-

Are You Dead?
-
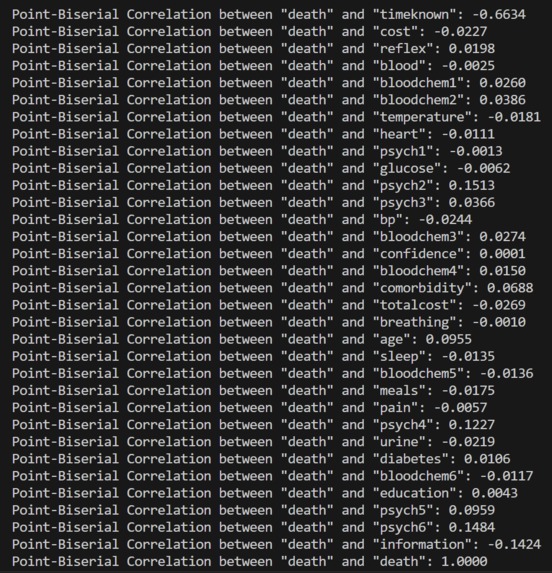
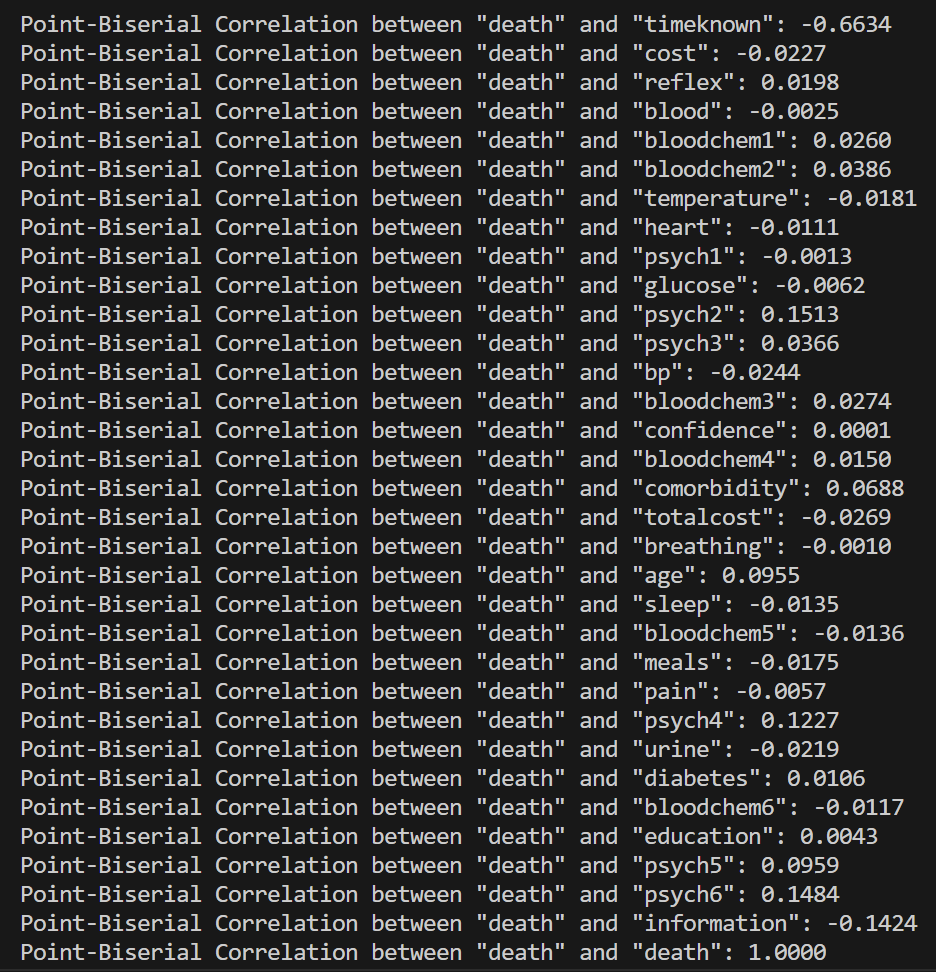
Result of our Point Biserial Calculations
-
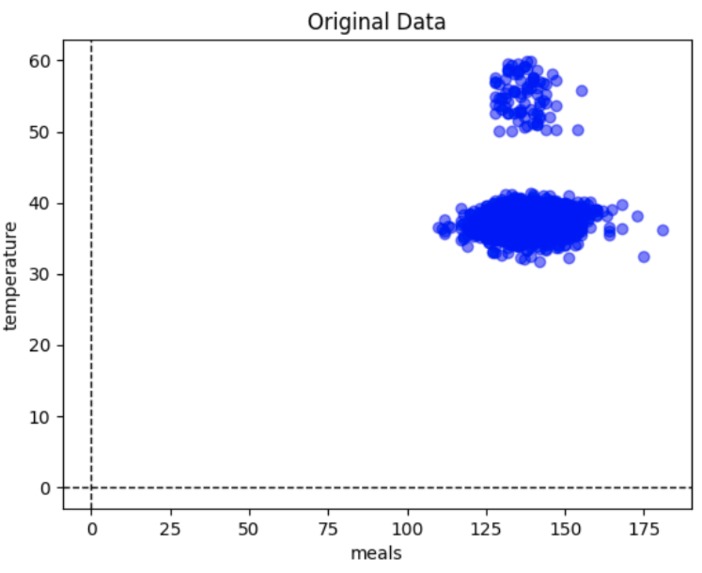
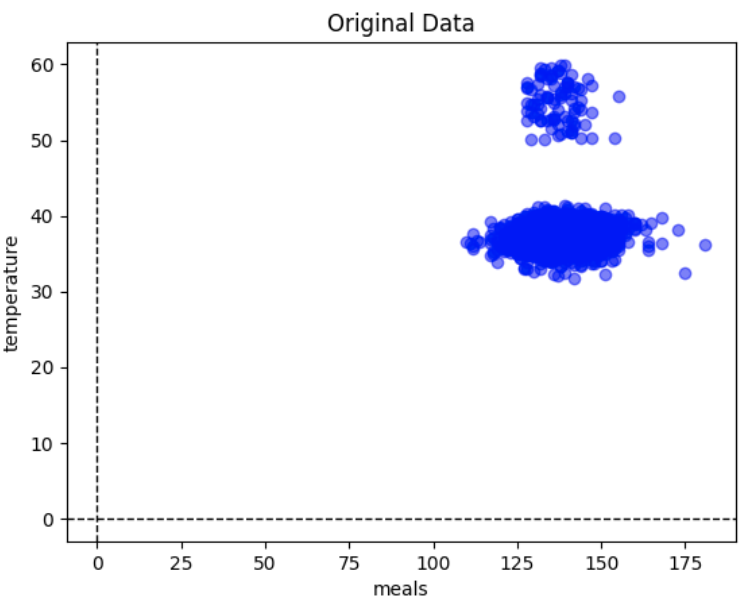
Temperature v Meals
-
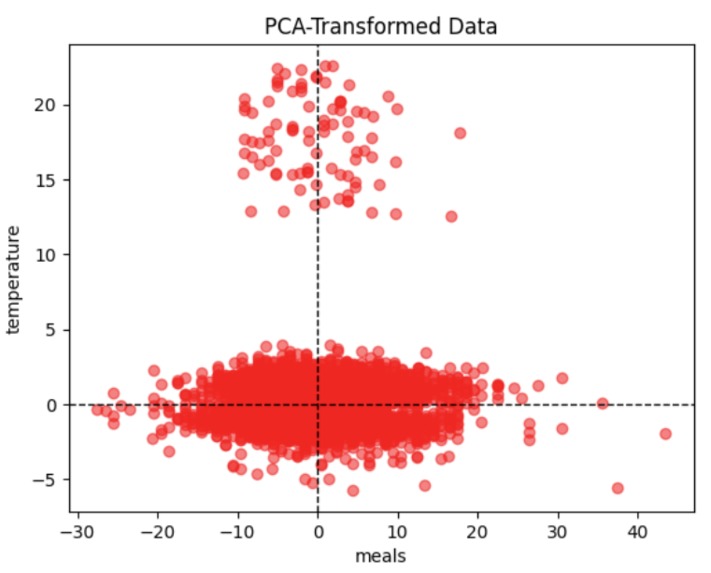
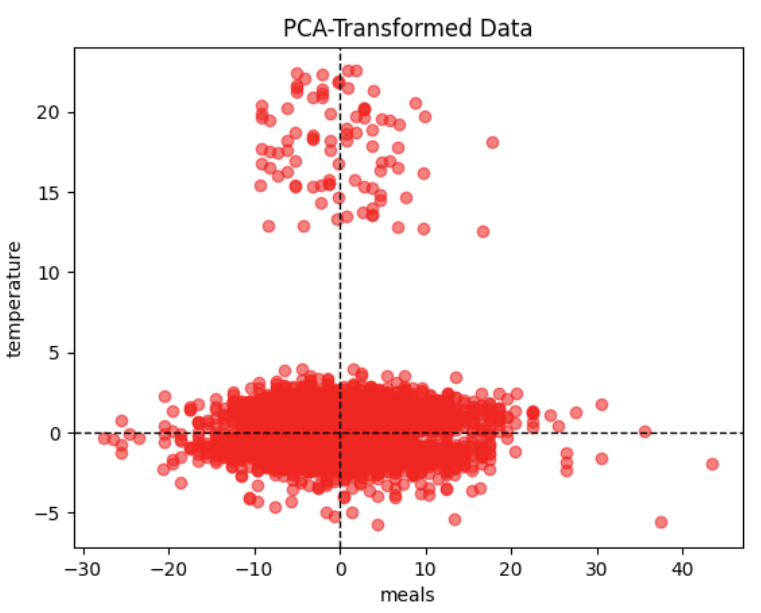
PCA Transformed

Inspiration
On a daily basis, countless individuals worldwide visit healthcare facilities, where an extensive repository of patient data is accumulated. This data, crucial for future research and current diagnostics, can be transformed into priceless information through data regressions and correlations. Yet, this doesn't come without its own issues. When on a massive dataset, trivial problems as manual error, database error, or simply just being out of date causes discrepancies in the results. Addressing these errors is vital towards enhancement of data precisions and accuracy.
What it does
Data that is entered gets filtered through parameters in place discarding inherently wrong data, such flaws encompass improbable values and outdated information. Additionally, we standardize our data in order to find a confidence error within our dataset. This filters out extraneous solution and maintains data that provides consistent results. Data sets are now sampled by training a neural network module to develop optimal results.
How we built it
We first began by experimenting with which parts of the data were strongly associated with whether the patient would die or not. We found that variables such as "timeknown" (how long the patient knew they had a disease), sex, and age had a positive impact on the accuracy of our model.
To improve the model even further, we worked to implement various techniques to preprocess and filter nonsensical data from our training set, and to automatically compute which of the nearly 45 variables had any kind of association with a patient's death.
Challenges we ran into
We ran into a multitude of challenges, starting with identifying potential problems in the provided data which had many errors and discrepancies that threw off the training of our model. This included. As a result, we resorted to using statistics to preprocess our data and ultimately create an algorithm to effectively clean any set of data given by TDHospital.
Another major challenge we encountered was trying to find a correlation, and ultimately a regression, between each category's value and the probability of death. That way, we would know which categories were statistically significant and include them in the training of our model.
Outliers, typos, and a lack of a standard in the provided data were all things we had to consider and find a solution for when training our model to provide an accurate prediction as to whether the patient is alive or dead.
Accomplishments that we're proud of
Due to the size of the dataset and vast amount of categories, small errors provide a massive impact in overall data trends. While facing such issues, we were able to compare multiple forms of regressions and comparisons to develop the most consistent categories. While this was our first Datathon, it was vital to be able to understand the logic behind data comparison and machine learning. We were able to build upon our knowledge and utilizing in situations applicable within the industry.
What's next for A
We hope that this is just a start to our never-ending pursuit towards knowledge. As technology advances, data will only become more vast, hence requiring stronger processes due to an overabundance of possible error. Using stronger algorithms for data will not only save resources, but formulate more valuable knowledge. Through the exploration of various data analysis techniques we were able to expand our curiosity towards data science. While the world progresses, we hope to help develop vital knowledges to create a more intelligent future.



Log in or sign up for Devpost to join the conversation.