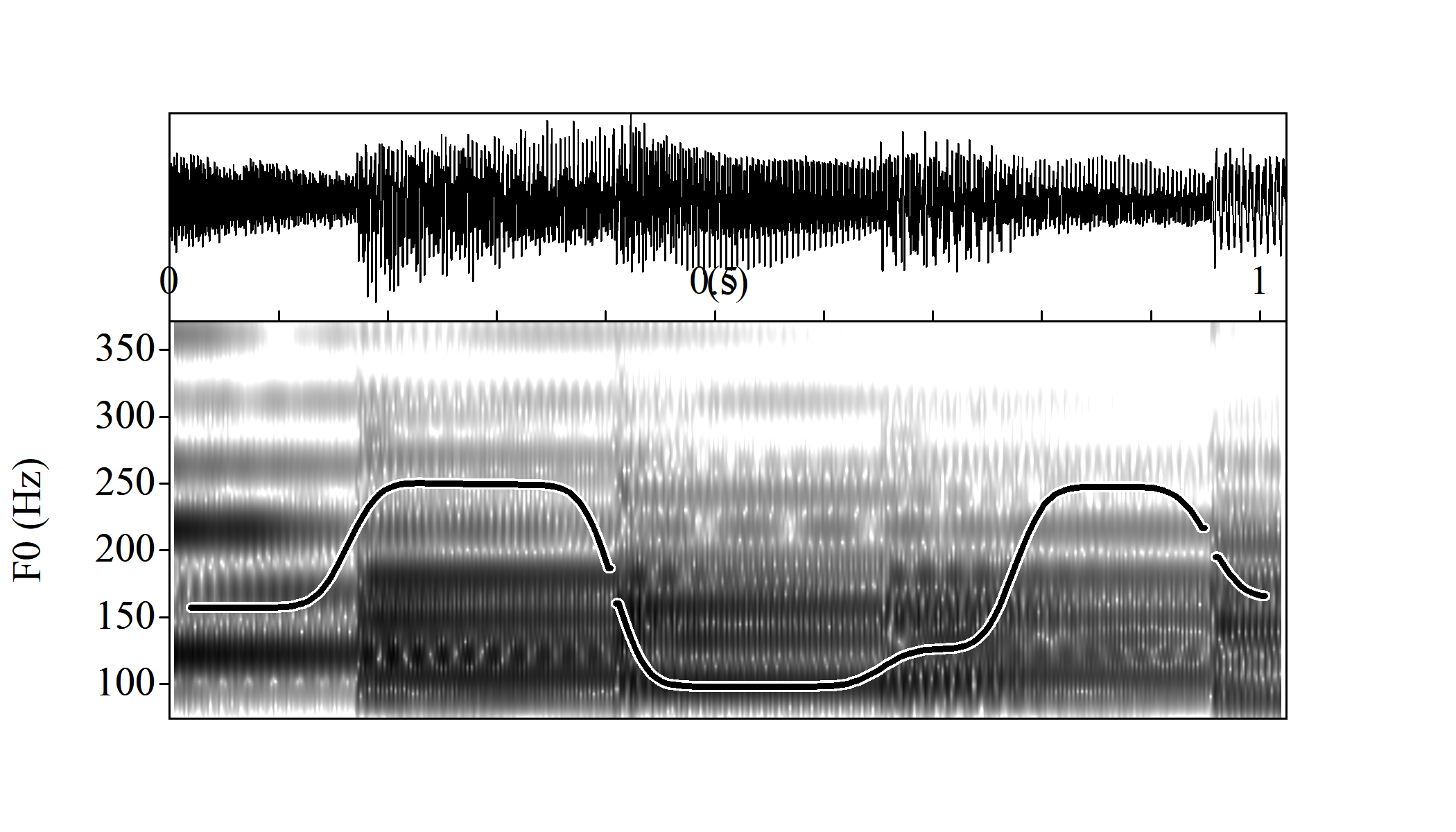
Real waveform, spectrogram and F0 contour (notice the more distinct horizontal regions)
-
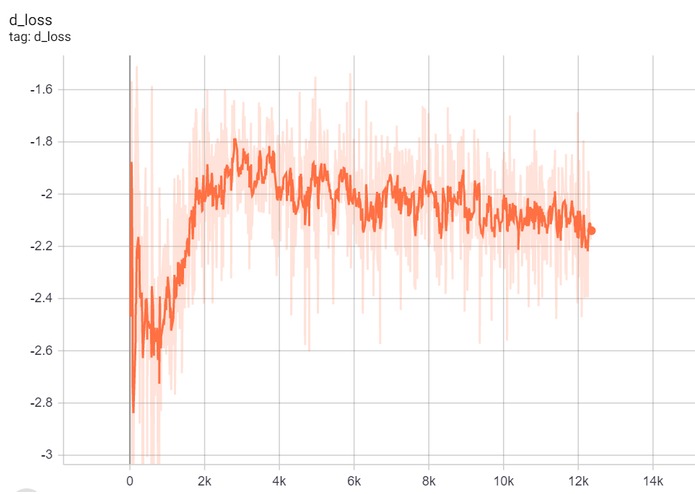
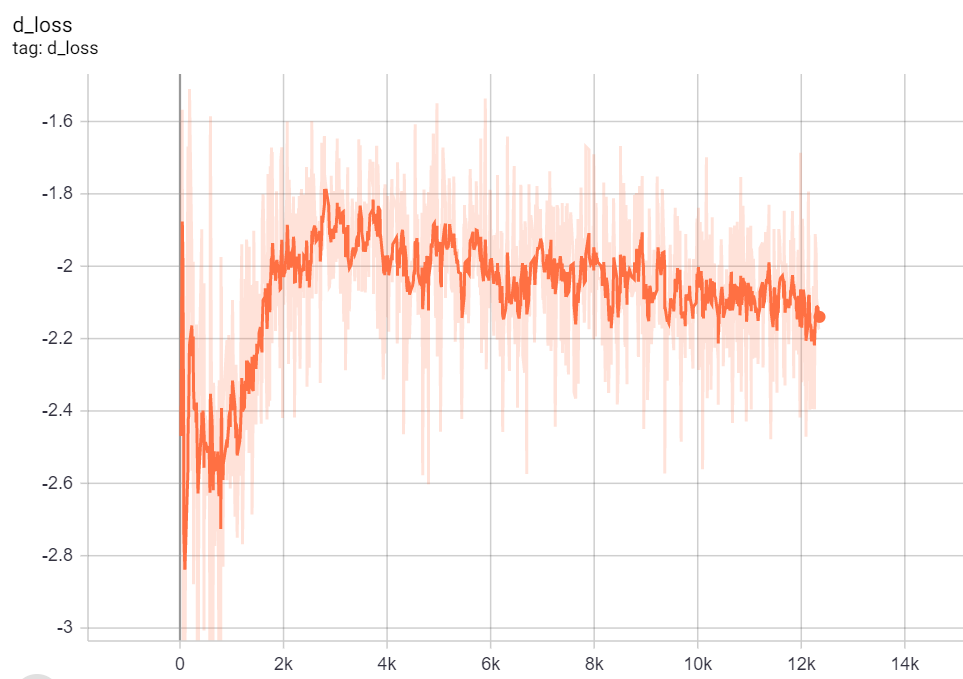
Critic loss
-
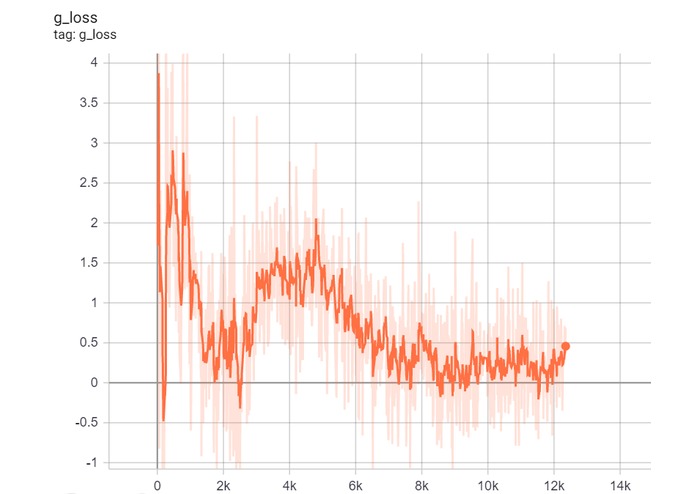
Generator loss



tfworldhackathon
GitHub repo for my Tensorflow World hackathon submission
Inspiration
Since the inception of generative adversarial networks, I have been fascinated by their capacity to perform tasks of unprecedented complexity. They are a prime example of how machines can learn in a similar manner to humans - akin to reinforcement learning. I am also a huge fan of music and love to play the piano. So I thought, why not conflate my love for machine learning and my passion for music!?
Music generation has many different and exciting potential applications such as:
- Providing melody inspiration to artists
- Creating infinite, unique and free music without the need for audio file storage (for retail shops, restaurants, cafes, video games, radio stations etc.)
GANs are already well-established in the image-processing domain, but not so much in NLP or audio-processing due to their sequential structure. After some investigaton, I learned about WaveGAN. So, I set out to adapt WaveGAN for piano in Tensorflow 2.0 using WGAN-GP as my training mechanism (as recommended by the paper).
What it does
MusicGAN generates approximately one second of music (from a particular instrument i.e. piano) given a random noise vector. The majority of existing technologies generate MIDI files, which contains information such as the notes and tempo of a song, but do not contain any audio data. This approach loses the character and personality of music that can't simply be transcribed.
I have also created a JavaScript model for implementation in webpages down the track.
How I built it
I adapted code for WGAN-GP and created my own WaveGAN using Tensorflow-GPU 2.0. I tried developing my script to be as transparent as possible so that someone can look at it, change some parameters, and get going.
I took a highly systematic and methodical approach, since a lot of my work was writing code based off of research papers, or needing conversion from Tensorflow 1.x.
Firstly, I trained a regular GAN on the MNIST dataset using WGAN-GP to ensure that I had implemented the training algorithm correctly. Next, I used an old Tensorflow 1.x WaveGAN implementation with my architecture to be certain that my generator and critic models were correct. Then I inserted my generator and critic models into my WGAN-GP infrastructure, replacing the MNIST GAN. Lastly, I tested the script on the same audio datasets used in the WaveGAN paper to make sure everything was ready to go. Finally, I started running my script on piano audio, adjusting hyperparameters and optimizing my models' architecture (trying to avoid mode collapse and failure to converge).
Challenges I ran into
I spent quite a bit of time getting used to tensorflow.GradientTape and watching tensors etc. This was new to me since this project was my first shot at using Tensorflow 2.0. The majority of errors I faced were due to implementation/import mistakes, which I scoured GitHub to solve. In particular, finding elegant workarounds for functions contained in tensorflow.contrib proved to be challenging. Annoyingly, many solutions made use of tf.compat.v1, so I had to circumvent the problem some other way.
Additionally, I had to maintain constant consideration with regards to my computation capacity. My PC has a Nvidia RTX 2060, but training still took many many hours, and I had to use small batch sizes.
Accomplishments that I'm proud of
In light of the fact that I wasn't familiar with the new API, had never heard of WaveGAN or WGAN-GP and had hardware limitations, I am proud to say that I gave the project my best shot.
What I learned
I can now say that I can train a GAN in Tensorflow 2.0, and I have also improved a lot of accessory skills involving numpy, matplotlib, tensorboard. Also, my understanding of CNNs, ReLU, transposed convolutions and general training monitoring techniques has deepened.
What's next for this project
I am currently exploring the generation of other musical instrument sounds, such as the violin and saxaphone. My next goal is to create a recurrent version of WaveGAN by using LSTM's and minature WaveGAN's to produce short segments of audio in a sequentially. This would allow for any duration of audio to be created.
Log in or sign up for Devpost to join the conversation.