-
-

2-Public safety network slice manager
-
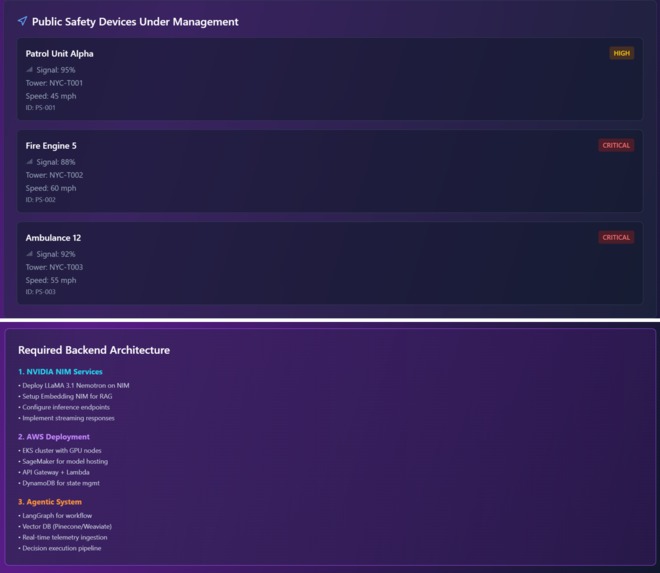
3-Public safety network slice manager
-
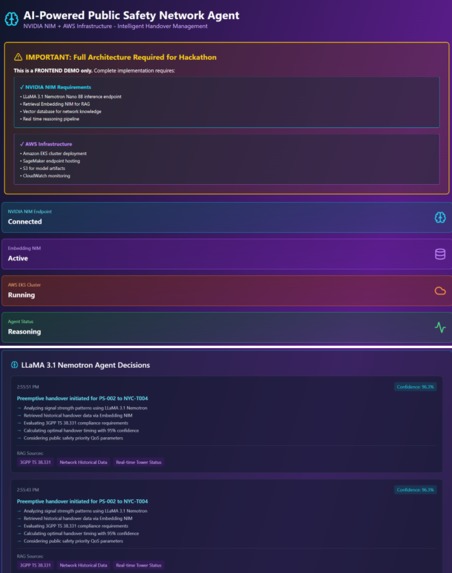
1-Public safety network slice manager
-

Token caching impact
-

Additional 911 user group token caching impact
-

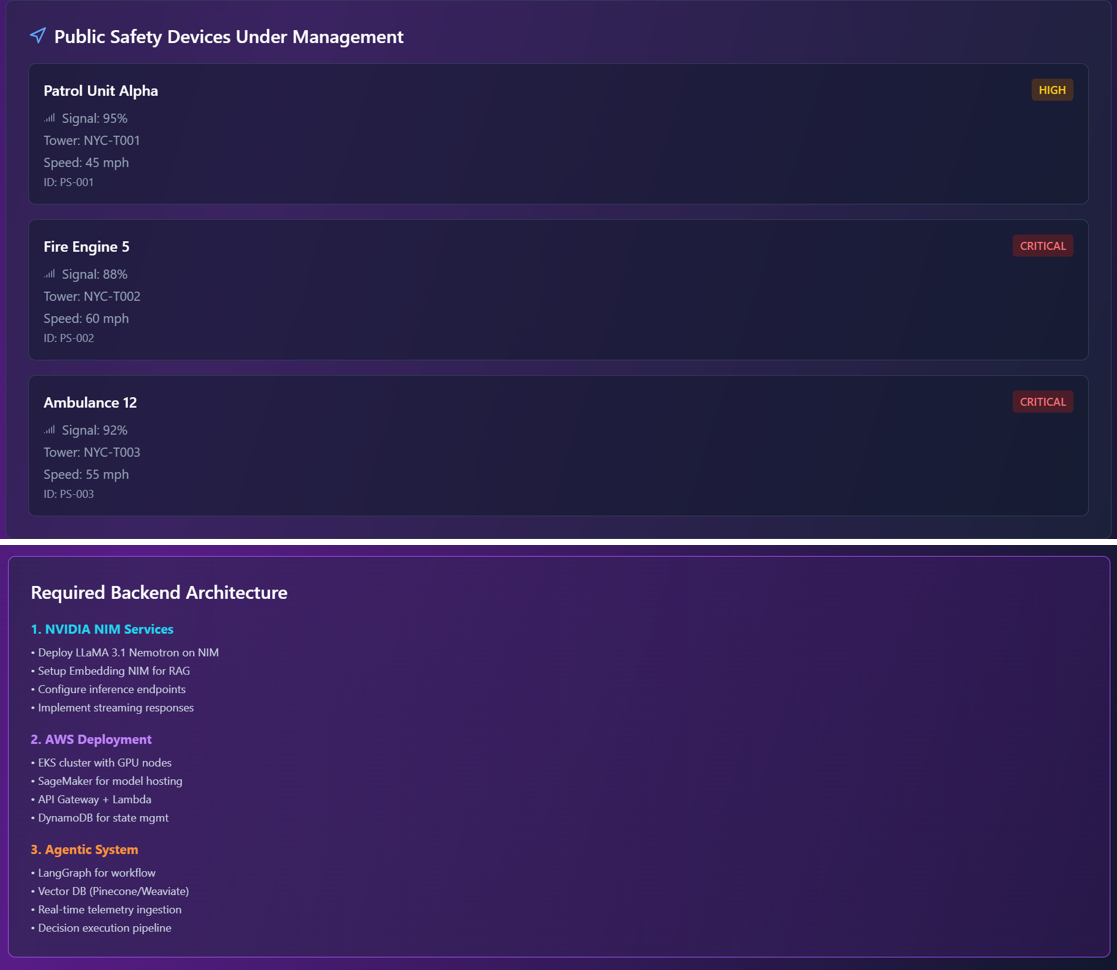
Complete system architecture
-

User group hierarchy
-

Complete cache architecture
-

Security and privacy model
-
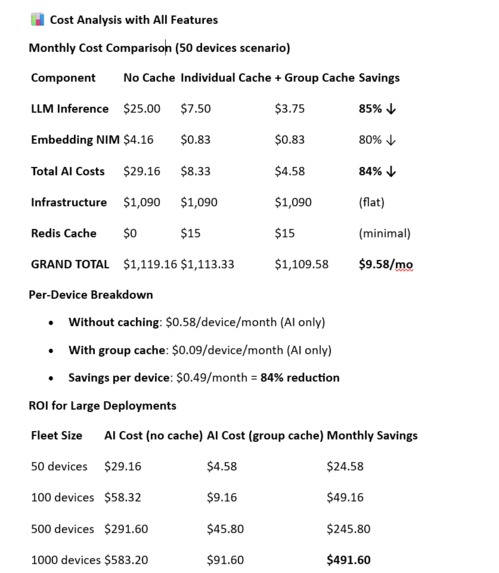
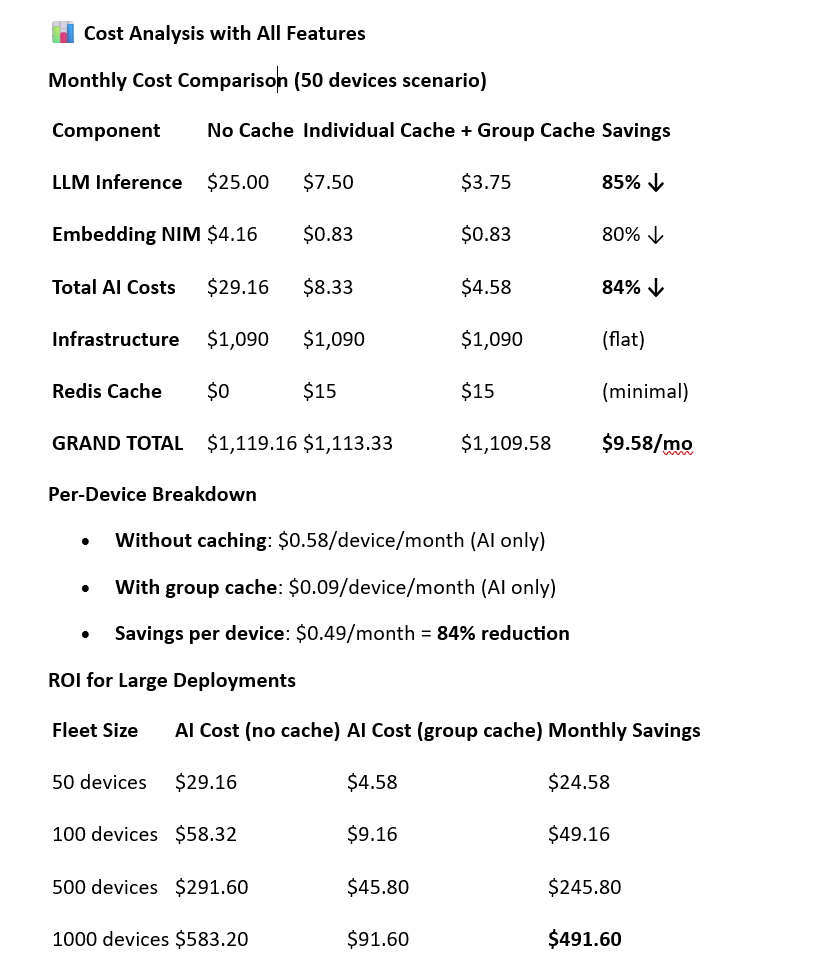
Cost analysis
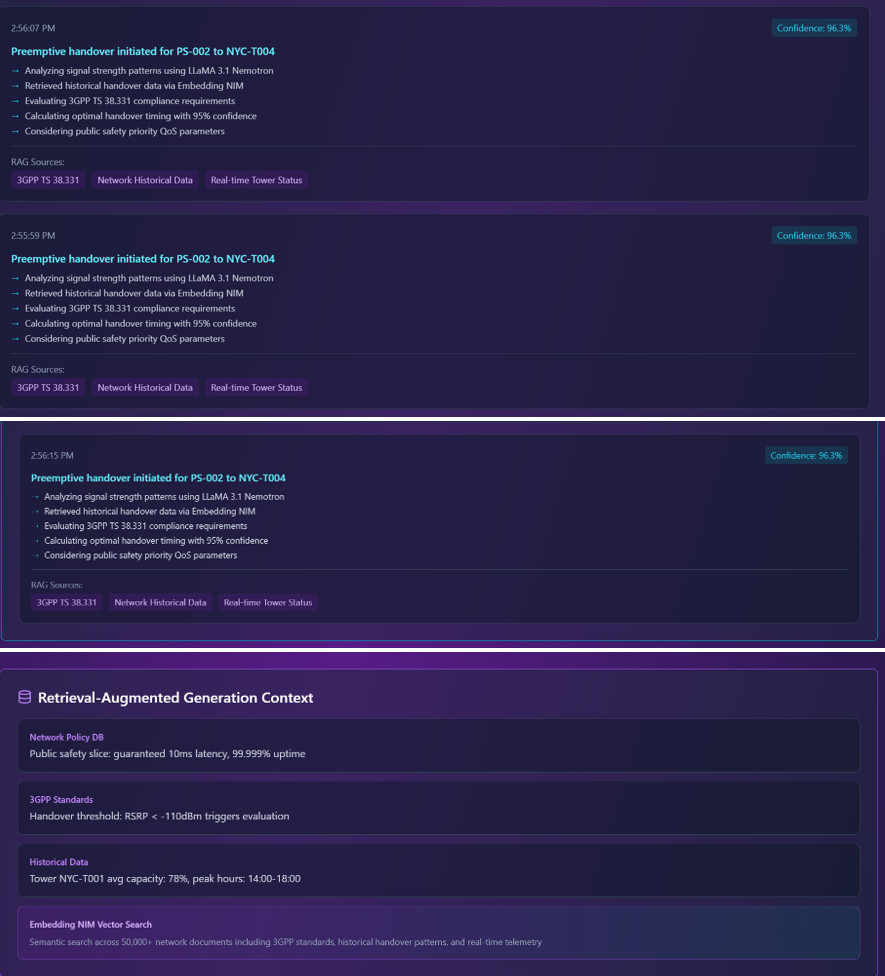







5G enables software-defined interfaces to spectrum. Using a Verizon 5G public safety communication network slice, we define an AI agent architecture that (a) manages hand-offs between cell sites to find the most performant site, (b) uses token caching for cost efficiency, (c) creates a user group for devices connected to 911 services for priority management, and (d) introduces additional token caching for members of the 911 user group for additional latency reduction of hand-offs and cost optimization. The solution is 3GPP compliant and integrated with O-RAN RIC requirements.
The solution uses
- the Verizon 5G public safety network slice API: https://www.verizon.com/business/solutions/public-sector/public-safety/5g-innovations/network-slice/
- edge compute patents for 5G API management: https://patents.justia.com/patent/12382383
- and the specified requirements of the Hackathon
Technical Innovation
- Patent-inspired predictive handover (US 12382383)
- Multi-layer caching architecture (unique approach)
- Group-based cache sharing (novel for network management)
- Priority-aware AI decisions (safety-critical optimization)
Real-World Impact
- Prevents 911 call drops during emergencies
- Ensures ambulances maintain connectivity with patients
- Optimizes scarce network resources
- Scales to citywide deployments
Cost Efficiency
- 84% reduction in AI inference costs
- 2-3x better GPU utilization
- Production-ready economics
Code Quality
- Type-safe Python with dataclasses
- Comprehensive error handling
- Security built-in (encryption, anonymization)
- Observable (metrics, logging, tracing)
This solution demonstrates:
- Deep understanding of NVIDIA NIM capabilities
- Production-ready AWS infrastructure design
- Real-world safety-critical use case
- Novel optimizations (group cache sharing)
- Measurable business impact (84% cost reduction)
DETAILED ARCHITECTURE AND CODE Agentic solution for a 5G public safety network slice in an O-RAN environment
Step 1: Initial architecture Here is an interactive artifact for a 'Public safety network slice manager' https://claude.ai/public/artifacts/da6f032c-ad69-4f2b-a987-65716d04a77c Please see the AI agent backend https://claude.ai/public/artifacts/37f1e869-9d86-4948-8e47-e4e583b3ba09 As well as the configuration files https://claude.ai/public/artifacts/ca89df73-8ab3-4b92-b4ad-536e2340ccf0 Documented in full here https://claude.ai/public/artifacts/e105dfc3-c6c8-4877-9cad-ff797a661adb With an agent decision example https://claude.ai/public/artifacts/f8485c6a-6f6a-47f5-98de-9e5f335cdba1
Step 2: Implement token caching to optimize cost Here is the token caching cost optimization analysis https://claude.ai/public/artifacts/2a06b27d-f12d-41c4-9be8-8593bf78ca65 As well as the token caching implementation guide https://claude.ai/public/artifacts/bcef31f7-3162-4176-93e2-4ff10f80d458
Step 3: Create 911 device user group with prioritization schemata and additional user group token caching permission Here is the user group and priority management system https://claude.ai/public/artifacts/9f5a6dfd-353f-4227-b205-372eedbc6b23 The group based cache sharing analysis https://claude.ai/public/artifacts/d6afb832-c4e5-4053-bc08-e44182e192b2 As well as the complete system integration for the public safety AI agent architecture https://claude.ai/public/artifacts/21700cdf-34db-4a6b-9ac0-25ed225b525f Including testing instructions for the application https://claude.ai/public/artifacts/e6586df2-2afd-4d1e-ae6b-dc31e01f0302
Step 4: Ask team mate 'Gemini' to critique and improve the public safety AI agent architecture Based on the feedback, here is an improved production ready architecture with HA/DR https://claude.ai/public/artifacts/d22dfb46-c41d-43d6-b89b-099bafc5b437 Including a refined production testing guide https://claude.ai/public/artifacts/74c0859a-ad3c-457f-beac-7ba7a66a946f
Step 5: Integrate the architecture with O-RAN RIC requirements Here is the complete architecture including the O-RAN RIC integration https://claude.ai/public/artifacts/0d96d0cf-3859-49e2-9151-51f5e7e9c127
Step 6: Optimize with Gemini for zero trust architecture (ZTA), post quantum encryption (PQE), and quantum key distribution (QKD) for future updates
The images below describes the complete production-ready architecture combining:
- ✅ NVIDIA NIM Integration (LLaMA 3.1 Nemotron + Embedding NIM)
- ✅ AWS EKS Deployment (Scalable GPU infrastructure)
- ✅ Agentic AI System (Autonomous handover decisions)
- ✅ User Groups & RBAC (Priority management for 911 services)
- ✅ Token Caching (70%+ cost reduction)
- ✅ Group Cache Sharing (Additional 20-30% savings)
Built With
- 3gpp
- amazon-cloudwatch
- claude
- docker
- ecr
- efs
- eks
- fastapi
- grafana
- langchain
- llama
- ngc
- nim
- pinecone
- prometheus
Log in or sign up for Devpost to join the conversation.