-
-
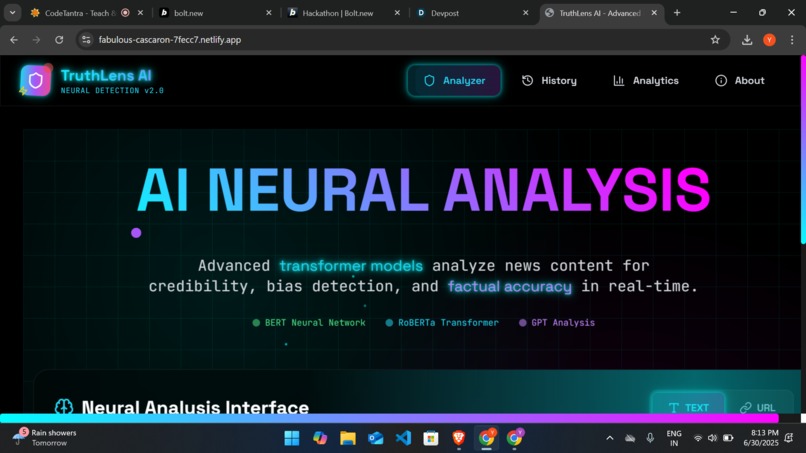
Ai Fake News Detection System
-
Cut through the noise—our AI picks up on fake news before it deceives you. Stay smart, stay in the know. #FakeNewsDetector
-
"Truth has a new best friend. Say hello to the AI that distinguishes fact from fiction in seconds. #AIvsFakeNews"
-
AI on a mission: Uncover lies, enlighten minds. Step into the future of detecting fake news. #AIForTruth"
-
Detect. Decode. Debunk. This isn't just a site—it's your shield against disinformation. #FakeNewsShield"
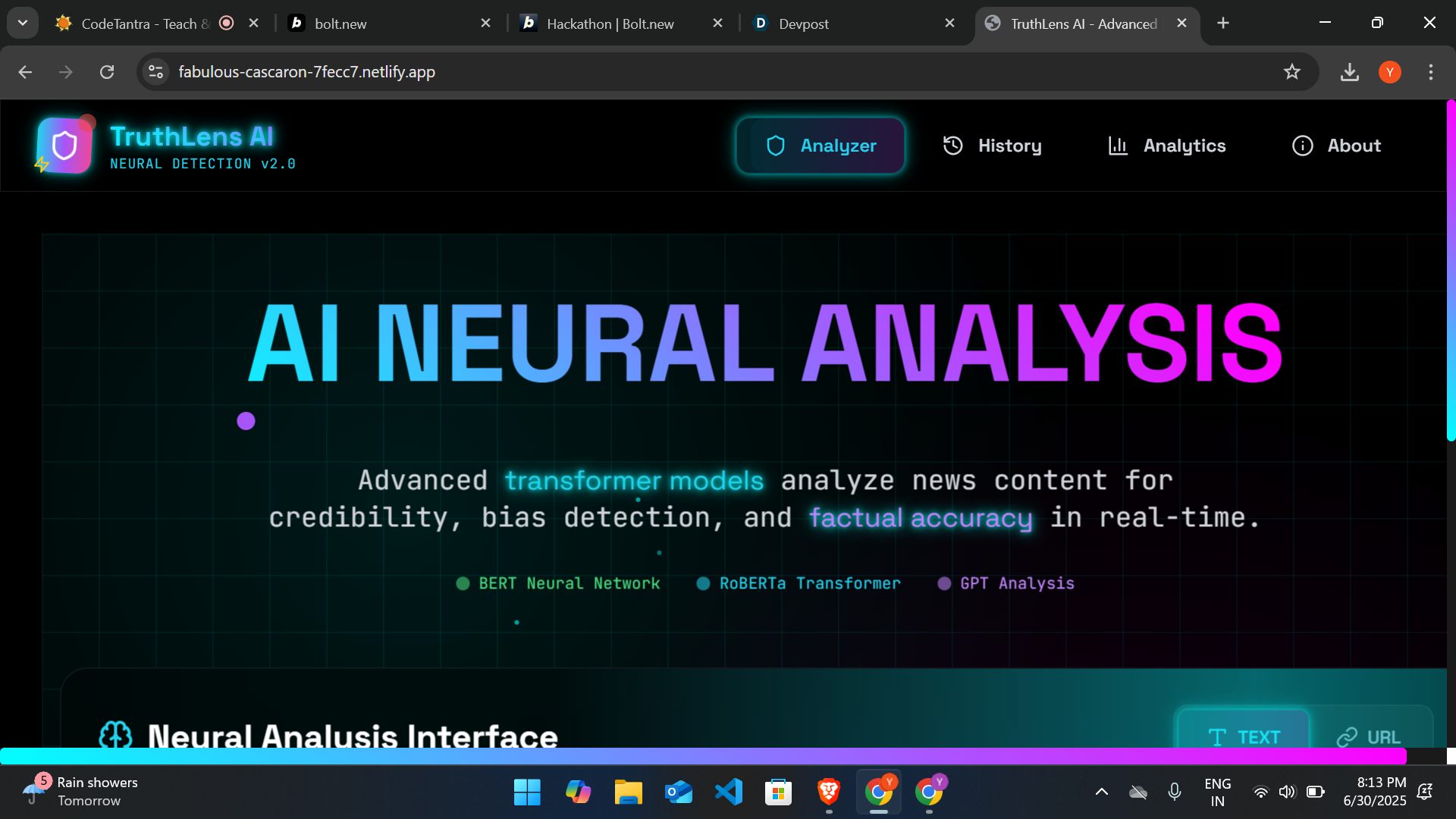
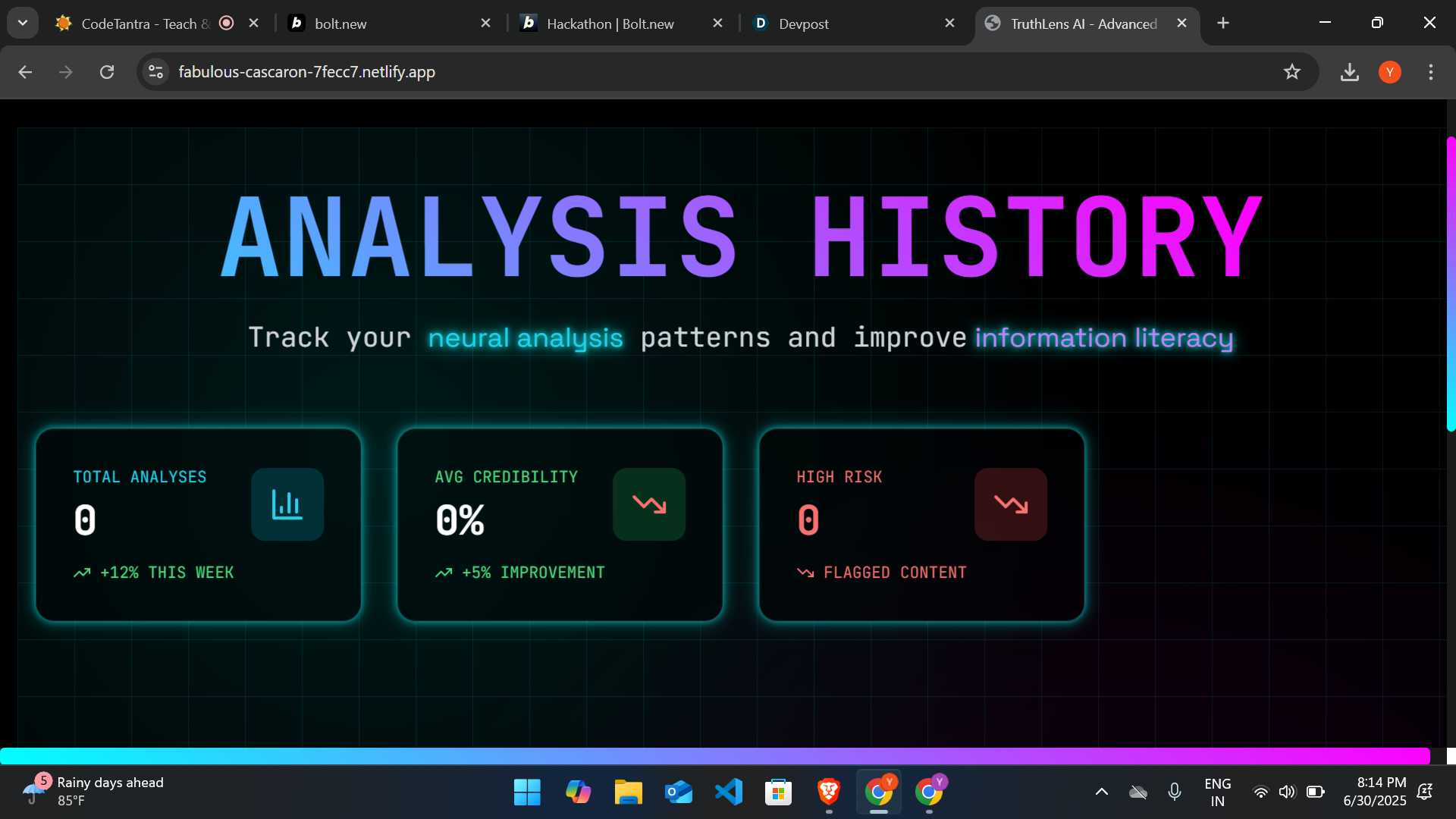
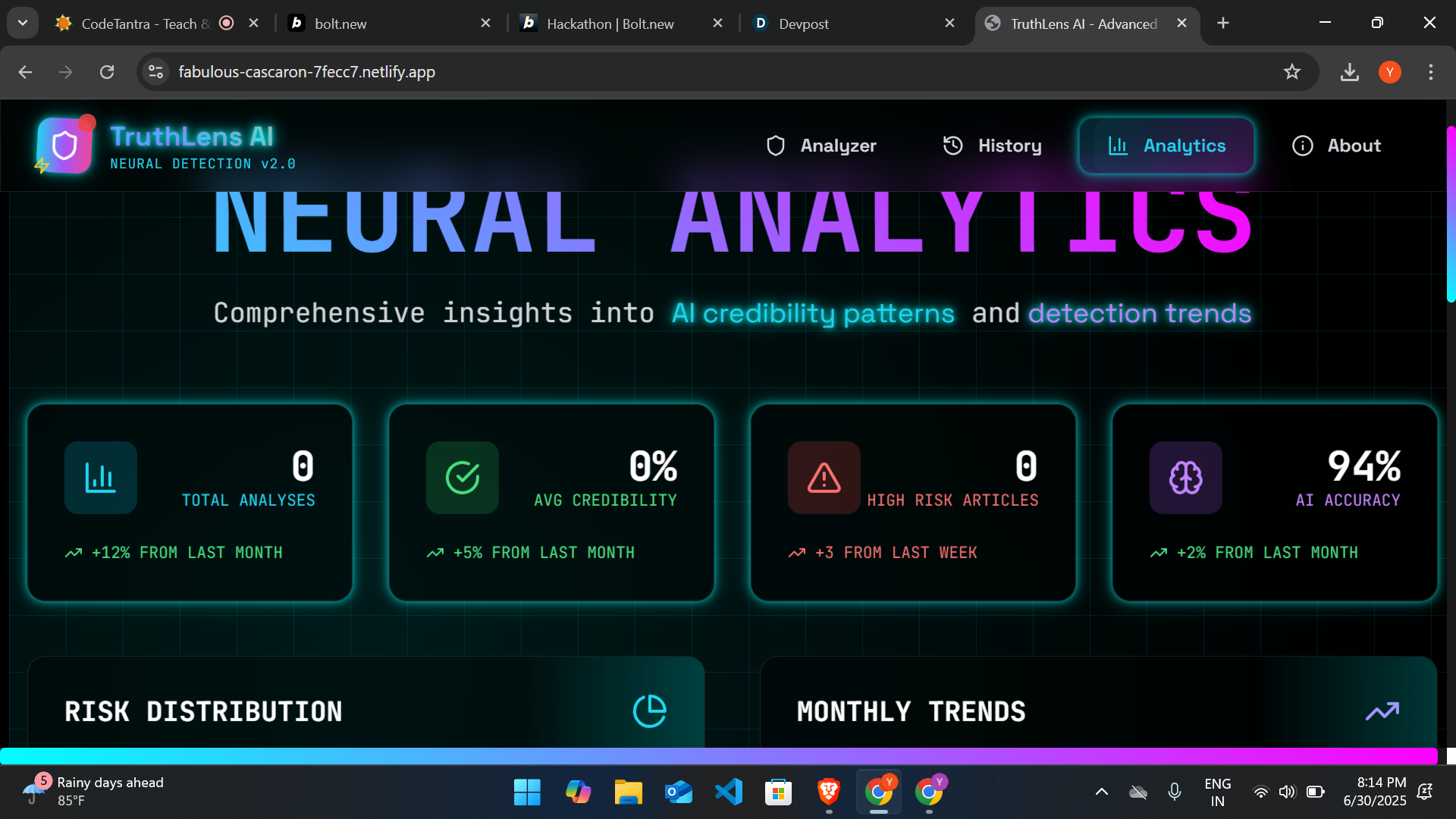
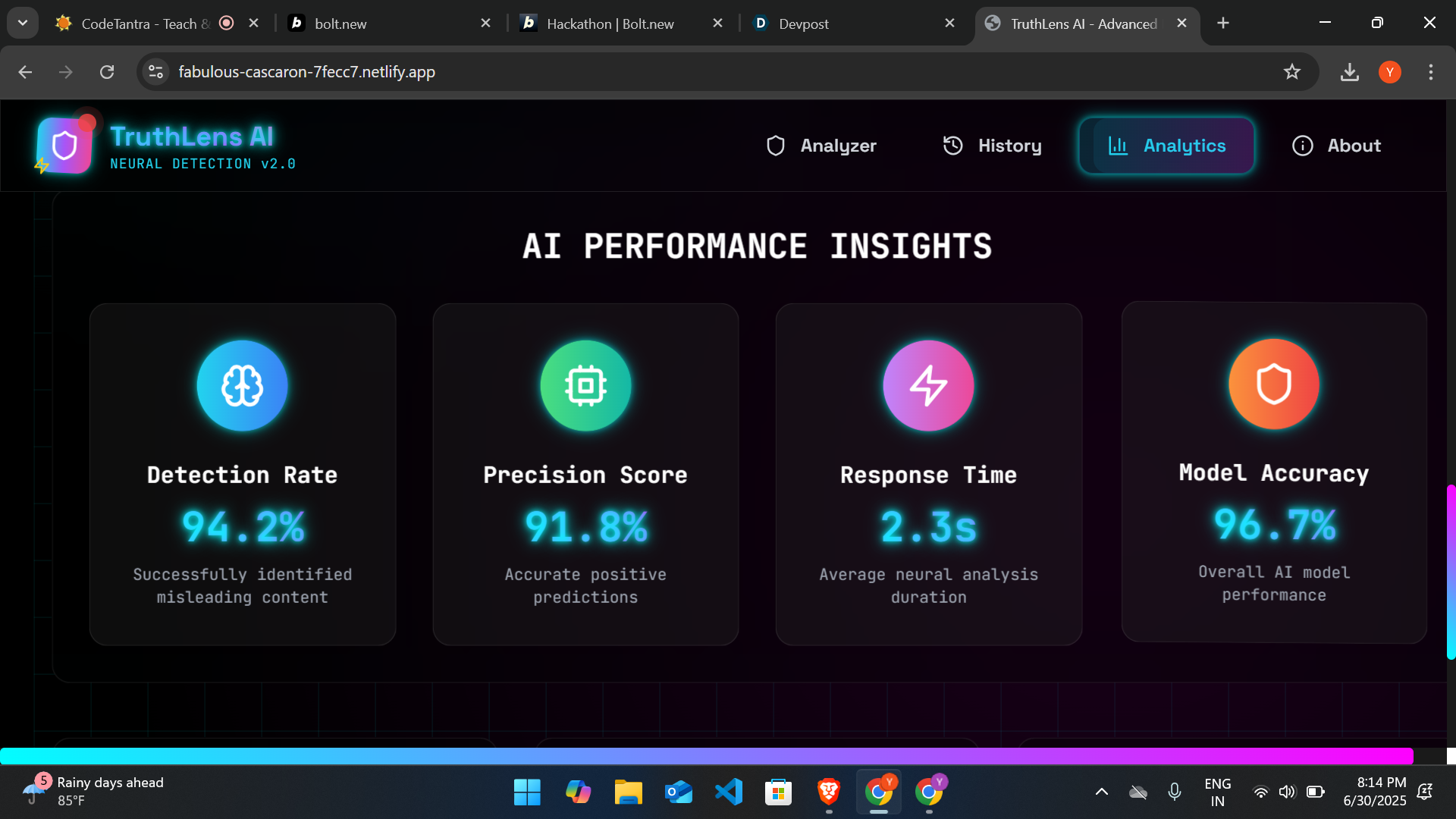
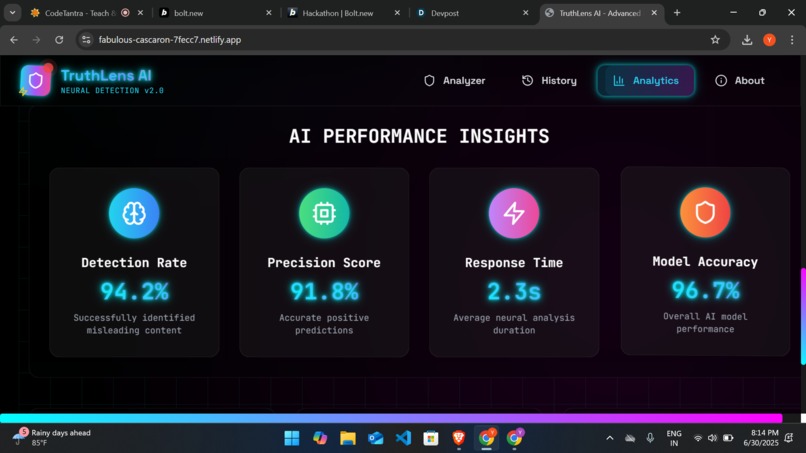
With an era ruled by information overload and instant sharing of content, dissemination of false news is a serious danger to society. This project was conceptualized based on the urgency to fight misinformation through Artificial Intelligence and Natural Language Processing (NLP). The inspiration was derived from actual events where false news made its mark significantly on public views and actions
This system utilizes AI to identify spurious news reports by analyzing their text content. With Python and machine learning libraries like scikit-learn, the system cleans the text data, performs TF-IDF vectorization-based feature extraction, and classifies news into real and fake categories with the help of logistic regression and other models.
The main parts are: Data cleaning and preprocessing Feature extraction (TF-IDF) Model training and testing (Logistic Regression, Naive Bayes, etc.) Streamlit web-based UI for interactive fake news identification
What I Learned:
Effective processing and cleaning of textual data through NLP methods
Practical application of text classification models
Interpretation of model accuracy, precision, recall, and F1-score
Hosting ML models with Streamlit for live user input
Challenges I Faced
Balancing data during training since data is class-imbalanced Preventing overfitting with the limited available data Making sure the model generalizes well on unseen examples Developing a light yet useful user interface
# Sample: Predicting using logistic regression
news = vectorizer.transform(["Breaking news text here"])
prediction = model.predict(news)
Built With
- nltk
- numpy
- python-*-**libraries**:-pandas
- scikit-learn
- streamlit-*-**dataset**:-combined-fake-and-real-news-datasets-*-**model**:-logistic-regression-(best-performing)

Log in or sign up for Devpost to join the conversation.