-
Poster
Title: Re-implement the Image Retrieval Model DELG
Who: Yao Yang(yyang376), Linquan Zhou(lzhou65)
Introduction:
Global and local features are necessary for high image retrieval performance, and each type of image representation has its advantages. Global features can learn similarity across very different poses where local features would not be able to find correspondences; in contrast, the score provided by local feature-based geometric verification usually reflects image similarity well, being more reliable than global feature distance. A common retrieval system setup is to first search by global features, then re-rank the top database images using local feature matching to get the best of both worlds. These two types of features need to be separately extracted using different models. This is undesirable since it may lead to high memory usage and increased latency. Besides, in many cases similar types of computation are performed for both, resulting in redundant processing and unnecessary complexity. Maybe there will be some solutions to unify the local and global features for efficient image search. Unifying Deep Local and Global Features for Image Search, a paper we chose to implement, addresses the problem of image retrieval, which falls under the category of unsupervised learning. The paper’s objective is to unify global and local features into a single deep model, enabling accurate retrieval with efficient feature extraction. Specifically, (1) Develop a unified model to represent both local and global features, using a convolutional neural network (CNN), referred to as DELG (DEep Local and Global features). (2) Adopt a convolutional autoencoder module that can successfully learn low-dimensional local descriptors, and avoids the need of post-processing learning steps. (3)Design a procedure that enables end-to-end training of the proposed model using only image-level supervision.
Related Work:
One paper related to the image retrieval topic is Fine-tuning CNN Image Retrieval with No Human Annotation. The main objective of this paper is fine-tuning CNNs for image retrieval on a large collection of unordered images in a fully automated manner. Reconstructed 3D models obtained by the state-of-the-art retrieval and structure-from-motion methods guide the selection of the training data. The paper selects both hard-positive and hard-negative examples by exploiting the geometry and the camera positions available from the 3D models, enhancing the performance of particular-object retrieval.And the paper proposes a novel trainable Generalized-Mean (GeM) pooling layer that generalizes max and average pooling and show that it boosts retrieval performance.
URLs:
Original Paper:link
Data:
Training Dataset: Google Landmarks dataset v2 (GLDv2), which has 118k tests (41k validation and 77k testing) and 4M training images from 203k landmarks. Because the Google Landmarks Dataset v1 is deprecated and no longer available, our project will use GLDv2 instead of GLD. Preprocessing: The images first undergo augmentation by randomly cropping/distorting the aspect ratio; then, they are resized to 512 × 512 resolution. Evaluation Datasets: Oxford and Paris with revisited annotations, referred to as ROxf and RPar.There are 4993 (6322) database images in the ROxf (RPar) dataset, and a different query set for each, both with 70 images. We may just use the subsets of datasets above to reduce training/evaluating time, and we can also change the role of GLD and GLDv2 to do training and testing, maybe.
Methodology:
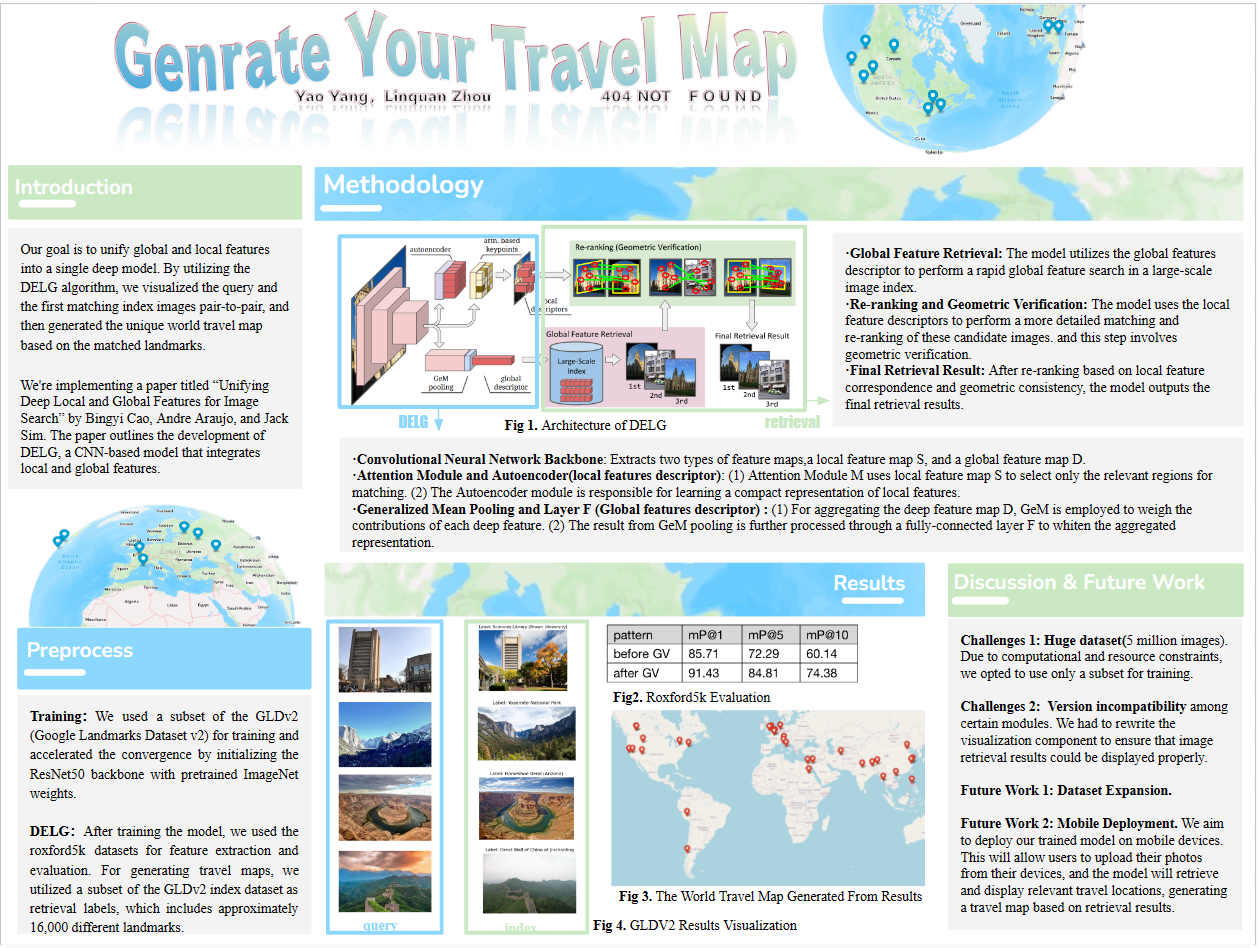
model architecture
Convolutional Neural Network Backbone: The image is first processed through a CNN backbone and extracts two types of feature maps: (1) shallow feature map (S): represents local, intermediate layer activations that capture detailed, localized information. (2) deep feature map (D): captures global, deeper layer activations that encode high-level cues.
Attention Module and Autoencoder(local features): (1) Attention Module M is used to select only the relevant regions for matching. This is performed as A=M(S) where S is the shallow feature map and M is a small convolutional network. (2) The Autoencoder(AE) module is responsible for learning a suitable low-dimensional representation to let local features be represented compactly. The local descriptors are obtained as L = T(S) where T is the encoding part of the autoencoder.
Generalized Mean Pooling and Layer F (Global features) : (1) For aggregating the deep feature map (D), GeM is employed to weigh the contributions of each deep feature. This results in a pooled global feature that summarizes the content of the image (2) The result from GeM pooling is further processed through a fully-connected layer F to whiten the aggregated representation
It begins by extracting key points and their corresponding local descriptors through an autoencoder and attention-based mechanisms. Then, it employs GeM to aggregate a global descriptor from deep-layer activations. Global features are used to retrieve images from a large-scale index, producing a preliminary ranking. Subsequently, geometric verification is applied to re-rank the initial results to enhance matching accuracy. Finally, the model outputs a final retrieval result ranking based on geometric consistency adjustments, focusing on identifying and matching relevant features within the images while ignoring background or irrelevant content.
Training
The training of the model is conducted using only image-level labels without the need for more granular, patch-level supervision. The process includes three types of losses:
Global Features Training Global features are trained using an ArcFace loss, which is a cross-entropy loss applied after scaled softmax normalization. It uses L2-normalized classifier weights and incorporates the ArcFace margin to improve intra-class compactness and inter-class discrepancy.
Local Features Training: Local features are trained using two losses. The reconstruction loss Lr is a mean-squared error loss that measures the autoencoder's ability to reconstruct the shallow feature map S. The attention loss La is a cross-entropy loss that encourages the attention module to highlight discriminative local features, using attention pooling to focus on the relevant parts of the reconstructed features
Gradient Control: The gradients from the attention and reconstruction losses are prevented from flowing back into the CNN backbone during training. This is done to maintain the hierarchical feature representation learned by the backbone, which is optimized using only the global feature loss Lg
The training is end-to-end, with the local descriptors generated by the autoencoder and the attention pooling mechanism being used only during training. The global descriptor generated through GeM/Whitening is utilized in conjunction with the ArcFace Loss for classifying different landmarks.
Problems
The most challenging part of implementing the model could be establishing an environment that supports training with hundreds of gigabytes of data. The solution could be utilizing cloud services for their scalability and storage or training on a subset of data with a personal computer.
Metrics:
To train and test the model, we plan to use TensorFlow with the Slim library and training on Google Landmarks Dataset (GLD) with a split for validation. In the paper, the authors aimed to improve image retrieval and recognition capabilities by developing a model that effectively unifies deep local and global feature learning without requiring fine-grained patch-level annotations. They quantified their model's effectiveness through ablation studies, analysis of controlling gradient propagation, comparison with independently trained models having similar hyperparameters, and benchmarking against state-of-the-art technologies. They utilized evaluation metrics: Mean Average Precision (mAP) and Micro Average Precision (µAP), to assess the model's performance in image retrieval and recognition tasks. Our base goal is successfully replicating the experiment from the paper, training a high-accuracy model, and achieving the performance metrics reported in the paper. The target goal is to try different datasets to test the model. The stretch goal is to add the feature of annotating predicted landmarks on a map, enhancing the visualization of the model's output.
Ethics:
What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain? Our main dataset is GLDv2, which was obtained through crowdsourcing on Wikimedia Commons, meaning the data source is public and diverse. However, due to its reliance on crowdsourcing, there might be challenges such as class imbalance (some landmarks might have more images than others) and the accuracy of annotations could be affected by the quality of contributors. Additionally, due to the global nature of the dataset, it might contain biases from different regions and cultures, such as the over-representation of landmarks from certain areas. The representativeness of GLDv2 depends on its ability to cover a wide range of landmark categories and geographical locations. Despite the dataset's size, there might still be instances where certain regions or types of landmarks are underrepresented. This could affect the performance of models in specific areas or for specific types of landmarks.
Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm? This is an algorithm of image retrieval, these groups are likely to be the major “stakeholders”— (1)Researchers and Academics: They rely on the dataset to develop and evaluate new algorithms and models. Mistakes in the algorithm could lead to incorrect conclusions and hinder progress in the field. (2)Tech Companies: Companies that provide image search and recognition services use these models to enhance their products. Errors could result in poor user experience and loss of trust in the service. (3)Cultural and Tourism Organizations: They might use these technologies to promote landmarks and cultural heritage. Inaccuracies in recognition could lead to misinformation and negatively impact tourism. (4)General Public: Users who interact with image search and recognition services are stakeholders, as they expect accurate and relevant results. Errors could lead to frustration and reduced confidence in the technology.
Division of labor:
Yao Yang: environment setup and model training Linquan Zhou: model training and testing. Both of us will be involved in fine-tuning.



Log in or sign up for Devpost to join the conversation.